How to Use Claude Fable 5: Complete Guide to Anthropic's First Public Mythos-Class Model
A practical guide to Claude Fable 5 — Anthropic's June 2026 release and first public Mythos-class model: 80.3% SWE-Bench Pro, automatic Opus 4.8 safety fallbacks, and what it means for slides.

On June 9, 2026, Anthropic released Claude Fable 5 — the first publicly available model from its Mythos family, the same line that spent two months behind a vetted-access wall because its capabilities worried both the company and the US government. Fable 5 is available immediately on the Claude API, on Amazon Bedrock, and as a generally available option in GitHub Copilot, and it is the most capable model Anthropic has ever shipped to the general public. Pricing is $10 per million input tokens and $50 per million output tokens — double the rate of Claude Opus 4.8, and the steepest list price in the Claude lineup.

What makes this launch unusual is not just the benchmark jump. Fable 5 ships with a hard safety layer that refuses to run at full strength on a defined set of high-risk topics, quietly handing those requests to the smaller Opus 4.8 instead. This guide breaks down what Fable 5 actually does, how it differs from its restricted sibling Mythos 5, which benchmark claims are Anthropic's own and which come from named partners, what the safeguards mean in day-to-day use, and what the release signals for anyone who turns dense technical work into presentations. If your workflow ends in a deck, you can pair Fable 5's reasoning with Tosea.ai to turn long source documents into slides without rebuilding them by hand.
What Is Claude Fable 5?
Claude Fable 5 is a frontier large language model and the public face of Anthropic's Mythos-class architecture. "Mythos-class" is the internal designation for Anthropic's most capable family — models strong enough at autonomous coding and vulnerability discovery that the company restricted them to approved partners through a program called Project Glasswing. Fable 5 is the version Anthropic judged "safe for general use" once it had built classifiers to fence off the riskiest behavior.
In plain terms: Fable 5 is what you get when Anthropic takes its strongest model and bolts on guardrails aggressive enough to release it to anyone with a paid plan. Anthropic describes it as state-of-the-art across nearly every benchmark it reports, with "exceptional performance in software engineering, knowledge work, vision, and scientific research." The pattern it emphasizes repeatedly: the longer and more complex the task, the larger Fable 5's lead over rival models grows. That is a different selling point from the usual "+3 points on a benchmark" — it is a claim about sustained, multi-step work.
Fable 5 vs Mythos 5: Two Models From One Family
The launch is actually two models, and conflating them is the easiest mistake to make.
Claude Fable 5 is the public model. Anyone on a Pro, Max, Team, or Enterprise plan can use it, and it carries the full safety layer described below.
Claude Mythos 5 is the restricted model. It runs with the cyber safeguards lifted, and Anthropic deploys it only to vetted cyberdefenders, infrastructure providers, and select biology researchers through Project Glasswing. It is the same underlying capability without the brakes.
Anthropic's own benchmark table lists the two together because, on most tasks, they score within one to three percentage points of each other. The gap only widens on a specific cluster — cybersecurity and biology — where Fable 5's safeguards kick in and pull its effective score down toward Opus 4.8's. So when you see an 80%+ cybersecurity number attributed to "Mythos 5 / Fable 5," read it carefully: that ceiling belongs to Mythos 5. The public Fable 5 you can actually call will fall back well below it on those exact questions, by design.
Benchmarks: Where Fable 5 Actually Pulls Ahead
Anthropic published a head-to-head table against Opus 4.8, GPT-5.5, and Gemini 3.1 Pro. The standout is agentic coding, where Fable 5's lead is large rather than marginal.
