How to Use Claude Opus 4.8: Complete Guide to Anthropic's Coding and Honesty Upgrade
A practical review of Claude Opus 4.8 — Anthropic's May 2026 release with 69.2% SWE-bench Pro, 4x fewer unflagged code flaws, a 3x-cheaper fast mode, and the new Dynamic Workflows.

On May 28, 2026, Anthropic released Claude Opus 4.8 — just 41 days after Opus 4.7, the shortest gap between Opus point releases to date. The model is available immediately across claude.ai, Claude Code, the Claude API, Amazon Bedrock, Google Cloud Vertex AI, Microsoft Foundry, and Anthropic's new Cowork surface. Standard pricing is unchanged at $5 per million input tokens and $25 per million output tokens, the same rate Opus 4.7 and 4.6 carried.

What changed is the emphasis. Where Opus 4.7 was framed almost entirely as a coding jump, Opus 4.8 pairs another coding gain with two things Anthropic clearly wants in the headline: a measurable improvement in honesty — the model is roughly four times less likely to let flaws in its own code pass without flagging them — and a new agentic primitive called Dynamic Workflows that lets Claude Code coordinate hundreds of subagents on a single large job. This guide breaks down what actually moved, which claims are independently corroborated and which are Anthropic's own internal evaluations, and what it means for anyone whose workflow depends on Claude for coding, research, or document-heavy work. If you already run Claude Code, you can pair it with Tosea.ai to turn the technical output — migration plans, architecture docs, benchmark reports — into decks for non-engineering stakeholders in a few minutes.
What Is Claude Opus 4.8?
Claude Opus 4.8 is the latest frontier model in Anthropic's Claude 4 family, positioned as a direct replacement for Opus 4.7 across every surface where Anthropic ships models. Developers call it via the identifier claude-opus-4-8 in the Claude API, and it is already the default in Claude Code — our Claude Code complete guide covers the surrounding tooling in depth.
Four things distinguish Opus 4.8 from its predecessor:
- Another step up in agentic coding. SWE-bench Pro climbs from 64.3% to 69.2%, and SWE-bench Verified moves from 87.6% to 88.6%. The model also follows tool-use instructions more consistently across long autonomous runs.
- A focus on honesty. Anthropic reports Opus 4.8 is about four times less likely than Opus 4.7 to allow flaws in code it writes to go unremarked, and roughly 17 times less likely than Sonnet 4.6 to produce a dishonest summary of its own agentic work.
- Dynamic Workflows. A research-preview feature in Claude Code that spins up hundreds of parallel subagents under a single orchestrator — built for codebase-scale jobs that no single context window could hold.
- A cheaper fast mode. Opus 4.8's fast mode runs at roughly 2.5x the normal output speed for $10 / $50 per million tokens — three times cheaper than the $30 / $150 fast mode on previous Claude models.
The release ships alongside user-facing effort controls on claude.ai and a few API changes worth planning for, covered below. For broader context on Anthropic's expanding product surface, see our analysis of Claude plugins and professional document transformation.
How Opus 4.8 Performs on Coding and Agentic Benchmarks
Anthropic's headline comparison table puts Opus 4.8 against Opus 4.7, OpenAI's GPT-5.5, and Google's Gemini 3.1 Pro across the evaluations it considers most representative of real agentic work.
