How to Use Claude Sonnet 5: Complete Guide for Agentic Coding 2026
Claude Sonnet 5 brings near-Opus agentic coding at Sonnet pricing. Full benchmarks vs Opus 4.8, GPT-5.5 and Gemini 3.5 Flash, effort levels, pricing, and how to use it.

On June 30, 2026, Anthropic released Claude Sonnet 5, the newest model in its mid-tier Sonnet line. The pitch is unusually direct: near-Opus intelligence on coding and agentic work, at Sonnet pricing. For teams that have been rationing their Opus budget, that framing matters — and the official benchmarks back up most of it.
This is a technical guide to Claude Sonnet 5: what it scores, where it wins and loses against Opus 4.8, GPT-5.5, and Gemini 3.5 Flash, how the new effort levels change the cost curve, what changed in the API, and how to actually put it to work. If you already tracked Claude Fable 5 or GLM-5.2, this slots into the same reference shelf — a model-launch deep dive rather than a press-release rewrite.
What Is Claude Sonnet 5?
Claude Sonnet 5 (model ID claude-sonnet-5) is the successor to Sonnet 4.6 and a drop-in replacement for it. Anthropic frames it as "the most agentic Sonnet model yet" — a model built to make plans, drive browsers and terminals, and run autonomously for long stretches at a level that, a few months ago, required larger and more expensive models. The system card puts it more plainly: near-Opus intelligence at Sonnet pricing for coding, agents, and everyday professional work.
It shipped the same day as the default model for Free and Pro users on claude.ai, and was simultaneously available on the Claude API, Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry (preview). Like the rest of the current Claude generation, it carries a 1M-token context window by default and a 128K-token maximum output.