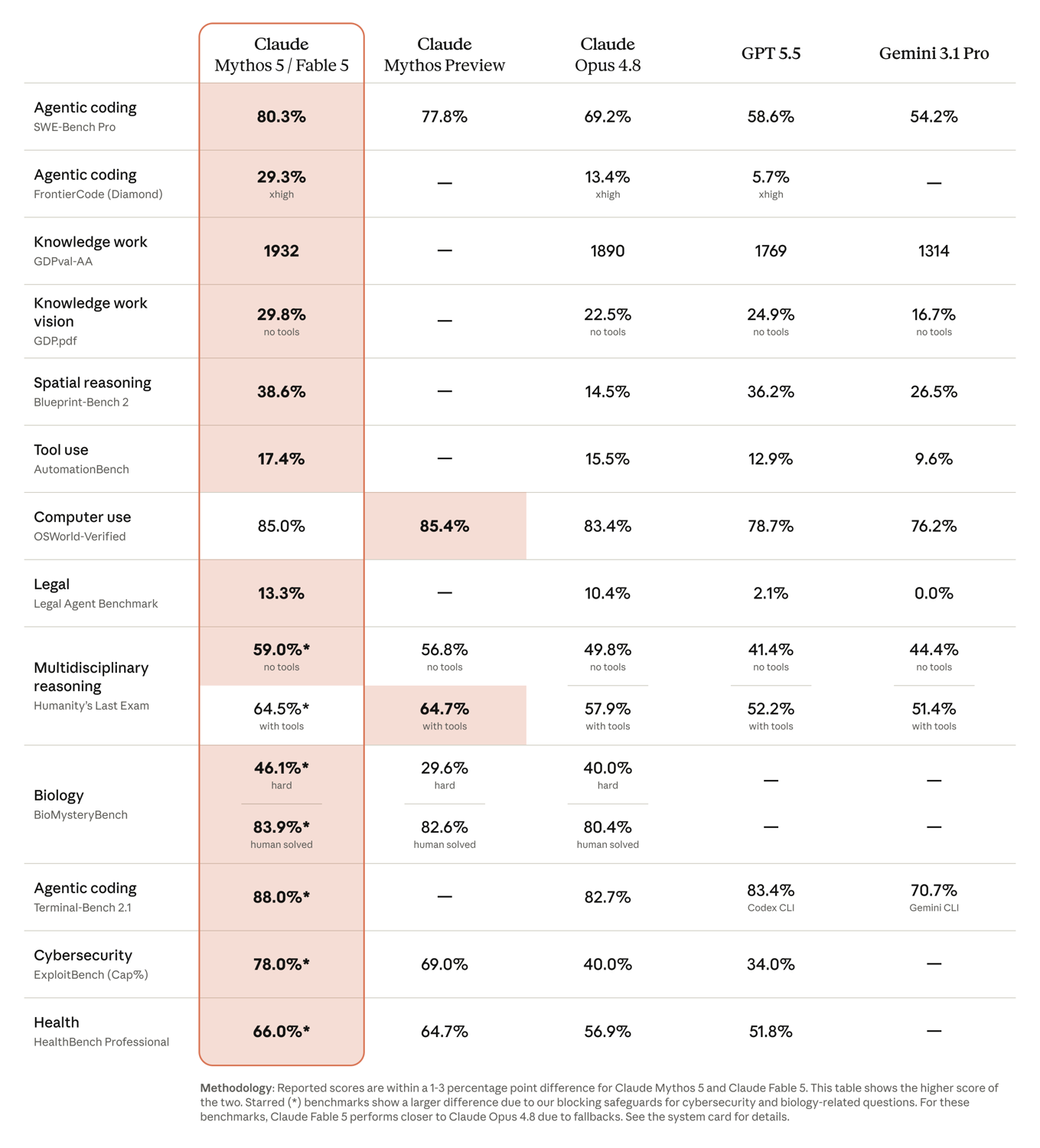
Here are the cleanest, clearly-labeled rows from that table:
| Benchmark | Capability | Mythos 5 / Fable 5 | Opus 4.8 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|---|
| SWE-Bench Pro | Agentic coding | 80.3% | 69.2% | 58.6% | 54.2% |
| Terminal Bench 2.1 | Agentic coding | 88.0%* | 82.7% | 83.4% | 70.7% |
| FrontierCode (Diamond) | Hardest coding | 29.3% | 13.4% | 5.7% | — |
| OSWorld Verified | Computer use | 85.0% | 83.4% | 78.7% | 76.2% |
| Blueprint Bench 2 | Spatial reasoning | 38.6% | 14.5% | 36.2% | 26.5% |
| Humanity's Last Exam (no tools) | Reasoning | 59.0% | 49.8% | 41.4% | 44.4% |
| ExploitBench (Cap@75) | Cybersecurity | 78.0%* | 40.0% | 34.0% | — |
| HealthBench Professional | Health | 66.0%* | 56.9% | 51.8% | — |
The asterisked rows (Terminal Bench, ExploitBench, HealthBench) are the ones where Anthropic notes a larger Fable-versus-Mythos gap because the public model's blocking safeguards trigger. On those, Fable 5 performs closer to Opus 4.8 than the headline number suggests. The unstarred rows — SWE-Bench Pro at 80.3%, FrontierCode at 29.3%, spatial reasoning at 38.6% — are gains the public model keeps.
