Claude Fable 5 Review: What Developers Really Think 24 Hours After Launch
A reception roundup of Claude Fable 5 one day after launch: Simon Willison's hands-on verdict, the real coding wins, the cost shock, and the safety-fallback backlash — praise and criticism.

Anthropic shipped Claude Fable 5 on June 9, 2026, and within a day the developer community had put it through enough real work to form a verdict. The short version: when the task is hard — multi-file refactors, long agent runs, frontend from a screenshot — the praise is close to unanimous and occasionally startled. When the task is ordinary, or when the bill arrives, the enthusiasm cools fast. This is a roundup of what people who actually used it are saying, the good and the bad, pulled from hands-on write-ups, Hacker News, and independent testers over the first 24 hours. For the full feature-and-pricing breakdown, see our complete guide to Claude Fable 5; this piece is about reception.

The Headline Reaction: "Something of a Beast"
The most-cited early take came from Simon Willison, who called Fable 5 "something of a beast" that has "been quite happily churning through everything I've thrown at it so far." He ran a now-standard knowledge probe — asking the model to list his own open-source projects — and found Fable "identified even more projects than" Opus 4.8, which he treats as "a reasonably good proxy for model size."
The reaction that traveled furthest on social media came from Jamie Marsland of Automattic, who tried building a WordPress block theme from a screenshot and a URL in a single attempt. His verdict, quoted by Search Engine Journal: "First test: can Fable 5 build a WordPress block theme? One shot. Fully editable. Native WordPress patterns. Yeah… this feels next level."
That phrase — "next level" — captures the optimistic camp. But it is worth noting the pattern underneath it: the loudest praise is almost always tied to a hard, open-ended task, not a chat.
What Developers Are Actually Building With It
The concrete examples are where the reception gets specific enough to be useful.
Willison's standout was a feature for his Datasette Agent project. By his account, Fable "not only [solved that problem], it also identified and then implemented four issues in my underlying LLM library," and he was "really impressed with the quality of API design, tests, code and documentation that Fable put together for this" — work he estimated "feels like several days' worth." Separately, he had Fable bundle MicroPython compiled to WASM, something he said he'd "struggled with for months," and watched it "churn away for a few minutes" until "the entire thing working."
On Hacker News, the anecdotes ran in the same direction. A database-migration developer reported the model "reduced allocs by 46x" and surfaced bugs that competing models had missed. A researcher working on CRDTs praised its ability to derive correct invariants and write verification fuzzers with little hand-holding. One commenter summed up the unsettled mood bluntly: Fable felt "like it's coming for my job" in a way earlier models hadn't.
A hands-on write-up from Clanker Cloud drew the cleanest line through all of this: "ordinary conversation did not feel dramatically different from Opus 4.8, but hard frontend and agentic coding did." Its specifics — "more targeted diffs," "fewer unnecessary code changes," "better maintainability without as much human steering" — match what others reported. Its closing caveat is the one enterprises should underline: "Fable can write better code. It still needs production context."
The Cost Shock
If there is one criticism that shows up in nearly every thread, it is the bill.
Willison spent $110.42 in a single day of testing — overshooting his $100/month subscription in 24 hours. He is not a casual user, and the figure was offered without much alarm, but it set the tone. On Hacker News the numbers got sharper: one developer reported a single code-review prompt that "burned $92 across subagents" without finishing the job, and subscribers on the highest reasoning settings described exhausting their five-hour usage windows "in 8 minutes."
The pricing is $10 per million input tokens and $50 per million output tokens — roughly 2× Opus 4.8 and 3× Sonnet. The more careful analysts pushed back on the naïve read, though. Several pointed out that per-token price is the wrong unit: measured per finished task, Fable can be the cheapest option when its one-shot accuracy avoids a dozen failed cheaper attempts, and 10× more expensive than Sonnet when you point it at routine work it didn't need to do. The consensus that emerged is narrow and sensible: the premium is defensible on hard, high-stakes work and indefensible on high-volume, well-defined tasks where Opus 4.8 or Sonnet already finish the job.
The Safety-Fallback Backlash
The second recurring complaint is the one Anthropic most clearly anticipated — and arguably underestimated. Fable 5 routes requests it flags as cybersecurity, biology, chemistry, or distillation to the weaker Opus 4.8, notifying the user when it does. Anthropic says this fires in under 5% of sessions. The developers tripping the classifiers tell a more frustrated story.