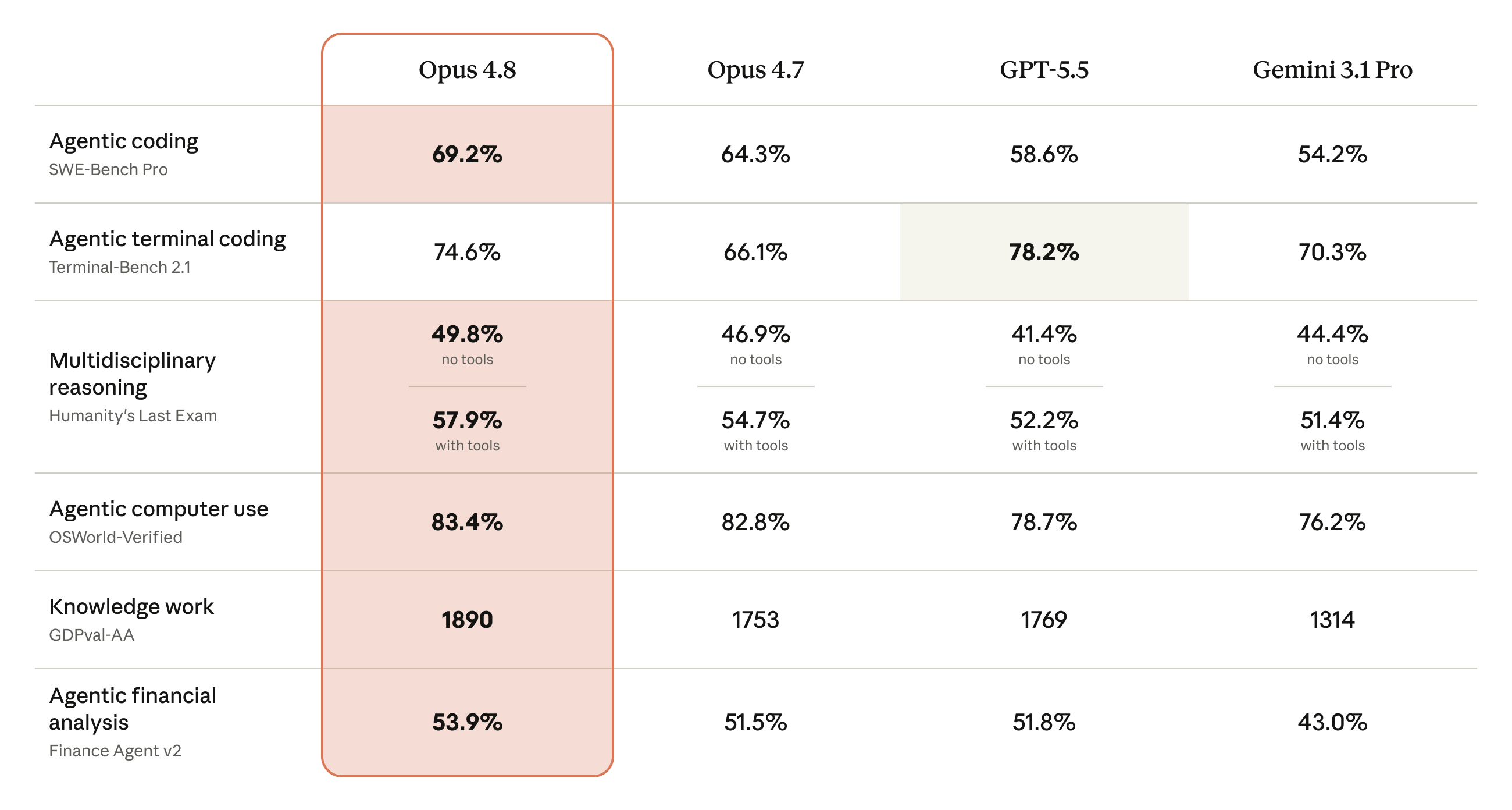
The numbers that matter for engineering teams
| Benchmark | Opus 4.8 | Opus 4.7 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| Agentic coding — SWE-bench Pro | 69.2% | 64.3% | 58.6% | 54.2% |
| Agentic terminal coding — Terminal-Bench 2.1 | 74.6% | 66.1% | 78.2% | 70.3% |
| Multidisciplinary reasoning — HLE (no tools) | 49.8% | 46.9% | 41.4% | 44.4% |
| Multidisciplinary reasoning — HLE (with tools) | 57.9% | 54.7% | 52.2% | 51.4% |
| Agentic computer use — OSWorld-Verified | 83.4% | 82.8% | 78.7% | 76.2% |
| Knowledge work — GDPval-AA (Elo) | 1890 | 1753 | 1769 | 1314 |
| Agentic financial analysis — Finance Agent v2 | 53.9% | 51.5% | 51.8% | 43.0% |
A few honest caveats are worth pulling out, because they matter for a real buying decision. The SWE-bench Pro move (+4.9 points over Opus 4.7) is the standout coding gain, and Opus 4.8 leads every column except one: GPT-5.5 still wins agentic terminal coding on Terminal-Bench 2.1, 78.2% to 74.6%. SWE-bench Verified, reported separately, edges up to 88.6% from 87.6% — a small move at a level where the benchmark is starting to saturate. And on graduate-level reasoning, GPQA Diamond actually slipped slightly, to 93.6% from Opus 4.7's 94.2%. Anthropic does report a new 96.7% on USAMO 2026 and gains on web research (BrowseComp rises to 84.3% single-agent), but the overall picture is "broadly ahead, not ahead everywhere." For a head-to-head on the competing flagships, see our GPT-5.5 complete guide and our Gemini 3.5 Flash guide.