The numbers that matter for engineering teams
The single most striking figure is SWE-Bench Pro at 80.3%, more than ten points above Opus 4.8's 69.2% and over twenty points above both GPT-5.5 and Gemini 3.1 Pro. SWE-Bench Pro measures whether a model can resolve real GitHub issues end to end, so a jump of this size is the difference between "useful assistant" and "can close tickets unattended."
FrontierCode is worth a second look because it exposes how Fable 5 wins: by spending more and reasoning longer.
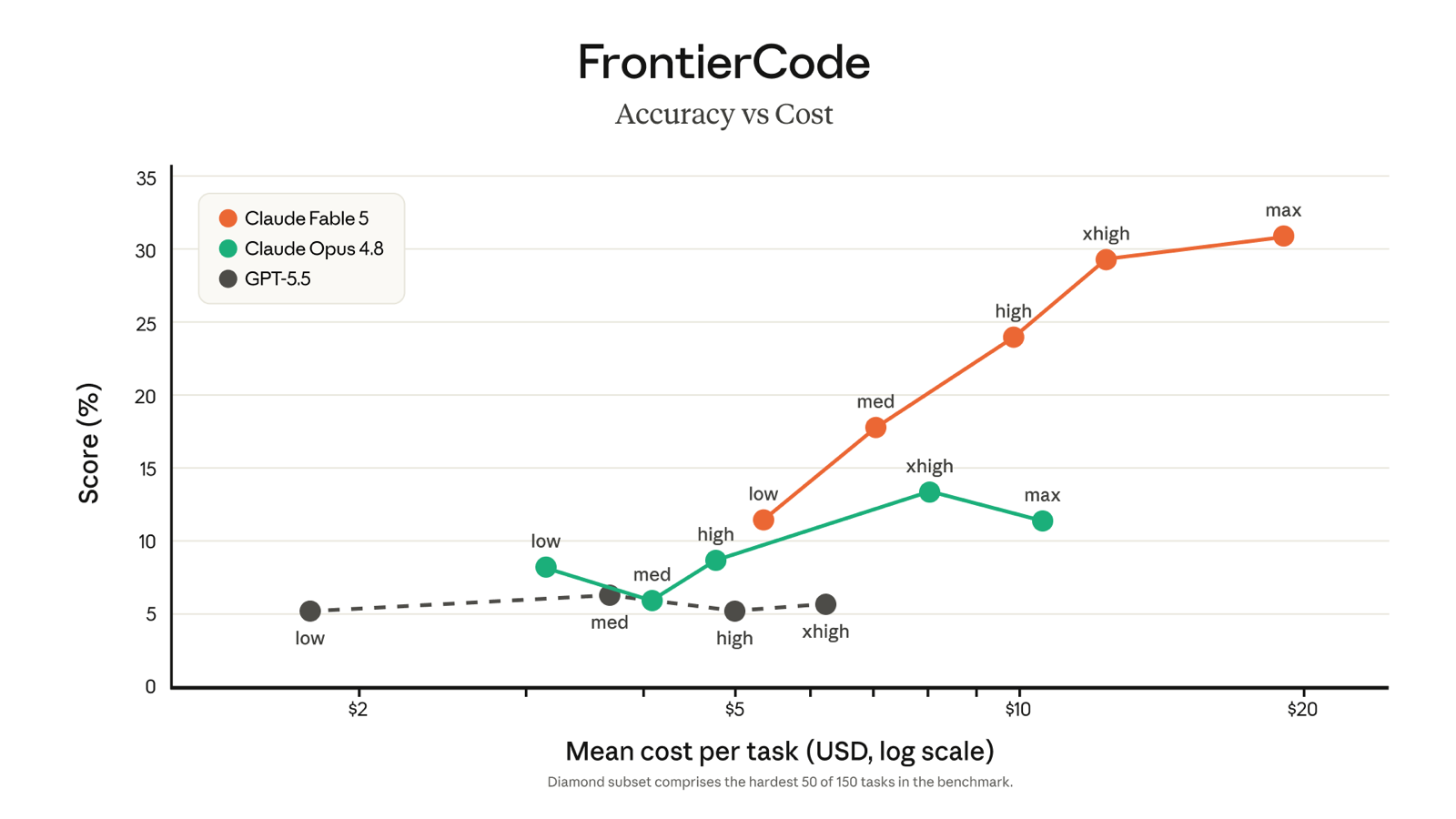
On this hardest 50-of-150 subset, Fable 5 climbs from about 11% at low effort to roughly 31% at maximum effort, while Opus 4.8 plateaus near 13% and GPT-5.5 stays flat around 5–6%. The takeaway: Fable 5 converts extra compute into real accuracy on hard problems in a way the other models do not. That is also why it is expensive — you are paying for a model designed to keep working a problem longer.
What partners report from production
Anthropic's launch leans on named-partner results rather than internal-only numbers, which is the more credible kind of evidence:
- Stripe reported that Fable 5 "compressed months of engineering into days," completing a 50-million-line Ruby codebase migration in roughly one day — work the team estimated at two months by hand.
- Hex said Fable 5 was the first model to clear 90% on its core analytics benchmark for complex analytical tasks.
- Hebbia recorded the highest score of any model it has tested on its finance benchmark.
- On vision, Fable 5 completed Pokémon FireRed using vision alone — a milestone Anthropic uses as a stand-in for long-horizon visual reasoning.
Single data points, not controlled studies — but specific, attributed, and falsifiable, which is the right kind of claim to take seriously.