The headline number is the cost delta. During the introductory window, Sonnet 5 runs at roughly a third of Opus pricing while landing within a few points of Opus 4.8 on several agentic benchmarks. That is the whole strategic argument of the release, and the benchmarks are where it has to hold up.
Claude Sonnet 5 Benchmarks: The Full Picture
Anthropic's launch comparison places Sonnet 5 against its predecessor and against Opus 4.8 as a reference ceiling.
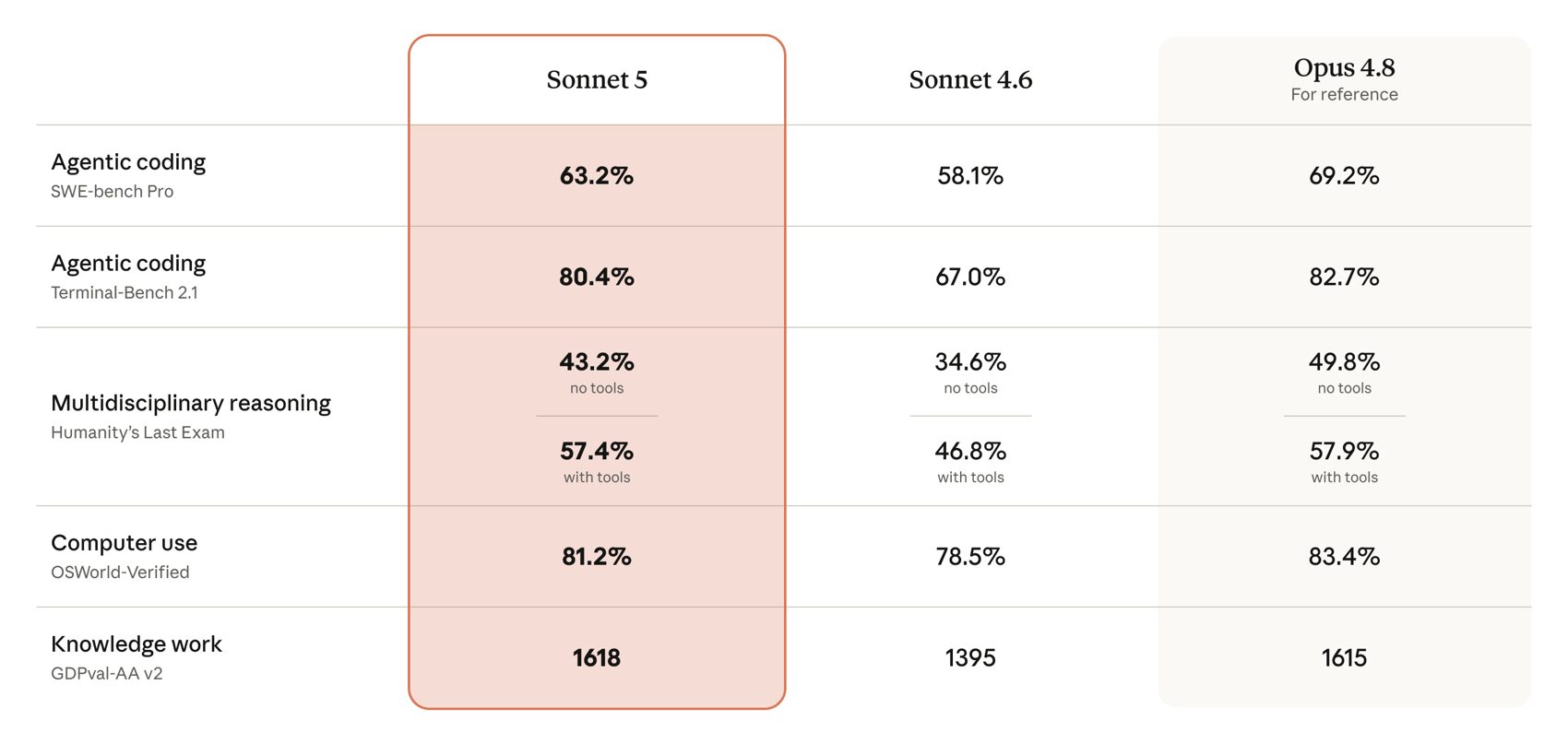
Transcribed from the official chart:
| Benchmark | Sonnet 5 | Sonnet 4.6 | Opus 4.8 (reference) |
|---|---|---|---|
| Agentic coding — SWE-bench Pro | 63.2% | 58.1% | 69.2% |
| Agentic coding — Terminal-Bench 2.1 | 80.4% | 67.0% | 82.7% |
| Reasoning — Humanity's Last Exam (no tools) | 43.2% | 34.6% | 49.8% |
| Reasoning — Humanity's Last Exam (with tools) | 57.4% | 46.8% | 57.9% |
| Computer use — OSWorld-Verified | 81.2% | 78.5% | 83.4% |
| Knowledge work — GDPval-AA v2 (Elo) | 1618 | 1395 | 1615 |
Two things stand out. First, versus Sonnet 4.6 this is a clean sweep with real jumps — Terminal-Bench climbs 13.4 points, and the GDPval-AA v2 knowledge-work Elo rises 223 points. Second, on knowledge work Sonnet 5 nominally edges Opus 4.8 (1618 vs 1615, a statistical tie), while on agentic coding and computer use it lands within roughly two to six points of the flagship. That "within a few points, at a third of the cost" gap is the entire value proposition.
The system card goes deeper. On the classic 500-problem SWE-bench Verified subset, Sonnet 5 scores 85.2%. It reaches 78.3% on SWE-bench Multilingual (nine languages) and 38.8 on Cognition's FrontierCode v1 — more than double Sonnet 4.6's 15.1. Cursor's independent measurement puts it at 61.2% on CursorBench, up from Sonnet 4.6's 49% and just shy of Opus 4.8's 63.8%. On agentic search, BrowseComp reaches 84.7% single-agent (86.6% multi-agent).