On Hacker News, users reported legitimate work getting blocked: medical imaging, laboratory automation, health-data analysis, even music firmware, all flagged as biosecurity or cybersecurity risks. One developer noticed that simply starting a new session made Fable cooperative again on an identical request — strong evidence the friction is a jumpy classifier, not the model itself. Willison, more measured, still noted the guardrails "trigger often enough that the Claude API has new mechanisms for letting you know when you hit them."
The sharpest critique came from Nathan Lambert, who framed the whole approach as a set of "safety fables." His core objection is about invisible degradation: "An AI model that gets less intelligent automatically without notifying me is categorically misaligned AI." He argues the selective application — transparent filters for cyber and bio, quieter restrictions around AI-research and distillation — reads "far more about maintaining their competitive position" than about safety, and concludes that he "personally cannot trust the best AI model in the world to work in my professional domains building models." Whether or not you accept the competitive-entrenchment framing, it is the most-shared dissent of the launch.
Do the Benchmarks Back Up the Hype?
Anthropic's own numbers are strong — 80.3% on SWE-Bench Pro against Opus 4.8's 69.2%, and a FrontierCode curve that keeps climbing as you spend more on reasoning.
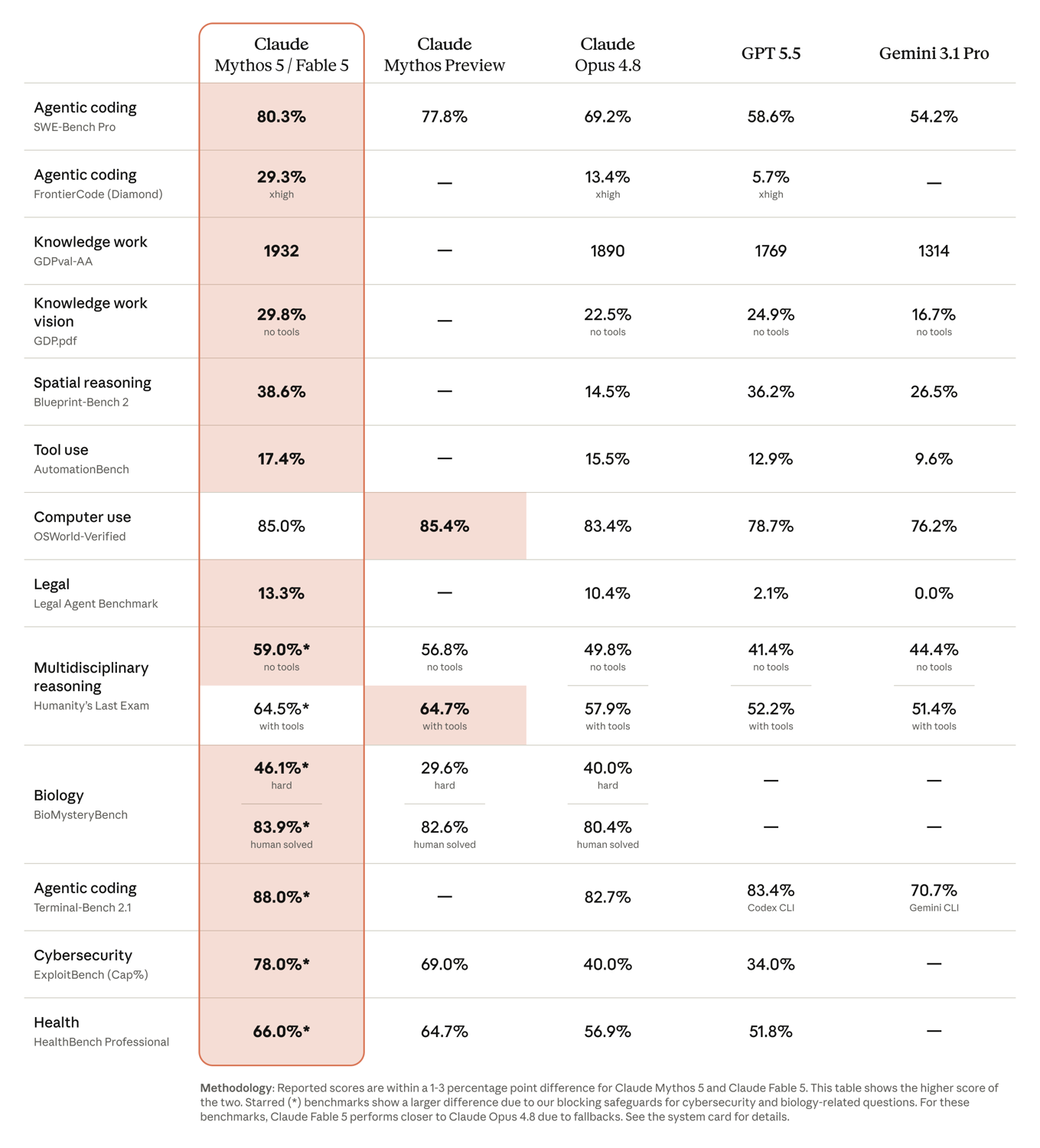
The reception to those numbers was split. The power-user majority treated the benchmarks as confirmation of what they were already feeling in their editors. But a vocal skeptical faction on Hacker News pushed back on the wave of "vibes" reviews — including the hands-on ones above — arguing that qualitative impressions without controlled prompts, logged generations, and repeatable metrics amount to "slop" rather than evidence. The counter-argument, also well represented, was that public benchmarks are increasingly gameable and that gut-feel assessments from trusted practitioners are a legitimate input for tool selection. Both can be true: the benchmarks establish a ceiling, and the anecdotes tell you whether you'll actually reach it on your workload.
How Fable 5 Stacks Up Against GPT-5.5 and Gemini 3.1
One thing the first day clarified is that the comparison developers actually argue about is internal. Against the other frontier labs, Fable 5's published lead on coding is wide enough that it barely generated debate: 80.3% on SWE-Bench Pro versus 58.6% for GPT-5.5 and 54.2% for Gemini 3.1 Pro, with similar gaps on agentic and tool-use benchmarks. Reactions reflected that — the cross-vendor takes mostly amounted to "yes, on hard coding it's clearly ahead right now."