The Safety Architecture: Why Fable 5 Sometimes Answers as Opus 4.8
This is the part of Fable 5 that most changes how it feels to use. The model does not simply refuse risky prompts. Instead, classifiers watch each request, and when they detect a high-risk topic, the system silently routes that turn to Claude Opus 4.8 and notifies you that a fallback occurred. Three domains are fenced:
- Cybersecurity — exploitation, offensive cyber tasks, and progress on cyber evaluations are blocked.
- Biology and chemistry — most requests in these domains are covered, aimed at preventing misuse in areas like virus design.
- Distillation — attempts to extract Fable 5's capabilities to train another model are blocked.
Anthropic's framing is that this should be invisible to almost everyone: the safeguards trigger in fewer than 5% of sessions on average, meaning more than 95% of Fable 5 sessions run entirely on Fable 5. For a normal coding, analysis, or writing workflow you will likely never see a fallback. If you work in security research or computational biology, you will — and you should expect Opus-4.8-level answers on exactly those questions.
On robustness, Anthropic ran an external bug bounty that logged more than 1,000 hours of testing and produced no universal jailbreaks, though it notes the UK AI Safety Institute made early progress toward one. There is also a notable data-handling change: Anthropic now requires 30-day retention on all Mythos-class traffic, including for enterprises that previously held zero-retention agreements. It says the data is used only to defend against novel attacks and jailbreaks — not for model training — and is deleted after 30 days in nearly all cases. If your organization has strict data-residency commitments, this is the clause to read before adopting Fable 5.