There is one honest soft spot worth flagging up front: math olympiad reasoning. On USAMO 2026, Sonnet 5 scores 79.5% — a big improvement over Sonnet 4.6's 55.0%, but far behind Opus 4.8's 96.7%. If your workload is heavy formal-proof mathematics, Sonnet 5 is not the tool; a top-tier model is.
Effort Levels and the Cost Curve
Sonnet 5 is the first Sonnet-tier model to expose the full effort ladder: low, medium, high (the default), xhigh, and max. Effort controls how much the model thinks and how many tool calls it makes before finishing. This is not a cosmetic knob — it is the lever that makes the "Opus quality at Sonnet cost" claim real.
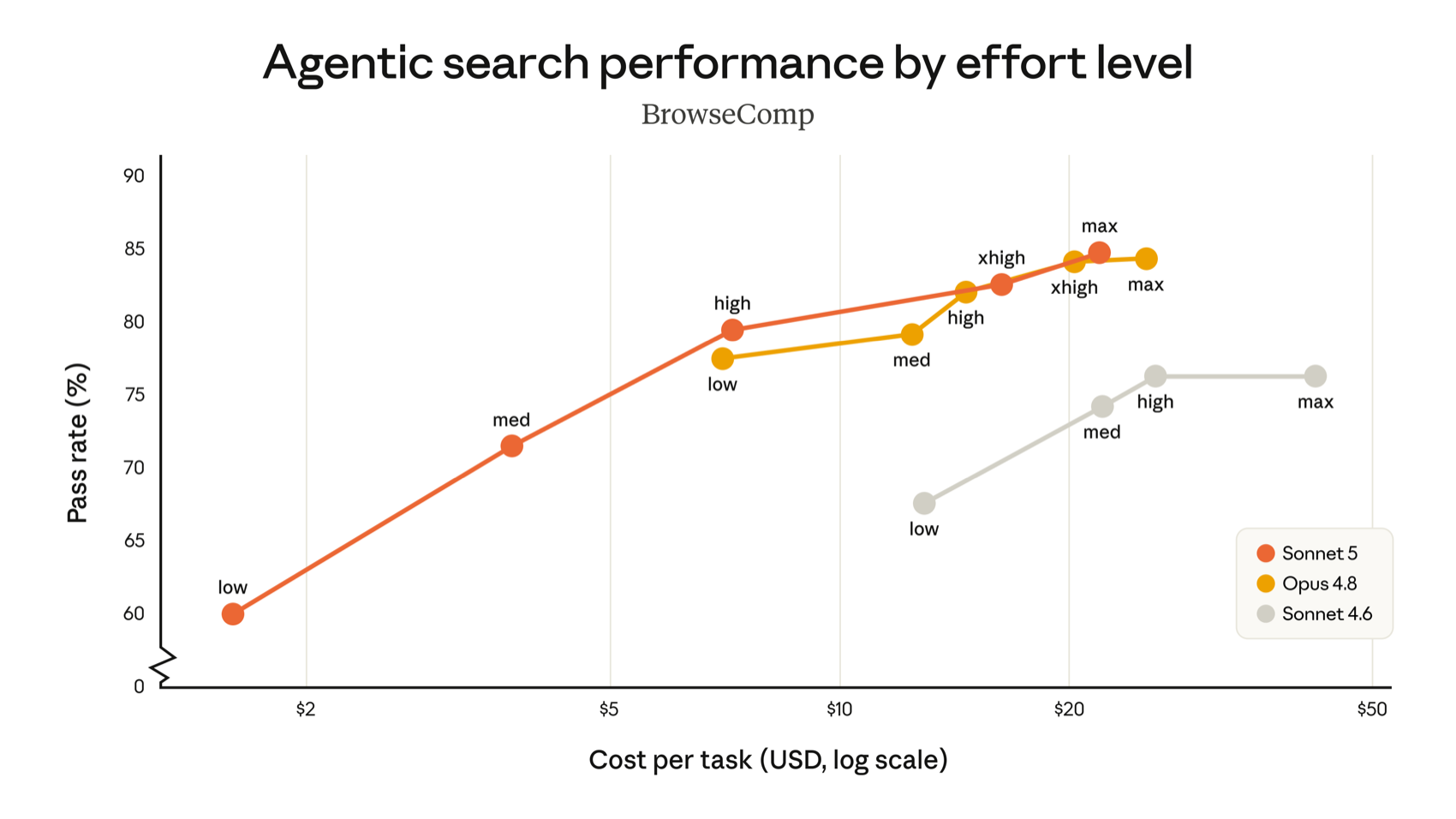
The BrowseComp effort curve is the clearest illustration. Plotted against cost-per-task, Sonnet 5's accuracy climbs from roughly 60% at low to about 85% at max, and critically it reaches Opus-4.8-class accuracy at a markedly lower dollar cost per task. Opus 4.8 still tops out slightly higher, but Sonnet 5 gets you most of the way there for far less money — which is exactly what you want in a high-volume agent loop.