The more contested comparison is Fable 5 against its own cheaper siblings. That is where the reception splits, because the gap there is real but task-dependent: on the routine reasoning and writing that make up most day-to-day usage, multiple testers (the Clanker Cloud write-up among them) said Fable felt close to Opus 4.8, while on hard frontend and long agentic runs the distance was obvious. The practical reading most developers landed on: against rivals, Fable wins the coding crown for now; against Opus 4.8 and Sonnet, it wins only on the hard tasks, and you pay for the privilege.
The Cyber Subplot: A Deliberately Defanged Public Model
Running underneath the developer reaction was a second, more security-flavored conversation. Fable 5 is the neutered twin of Mythos 5 — the same model with its cybersecurity ceiling left intact for vetted defenders and clamped down for everyone else. On the restricted benchmarks, that gap is stark: Mythos-class scores 78.0% on the ExploitBench cybersecurity benchmark against Opus 4.8's 40.0%, which is exactly why the public Fable 5 falls back rather than answering.
The security press treated that capability as the real story. BeInCrypto framed it as "the world's most powerful hacking AI" and warned it "should make DeFi worried," while outlets like The Hacker News led with the cyber-safeguard angle rather than the coding wins. For the security community, the reception was genuinely two-sided: defenders gaining a Mythos-class vulnerability finder through Project Glasswing is a real upgrade, but the same capability existing at all — and being one safeguard layer away from public access — is the part that unsettles people. It is the clearest illustration of why Anthropic split one model into two products in the first place.
Where Enterprises Land
Quietly, the enterprise reception was the most decisive of all — measured in availability rather than tweets. Within hours of launch Fable 5 was live on Amazon Bedrock, Microsoft Foundry, and as a generally available option in GitHub Copilot. Legal-AI company Harvey announced same-day support. That breadth of day-one distribution is its own verdict: the platforms betting their own customers on Fable 5 had clearly tested it before launch and liked what they saw, guardrails and price included.
The enterprise math is also less price-sensitive than the indie-developer math. For a team where an engineer-hour dwarfs a few dollars of tokens, a model that turns "several days of work" into an afternoon is an easy purchase — which is exactly the use case Willison's Datasette anecdote describes.