Pricing and How to Get Access
Fable 5 lists at $10 per million input tokens and $50 per million output tokens — twice Opus 4.8's $5 / $25, though Anthropic notes it is less than half the price of the earlier Mythos Preview. Access splits by surface:
- Claude API — available immediately at the list price above.
- Claude.ai subscriptions — from June 9 through June 22, Fable 5 is included at no extra cost on Pro, Max, Team, and seat-based Enterprise plans. On June 23, Anthropic pulls it from those plans, and continued use requires usage credits. The company says it aims to restore Fable 5 as a standard subscription feature "as quickly as we can."
- Amazon Bedrock and GitHub Copilot — available now for teams that consume Claude through those platforms.
The practical implication: if you want to evaluate Fable 5 on real work, the two-week free window on paid plans is the cheapest time to do it. Run your hardest, most representative tasks before June 23 and measure both quality and token cost, because at $50 per million output tokens the economics only make sense where the extra accuracy actually pays for itself.
Fable 5 or Opus 4.8? A Practical Default
At twice the price, Fable 5 is not an automatic upgrade for every workload, and the honest answer for most teams is to keep Opus 4.8 as the default and reach for Fable 5 deliberately. The deciding question is task length and difficulty, because that is precisely where Fable 5's advantage compounds rather than staying flat.
Reach for Fable 5 when the task is long-horizon or genuinely hard: a repo-scale migration, a multi-file refactor with a trustworthy test suite, an overnight agent loop, or a dense analytical job where being wrong is expensive. The FrontierCode curve is the clearest evidence — on the hardest problems, the accuracy you buy with extra effort keeps climbing, so the higher per-token price converts into fewer failed runs and less human cleanup.
Stay on Opus 4.8 for the broad middle: routine coding, drafting, summarization, everyday analysis, and anything latency- or budget-sensitive. On these tasks the two models are close enough that paying double rarely pays back, and Opus 4.8's 3x-cheaper fast mode tilts the math further. There is also a quiet operational point — because Fable 5 silently falls back to Opus 4.8 on cyber and bio questions, a security or life-sciences team that needs full capability is better served calling Opus 4.8 directly (or applying for Mythos 5) than paying Fable 5 rates for answers it will quietly downgrade anyway.
The cheapest way to settle this for your own stack is to use the June 9–22 free window: run the same representative task through both models, compare output quality and total token cost, and let the numbers pick the default.
Longer Autonomy and File-Based Memory
The capability Anthropic stresses most is duration. Fable 5 and Mythos 5 "can work autonomously for longer than any previous Claude models," and the supporting examples are deliberately long-horizon:
- Given file-based memory, Mythos 5's performance on the game Slay the Spire improved three times more than Opus 4.8's — a proxy for how well the model uses external scratchpads to sustain a strategy across many steps.
- In life-sciences work, Mythos 5 ran autonomously over the course of a week to assemble single-cell data for millions of cells across 138 species.
The throughline connects directly to the FrontierCode curve: Fable 5 is built to be left running. That is what justifies the price and the autonomy framing, and it is the same property that makes self-improving and long-horizon agents a live topic — a thread we picked up in our guide to self-improving AI agents. For teams running unattended agent loops, a model that holds a plan together over hundreds of steps changes the risk-and-reward math of leaving it alone overnight.
Project Glasswing, Mythos 5, and the Life-Sciences Push
Alongside the public Fable 5, Anthropic shipped Mythos 5 to its Project Glasswing partners — the cyberdefenders and infrastructure providers cleared to run the model with cyber safeguards lifted. Glasswing has expanded to roughly 150 new organizations across more than fifteen countries, and existing partners can upgrade from Mythos Preview to Mythos 5 at a lower cost.
The scientific results Anthropic highlights come from this restricted track. Mythos 5 reportedly accelerated protein design in a way that could speed certain drug-development steps by about 10x, and its molecular-biology hypotheses were preferred roughly 80% of the time in blind comparisons against Opus-class models. These are the capabilities that justify keeping Mythos 5 gated: the same biological reasoning that helps design therapeutics is what the Fable 5 safeguards are built to fence off for the general public.