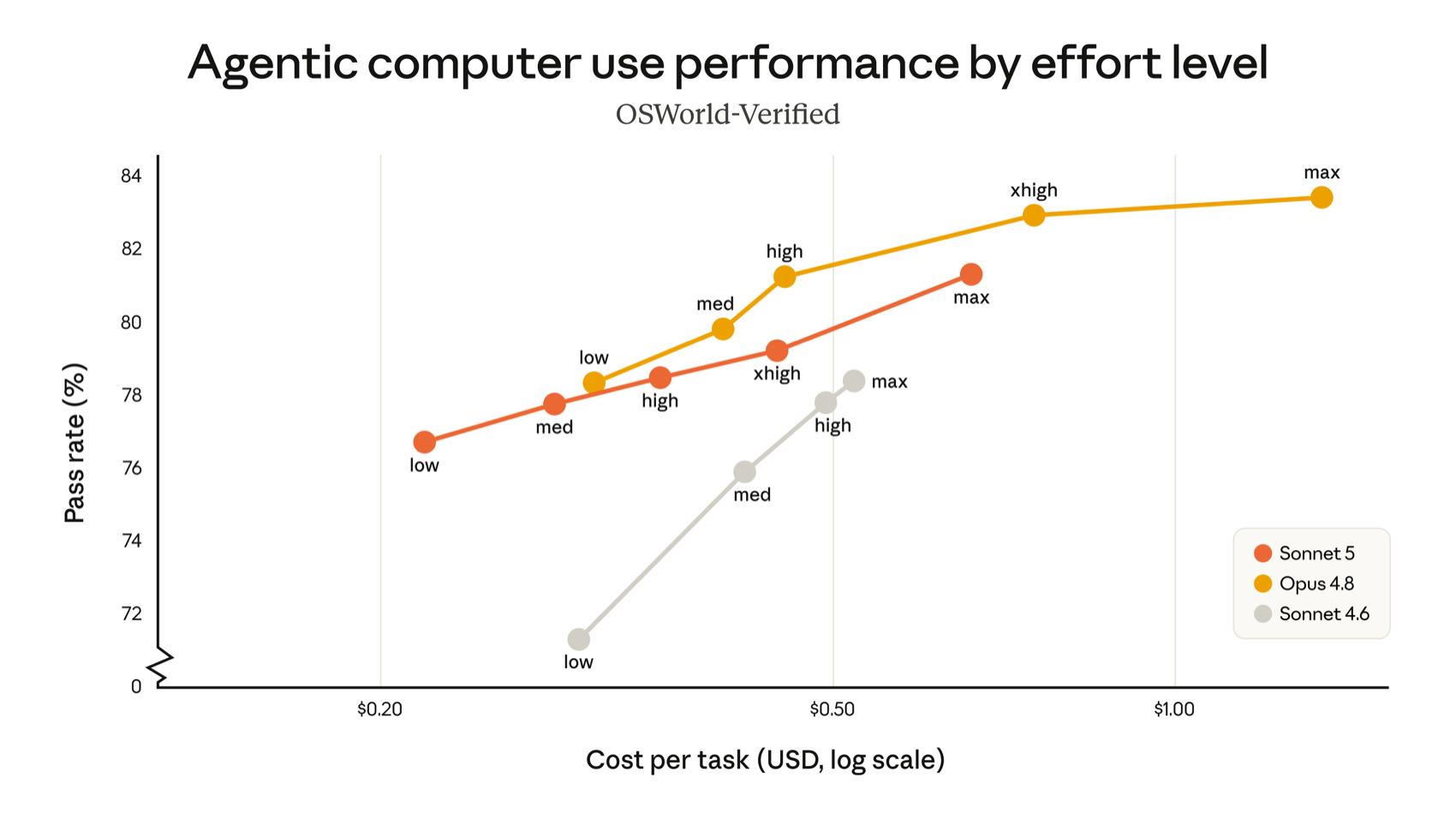
Computer use tells a more sober story. On OSWorld-Verified, Opus 4.8 stays ahead of Sonnet 5 at every effort level. Sonnet 5 still beats Sonnet 4.6 comfortably and remains far cheaper than Opus, but if pixel-accurate GUI control is your core workload, the flagship keeps a genuine edge here. The practical takeaway: reach for xhigh on the hardest long-horizon coding and agentic tasks, keep high for most work, and drop to medium or low for latency-sensitive or simple jobs. Effort is the primary intelligence-versus-cost dial — tune it per route rather than defaulting to max everywhere.
How Sonnet 5 Compares to GPT-5.5 and Gemini 3.5 Flash
The system card is the one place Anthropic published competitor numbers, and the chosen rivals are the cost-comparable tier — OpenAI's GPT-5.5 and Google's Gemini 3.5 Flash — not the absolute frontier (GPT-5.2, Gemini 3 Pro). Read the comparison as "beats the cost-comparable tier," not "beats everything."
| Evaluation | Sonnet 5 | GPT-5.5 | Gemini 3.5 Flash |
|---|---|---|---|
| SWE-bench Pro | 63.2 | 58.6 | 55.1 |
| Terminal-Bench 2.1 | 80.4 | 83.4 (Codex CLI) | 76.2 |
| Humanity's Last Exam (no tools) | 43.2 | 41.4 | 40.2 |
| Humanity's Last Exam (with tools) | 57.4 | 52.2 | — |