What partners report from production
Benchmarks tend to overstate real-world gains, so the early-access partner statements in Anthropic's launch note are worth reading. Several are specific enough to triangulate:
- Cursor (Michael Truell, co-founder and CEO): tool calling is meaningfully more efficient, completing end-to-end tasks in fewer steps for the same intelligence.
- Cognition (Scott Wu, CEO), maker of Devin: Opus 4.8 uses tools cleanly and follows instructions with enough consistency to keep autonomous engineering workloads running unattended.
- Harvey (Niko Grupen, Head of Applied Research): the highest score the legal-AI firm has recorded on its Legal Agent Benchmark, and the first model to clear 10% on its strictest all-pass standard.
- Databricks (Hanlin Tang, CTO of Neural Networks): a step change in agentic reasoning at roughly 61% lower token cost than Opus 4.7.
The Databricks token-cost figure is the most consequential for production economics: a meaningful capability gain that also reduces spend is rare in a point release. Several other testers — across investment research, retrieval, and computer-use products — describe the same pattern of cleaner tool use and better signal-to-noise, with one reporting 84% on the Online-Mind2Web computer-use benchmark.
The Honesty Upgrade: Fewer Unflagged Code Flaws
The most distinctive part of this release is not a capability number — it is a behavior change. Anthropic spent much of the Opus 4.8 announcement on honesty: the model's tendency to admit uncertainty, flag problems in its own output, and avoid overstating what it accomplished.
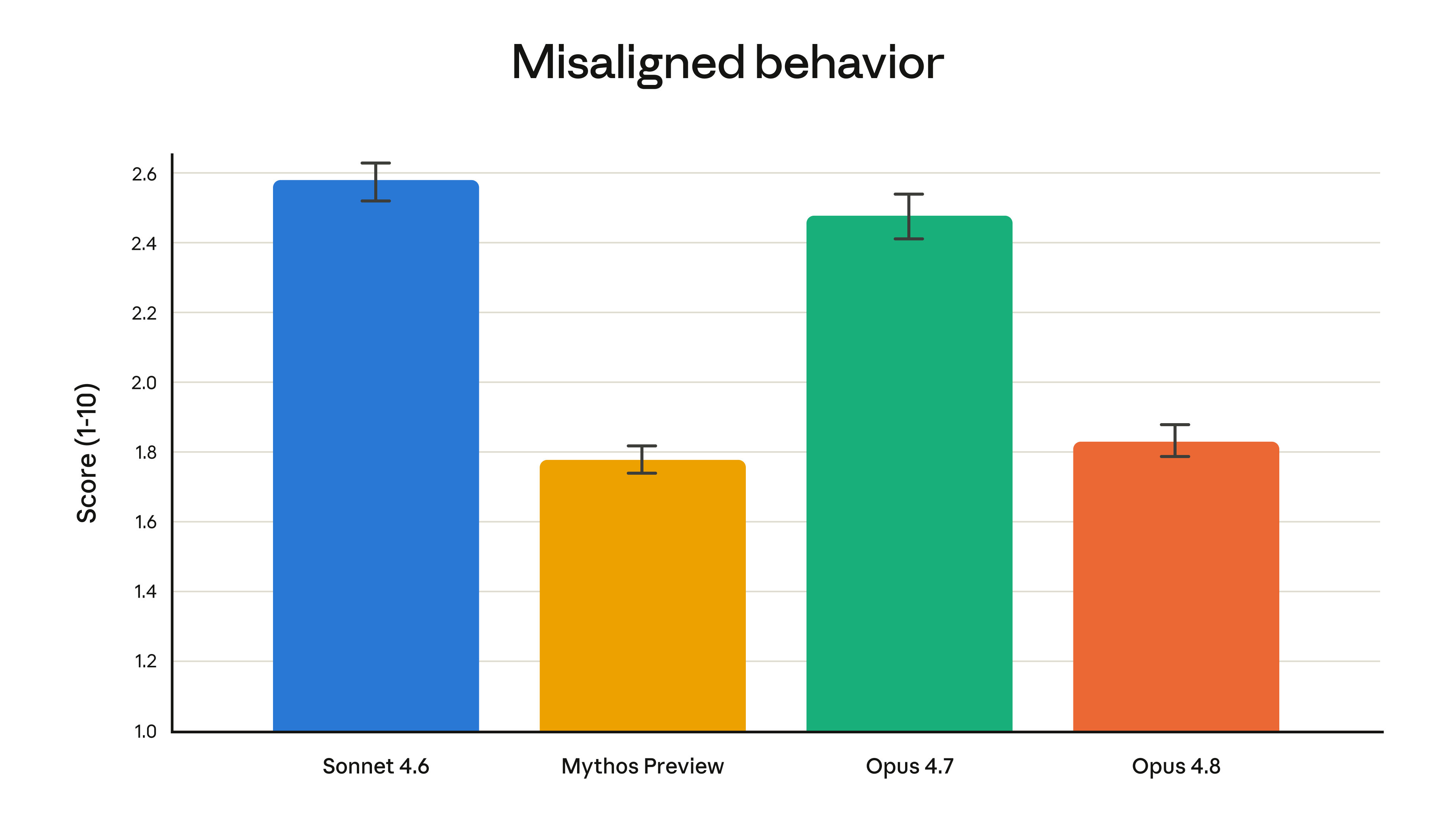
On Anthropic's internal misaligned-behavior evaluation (scored 1–10, where lower is better), Opus 4.8 lands close to Claude Mythos Preview — the still-unreleased model Anthropic describes as the best-aligned it has trained — and well below both Opus 4.7 and Sonnet 4.6. In practical terms, Anthropic reports the model is roughly four times less likely than Opus 4.7 to let flaws in its own code pass unremarked, and about 17 times less likely than Sonnet 4.6 to produce a dishonest summary of its agentic work. The alignment assessment also notes new highs on prosocial traits such as supporting user autonomy.
Two things are worth keeping in perspective. First, these are rate reductions, not eliminations — a model four times less likely to hide a flaw still occasionally hides one, so human review of agentic code does not go away. Second, the honesty metrics come from Anthropic's own evaluations rather than third-party benchmarks, so they should be read as the vendor's framing until independent testing catches up. Even with those caveats, the direction matters: for anyone running Claude in long, unattended agentic loops, a model that proactively says "I'm not sure this is right" is materially safer to deploy than one that confidently ships a broken result.