How to Read Your Own First Week
The reception is useful, but it is other people's workloads. The honest way to decide whether Fable 5 is worth it is to reproduce the launch-week tests on your own, and the early reactions suggest a short, practical checklist:
- Point it at your hardest task, not a chat. Every glowing review came from a long, multi-step, open-ended job. If you evaluate Fable on quick Q&A, you will conclude it is an expensive Opus 4.8 — because on that workload, it roughly is.
- Measure cost per finished task, not per token. The $110-a-day figures look alarming until you ask how many engineer-hours they replaced. Run a real task end to end, count the dollars, and compare against the human time it saved — and against what Opus 4.8 or Sonnet would have cost for the same outcome.
- Watch for the fallback notification. If your domain touches security, biology, chemistry, or anything the classifier reads as adjacent, you will hit the Opus 4.8 fallback. Note how often, because that is your real experience of the model, not the headline benchmark.
- Keep a cheaper model wired in. The cleanest setups that emerged route the hard 10% to Fable and everything else to a cheaper model. Treating Fable as a wholesale replacement is how you end up in the "burned $92 without finishing" camp.
A week of this on your own repository tells you more than any roundup, including this one.
The 24-Hour Verdict
A day is not a full evaluation, but the shape of the reception is already clear, and it sorts into three camps.

- The optimistic majority — power users running hard, agentic, long-horizon work. For them Fable 5 is a genuine step up, occasionally an unsettling one, and worth the price on the tasks that matter.
- The frustrated subset — blocked by over-eager safety classifiers or sticker-shocked by the bill. Their complaints are specific and reproducible, and they are the reason "it depends on your workload" is the honest summary.
- The skeptics — demanding rigorous, controlled measurement before they accept any of it. They are right that the launch ran on vibes, and right that vibes are not nothing.
If you take one thing from the first 24 hours, take this: Claude Fable 5 is not a model you switch to wholesale. It is one you reach for deliberately, on the hardest 10% of your work, while keeping a cheaper model on everything else. The reception is enthusiastic precisely because it is conditional.
What Fable 5's Reception Means for AI Slide Generation
The single most consistent theme in Fable 5's reviews — strong on long, complex, multi-step work; overkill on routine tasks — maps almost exactly onto how a serious document-to-slide pipeline should think about model selection. Turning a sixty-page research paper or a dense financial filing into a coherent deck is precisely the kind of long-horizon, structure-heavy reasoning where reviewers say Fable pulls ahead: it has to hold the whole source in context, decide what earns a slide, and preserve the argument without inventing numbers. That is the same capability Willison praised when Fable "feels like several days' worth of work" — applied to slides instead of code. We wrote about why that grounding matters most in our zero-hallucination AI slides guide.
But the cost-per-task lesson from Fable's reception applies just as directly to AI slide generation. You do not want a frontier model regenerating every routine bullet; you want it on the hard structure-extraction step and a cheaper model on the rest. That is exactly how Tosea.ai routes its document-to-PPT pipeline — reserving the strongest reasoning for the outline-and-structure pass on genuinely complex inputs, where the premium pays for itself, and keeping the per-deck economics sane everywhere else. For worked examples, see our research-paper-to-slides workflow and our walkthrough on converting PDFs to PowerPoint slides. The reviewers' verdict on Fable 5 — reach for the frontier model deliberately, not by default — is the right instinct for presentation workflows too.
Sources
- Initial impressions of Claude Fable 5 — Simon Willison, June 9, 2026
- Claude Fable 5 "Feels Next Level" — Search Engine Journal
- Claude Fable 5 and new safety fables — Nathan Lambert, Interconnects
- Claude Fable 5 — launch discussion — Hacker News
- Claude Fable 5 Coding and Design Impressions — Clanker Cloud
- Claude Fable 5 and Claude Mythos 5 — Anthropic, June 9, 2026
- Anthropic Releases Claude Fable 5, Its Most Powerful AI Yet, With Cyber Safeguards — The Hacker News
- Claude Fable 5: The World's Most Powerful Hacking AI Should Make DeFi Worried — BeInCrypto
- Anthropic Fable 5 now available in Harvey — Harvey