| OSWorld-Verified | 81.2 | 78.7 | 78.4 |
| FrontierCode v1 | 38.8 | 25.5 | — |
| GDPval-AA v2 (Elo) | 1618 | 1509 | 1357 |
| AutomationBench | 13.5 | 12.9 | 14.5 |
| HealthBench Professional | 57.8 | 51.8 | — |
Against GPT-5.5, Sonnet 5 wins most head-to-heads — SWE-bench Pro, both Humanity's Last Exam configurations, OSWorld, FrontierCode, GDPval-AA v2, and HealthBench Professional. It loses one that matters: Terminal-Bench 2.1, where GPT-5.5 driving the Codex CLI scores 83.4 to Sonnet 5's 80.4. Against Gemini 3.5 Flash the sweep is broader, with the single exception of AutomationBench (13.5 vs 14.5), where Gemini edges ahead. Note too that AutomationBench and Toolathlon absolute scores are low across the board — these are hard, unsaturated benchmarks, not solved ones.
Where Sonnet 5 Wins, Ties, and Trails vs Opus 4.8
Because the release positions Sonnet 5 against Anthropic's own flagship, the honest internal comparison is the most useful one for a buying decision.
- Ties or edges Opus 4.8: GDPval-AA v2 knowledge work (1618 vs 1615), agentic search on BrowseComp ("comparable accuracy for a given task cost"), Real-World Finance v2 (1219 vs 1222, tied), and the AA-Briefcase professional-work Elo (1393 vs 1352, tied).