Dynamic Workflows: Hundreds of Parallel Subagents
The flagship new feature is Dynamic Workflows, shipping as a research preview in Claude Code. It addresses a problem every agentic-coding user eventually hits: some jobs are simply too large for a single agent and a single context window — a framework migration across hundreds of thousands of lines, a dependency upgrade touching every service, a repo-wide refactor.

The pattern is an orchestrator-and-workers design. Opus 4.8 acts as an orchestrator that plans the work, splits it into independent segments, and dispatches them to hundreds of subagents running in parallel. Each subagent plans, executes, and verifies its own slice, and the orchestrator merges the verified results. Crucially, Anthropic frames the existing test suite as the bar: the system is designed to carry a codebase-scale migration "from kickoff to merge," using the repository's own tests as the gate for what counts as done.
This is less a model feature than an orchestration feature that the model's improved long-horizon coherence makes viable — the same capability Cognition's Scott Wu points to when describing workloads that run unattended. It is also why the honesty work and the workflow work belong in the same release: fanning out hundreds of agents is only useful if you can trust each one to flag what it could not finish. We have written before about why coordinated agents are becoming the default pattern in our DeerFlow super-agent guide; Dynamic Workflows is Anthropic's first-party version of that shift.
Effort Controls, Fast Mode, and the Cost Equation
Opus 4.8 makes the effort parameter — how much the model reasons before answering — easier to reach and changes its defaults.
- User-facing effort control. claude.ai users can now choose how much effort Claude puts into a task, trading response speed against reasoning depth and cost. In the API, the default effort level moves from
mediumtohigh, withxhighandmaxavailable for the hardest problems. - A cheaper fast mode. Fast mode runs the same Opus 4.8 model at roughly 2.5x the output speed for $10 per million input tokens and $50 per million output tokens. That is double the standard per-token rate, but three times cheaper than the $30 / $150 fast mode on previous Claude models — a real shift for latency-sensitive products that previously found fast mode too expensive to justify.