The Backdrop: A "Brake Pedal" Warning, Then the Most Powerful Public Model
The timing is hard to ignore. Days before this launch, Anthropic publicly urged frontier labs to agree on "a coordinated brake pedal on frontier AI development," warning that systems may be approaching recursive self-improvement — the point at which a model can meaningfully improve itself without human intervention. Then it shipped the most capable model it has ever made publicly available.
Anthropic's resolution of that tension is the safeguard layer itself: the argument is that the responsible way to release Mythos-class capability is to release the fenced version, keep the unfenced one inside Project Glasswing, and require retention data to harden the fences over time. Whether that satisfies critics is a separate question, but it is a coherent position, and it follows the same playbook as the Opus 4.8 cycle, where a point release doubled as a deployment vehicle for safeguards headed into the next, larger family.
Who Should Care About Fable 5 Right Now
Engineering teams with hard, autonomous coding work. The SWE-Bench Pro and FrontierCode gains are large enough to justify a migration pilot — especially for long-running jobs where Fable 5's effort-scaling pays off. Start with one bounded task where your test suite is trustworthy, and measure cost as carefully as quality.
Teams running long, unattended agent loops. The autonomy and memory improvements matter most where no human reviews every step. If you already lean on overnight agent runs, Fable 5 is the model to benchmark.
Security and life-sciences researchers. Know that the public Fable 5 will fall back to Opus 4.8 on exactly your domain. If you need full capability, the path is Project Glasswing and Mythos 5, not the public API.
Teams that turn technical work into communication artifacts. Once Fable 5 has done the engineering or research, someone still has to present it. That handoff — from a migration plan, a benchmark report, or a research write-up to a deck a stakeholder can read — is where Tosea.ai fits, and where the next section goes deeper. For the broader category, see our 2026 buyer's guide to AI presentation makers.
What Fable 5 Means for AI Slide Generation
The qualities that make Fable 5 a better coding and research model translate almost directly into better AI slide generation. The hard part of turning a document into a deck has never been writing a sentence — it is reading a sixty-page source, holding its full argument in memory, identifying the three points that actually carry the story, and producing a slide structure that preserves the source's reasoning without inventing numbers or citations. Fable 5's long-horizon coherence and its emphasis on sustained multi-step work map onto exactly that job: a model that keeps a complex argument intact across many steps is a better engine for grounded outline generation, and a better defense against the fabricated chart labels we documented in our zero-hallucination AI slides guide.
For a document-to-PPT workflow running against research papers, financial filings, or product specs, the practical effect shows up in three places: cleaner outline generation across multi-document inputs, fewer hallucinated figures when the source is dense, and better preservation of structure when the input is genuinely complex. The autonomy story points further out, too — the same "leave it running" property that lets Fable 5 migrate a 50-million-line codebase is what makes it plausible to assemble a 200-slide deck from an entire repository of source documents, the scaling logic we explored in how to build a massive slide deck with AI.
At Tosea.ai, the document-to-PPT pipeline routes between several frontier models depending on the task, using the strongest available model for the structure-and-reasoning step on dense academic and consulting inputs — the step where Fable 5's gains land most directly. If you already run a PDF-to-PowerPoint workflow that struggles on long-form sources, a higher-reasoning backend is one of the simplest single upgrades to try. For worked examples end to end, see our research-paper-to-slides workflow and our walkthrough on converting PDFs to PowerPoint slides.
Sources
- Claude Fable 5 and Claude Mythos 5 — Anthropic, June 9, 2026
- Anthropic releases Claude Fable 5, its most powerful model publicly, days after warning AI is getting too dangerous — TechCrunch
- Anthropic releases Mythos-like AI model to the public, Claude Fable 5 — CNBC
- Anthropic releases its first Mythos-class model to the public — Fortune
- Claude Fable 5 from Anthropic now available on Amazon Bedrock — Amazon
- Claude Fable 5 is generally available for GitHub Copilot — GitHub Changelog
- Anthropic Launches Claude Fable 5, Its First Public Mythos-Class Model — MacRumors