- Trails Opus 4.8: SWE-bench Pro (63.2 vs 69.2), Terminal-Bench 2.1 (80.4 vs 82.7), OSWorld (81.2 vs 83.4), Humanity's Last Exam no-tools (43.2 vs 49.8), CursorBench (61.2 vs 63.8), Toolathlon (54.3 vs 59.9), and USAMO 2026 (79.5 vs 96.7).
The pattern is consistent: on open-ended knowledge work and agentic search, Sonnet 5 is effectively Opus-class; on the hardest coding, computer use, and formal math, Opus 4.8 keeps a real but modest lead. For most product workloads — where you are running many agent turns and cost dominates — Sonnet 5 is the rational default, and you escalate to Opus only for the genuinely hard tail. This mirrors the broader shift toward AI agents redefining how slides and documents get built: capability is now cheap enough to run at scale, and the interesting question is where to spend the premium.
What's New Under the Hood
Sonnet 5 brings the Sonnet line onto the same API surface as the Opus 4.7/4.8 generation, plus some genuinely new mechanics.
Adaptive thinking is on by default. Sonnet 4.6 ran without thinking unless you asked for it; Sonnet 5 thinks adaptively out of the box, deciding per request how much reasoning a task warrants. You can still turn it off explicitly when you need raw speed.
Manual thinking budgets are gone. The old budget_tokens parameter now returns an error. You control depth through effort levels instead — a cleaner model, but one that breaks code migrated straight from Sonnet 4.6. Non-default sampling parameters (temperature, top_p, top_k) are likewise rejected; steer behavior with prompting.
A new, denser tokenizer. Sonnet 5 shares the tokenizer introduced with Opus 4.7, which turns the same text into roughly 30% more tokens. Per-token pricing is unchanged, so an equivalent request can cost more than it did on Sonnet 4.6. Re-measure your token budgets and revisit max_tokens — a limit tuned for the old tokenizer can now truncate output mid-thought.
High-resolution vision. Sonnet 5 is the first Sonnet-tier model with a high-resolution image tier: up to 2576 pixels on the long edge and 4784 visual tokens, versus the old 1568-pixel cap. It activates automatically. That matters for document, chart, and screenshot understanding — the kind of dense visual input that feeds a document-to-deck pipeline.
On the architecture itself, Anthropic disclosed little. The system card notes training on a proprietary mix of public web data (gathered by the robots.txt-respecting ClaudeBot crawler), licensed datasets, and synthetic data generated by other models, followed by rigorous post-training and fine-tuning aligned to Claude's constitution. No parameter count, compute figure, or RL recipe is published — the card's bulk is safety and alignment evaluation, including the first real-time cybersecurity safeguards on a Sonnet model, which can refuse high-risk requests.
Pricing and Cost Economics
Pricing is the reason to care about Sonnet 5, so it is worth stating precisely.
- Introductory (through August 31, 2026): $2 per million input tokens, $10 per million output tokens.
- Standard (from September 1, 2026): $3 input, $15 output — identical to Sonnet 4.6.
- Prompt caching: cache reads land at roughly $0.20 per million tokens during the intro window ($0.30 standard), a ~90% discount on cached context.
- Batch API: 50% off, so $1 input / $5 output per million during the intro window.
Against Opus 4.8 at $5 input / $25 output, Sonnet 5 is roughly a third of the cost at introductory rates and about 60% of the cost at standard rates. Layer in the effort dial and prompt caching, and the cost gap for a well-tuned agent workload can be larger still. One caveat: the ~30% denser tokenizer means you should recompute real spend on your own prompts rather than assuming the sticker price maps cleanly from Sonnet 4.6. The one feature it lacks versus some tiers is Priority Tier access, which is not available on Sonnet 5.