The combination changes the routing math. With standard pricing flat, a cheaper fast tier, and the Databricks-reported token-cost reduction, the question for most teams is no longer "is Opus affordable?" but "which effort level, in which mode, for which task class?" That is the same multi-model routing decision serious deployments already make across Opus, Sonnet, Haiku, GPT-5.5, and Gemini.
Knowledge Work and Financial Analysis
Coding is not the only area that moved. On GDPval-AA, a third-party Elo evaluation of economically valuable knowledge work across finance, legal, and other domains, Opus 4.8 reaches 1890 — 137 points above Opus 4.7's 1753 and 121 ahead of GPT-5.5's 1769. On Finance Agent v2, an agentic financial-analysis benchmark, it scores 53.9%, narrowly ahead of both Opus 4.7 (51.5%) and GPT-5.5 (51.8%).
These are the areas where Opus 4.8 becomes genuinely useful for first-draft memos, analyst research, and executive synthesis — work that previously needed close supervision. Harvey's record Legal Agent Benchmark result points the same way for regulated professional work. The output of all of it, though, still has to be communicated: a strategy memo or an equity-research note eventually becomes a deck for a partner meeting or an investment committee. Our guide to McKinsey-style deck logic covers the structural principles that still matter once an AI model is writing the raw content.
Migrating From Opus 4.7: What to Plan For
Anthropic describes the move from Opus 4.7 to 4.8 as largely non-breaking, but there are a few changes worth catching before you flip production traffic:
- The default effort level changed from
mediumtohigh. If your harness relied on the old default, you will see deeper reasoning, higher latency, and more output tokens unless you set the level explicitly. - Extended-thinking token budgets were removed. Code that passed a fixed
budget_tokensvalue needs to migrate to the new adaptive thinking configuration (thinking: {type: "adaptive"}). - The Messages API now accepts system entries mid-task without breaking the prompt cache — a convenience for agents that update instructions mid-run, and not a breaking change, but a behavior to be aware of.
A sensible migration checklist holds from any model upgrade: sample 20–50 real tasks from your production trace and replay them on Opus 4.8 at matched effort levels; compare end-to-end cost and quality; re-tune any prompts that pin effort or thinking budgets; and pilot Dynamic Workflows on one genuinely large job before wiring it into automation. As with the Opus 4.7 migration, the gains are large enough that the pilot usually pays for itself — but the token-cost math is empirical, so measure on your own workload.
The Business Backdrop and the Mythos Roadmap
Opus 4.8 did not ship in isolation. On the same day, Anthropic announced a $65 billion Series H raise at a roughly $965 billion valuation — figures that, as reported, would place it above OpenAI's valuation — led by Altimeter Capital, Dragoneer, Greenoaks, and Sequoia Capital, with around $15 billion committed by cloud providers including AWS. Anthropic also disclosed that its revenue run rate has climbed sharply over recent months. The cadence — a point release every six weeks, paired with a megaround — reads as a company pressing an advantage while the IPO race with OpenAI heats up.
Anthropic also used the launch to tease its Mythos-class models, currently in limited preview and restricted largely to cybersecurity work because of their vulnerability-finding capabilities. The company expects to make Mythos-class models more broadly available "in the coming weeks," pending the cyber safeguards it has been building since Project Glasswing. The pattern is familiar from the Opus 4.7 cycle: the X.Y release ships real improvements and acts as a deployment vehicle for safeguards that carry into the next, larger family — and the alignment chart above, with Opus 4.8 sitting just shy of Mythos Preview, is a preview of where that family is headed.
Who Should Care About Opus 4.8 Right Now
Four audiences have the most immediate reason to look:
Engineering teams already running Opus 4.7. The SWE-bench Pro gain plus the Databricks-reported ~61% token-cost reduction make a migration pilot worth the time. Just budget for the new high effort default and benchmark cost on real tasks before committing.
Teams with codebase-scale jobs. Dynamic Workflows is the reason to upgrade if you have a migration or repo-wide refactor that has stalled because it was too big for one agent. Start with a single bounded job where the test suite is trustworthy.
Anyone running unattended agentic loops. The honesty improvements matter most where no human reviews each step in real time — overnight agent runs, autonomous pipelines, long research tasks. A model that flags its own uncertainty changes the risk profile of leaving it alone.
Teams that turn technical work into communication artifacts. Once Claude handles the engineering or research, the output still has to be presented. That handoff gap is what Tosea.ai is built to close. For teams comparing the broader category, our 2026 buyer's guide covers the major options.
Testing Opus 4.8 on Slide Generation: We Ran a Real Paper Through It
We added Opus 4.8 to Tosea.ai on launch day — it now backs the outline-and-structure step in our document-to-deck pipeline — so the cleanest way to pressure-test the model's "document reasoning and taste" claims was to run a real paper through it and look at the output. We fed it Why Do Multi-Agent LLM Systems Fail?, a dense UC Berkeley paper that introduces the MAST taxonomy of multi-agent failure modes, and asked for a conference-style talk deck. Opus 4.8 returned an eight-slide presentation end to end. A few pages are below, unedited.

Three things stood out, and they map directly onto the benchmark story above.
Structure and narrative. The model didn't just chunk the PDF into bullets — it built an arc: motivation (the gap between multi-agent hype and minimal benchmark gains), the MAST taxonomy, methodology, results, and implications, with a roadmap slide that previews the whole talk. That is the long-context, multi-step reasoning gain doing visible work — it had to hold the paper's full argument in memory and decide what actually earns a slide.

Data fidelity. This is where the honesty gains matter most for slide work. The figures on the slides match the paper: 14 failure modes across 3 categories, a 0.88 Cohen's Kappa inter-annotator agreement, 7 frameworks analyzed across 200-plus tasks, and a per-framework failure-rate chart that preserves the source's actual values rather than inventing tidy round numbers. A model measurably less likely to let an unverified claim slip through is exactly what you want feeding a chart label.
Design taste. The deck is restrained — one consistent type system, a single accent color, and dark "key idea" cards used sparingly rather than on every slide — which is harder to get right automatically than it looks.
Two honest caveats keep this fair. This is a single example, not a benchmark, so read it as illustrative rather than conclusive. And a generated deck is a strong first draft, not a finished talk: speaker emphasis, a handful of transitions, and a final fact-check against the source still belong to a human. But the distance between "raw PDF" and "a deck you could actually present" is now narrow enough that the human's job is editing rather than building from scratch.
What Opus 4.8 Means for AI Slide Generation
The gains that matter most for engineering teams — better long-horizon coherence, cleaner tool use, and especially the honesty improvements — translate almost directly into a better experience for anyone using AI to turn long documents into presentation decks. The hard part of document-to-slide work has never been writing a sentence. It has been reading a 60-page PDF, identifying the three arguments that actually carry the story, and producing a slide structure that preserves the source's reasoning without fabricating numbers or citations. A model that is measurably less likely to let an unverified claim slip through is, almost by definition, a better engine for grounded slide generation — the exact failure mode we documented in our zero-hallucination AI slides guide.
For an AI presentation tool working against research papers, market analyses, or product specs, the practical effect shows up in three places: cleaner outline generation across multi-document inputs, fewer hallucinated chart labels and citation numbers, and better preservation of source structure when the input is genuinely complex. Dynamic Workflows points at something further out, too — a 200-slide deck assembled from an entire repository of source documents, with parallel agents drafting sections and a test-suite-style consistency check before they merge, the same scaling logic we explored in how to build a massive slide deck in minutes.
At Tosea.ai, where the document-to-PPT pipeline routes between several frontier models depending on the task, the Opus line has been a default for the structure-extraction step on dense academic and consulting inputs, and the 4.8 honesty gains are a direct upgrade to that step. If you already run a PDF-to-PowerPoint workflow that struggles on long-form sources, swapping in an Opus 4.8 backend is one of the simplest single improvements to try. For a worked example end to end, see our research-paper-to-slides guide and our walkthrough on converting PDFs to PowerPoint slides.
Sources
- Introducing Claude Opus 4.8 — Anthropic, May 28, 2026
- Anthropic releases Opus 4.8 with new 'dynamic workflow' tool — TechCrunch
- Anthropic's Claude Opus 4.8 is here with 3X cheaper fast mode and near-Mythos level alignment — VentureBeat
- As Anthropic launches Claude Opus 4.8, it raises $65B in new funding — SiliconANGLE
- Anthropic Launches Claude Opus 4.8 With Gains in Coding and Honesty — MacRumors
- Anthropic upgrades Claude with new Opus 4.8 model, here's what's new — 9to5Mac
- Anthropic releases new model, Opus 4.8 — Axios