How to Use Claude Sonnet 5
Getting started is a model-ID swap plus a few adjustments:
- Point to the new model. Use
claude-sonnet-5in place ofclaude-sonnet-4-6. On Bedrock the ID carries theanthropic.prefix; on Vertex AI it is the bare ID. - Drop
budget_tokensand sampling params. Replace any manual thinking budget with an effort level, and removetemperature/top_p/top_k— they now 400. - Set effort deliberately. Default to
high; reach forxhighon the hardest coding and agentic tasks; step down tomediumorlowfor cheap, latency-sensitive routes. Effort is your main cost lever. - Re-baseline token counts. The new tokenizer inflates counts ~30%; recount budgets and give
max_tokensheadroom so long outputs are not cut off. - Lean on prompt caching. For repeated context — a shared system prompt, a large document, a codebase — caching drops the cost of the stable prefix by an order of magnitude.
For interactive coding, Cursor and other agent harnesses already expose Sonnet 5, so you can evaluate it against your own repositories without writing integration code. If you are building autonomous loops, the loop-engineering patterns for AI agents apply directly — Sonnet 5's low per-token cost is what makes long, iterative agent runs economical in the first place.
Migrating from Sonnet 4.6
Because Sonnet 5 adopts the Opus 4.7/4.8 request surface, moving over is more than a string swap. The changes that will actually break code:
budget_tokensis removed. Manual thinking budgets now return an HTTP 400. Replace them with an effort level.- Sampling parameters are rejected. Any non-default
temperature,top_p, ortop_kreturns a 400 — delete them and steer behavior with prompting. - Adaptive thinking is the new default. If you relied on Sonnet 4.6's thinking-off default, set thinking to disabled explicitly, or budget for the extra thinking tokens.
- The tokenizer is denser. Recount your prompts — the same text is ~30% more tokens — and raise
max_tokensso long outputs don't truncate. - Assistant-message prefilling stays unsupported. Use structured outputs to force a response shape instead.
Run one representative request first, inspect stop_reason and usage, and re-baseline your cost dashboards before rolling out. A migration that only swaps the model ID will 400 on the first request that carries a sampling parameter or a thinking budget.
Safety and Cybersecurity Safeguards
Sonnet 5 is the first Sonnet-tier model to ship with real-time cybersecurity safeguards. Requests that touch prohibited or high-risk cyber and biology topics can be refused — returned as a successful HTTP 200 with a refusal stop reason rather than as an error. If you're building security tooling or life-sciences workflows where benign-but-adjacent requests might trip a classifier, handle that stop reason explicitly instead of assuming every 200 carries usable content. The bulk of the 145-page system card is devoted to this: exploit and cyber evaluations, prompt-injection resistance, agentic-safety testing, bias, mental-health, and child-safety assessments, plus a full alignment and model-welfare review. Anthropic also reports lower hallucination and sycophancy rates than Sonnet 4.6 — meaningful for any workflow where the model's output is trusted downstream without a human check.
Who Should Use Claude Sonnet 5?
Sonnet 5 is the rational default for teams running high-volume agentic workloads — coding agents, browser and terminal automation, retrieval and research loops — where cost per turn compounds fast and Opus-tier pricing is hard to justify. It's a strong fit for product builders embedding an LLM into a shipping feature, for startups shipping AI-heavy products that need frontier-adjacent quality on a budget, and for anyone doing long-context document work where the 1M window and low per-token price make bulk processing viable. Reach for Opus 4.8 instead when the task is in the hard tail: the most demanding coding, pixel-accurate computer use, or formal mathematics, where the flagship's few-point lead is worth the premium.
What Claude Sonnet 5 Means for AI Slide Generation
A cheaper, more agentic reasoning model is not an abstraction for presentation work — it is the engine underneath modern AI slide generation. Turning a dense source document into a coherent deck is a multi-step reasoning problem: read and structure long input, plan a narrative arc across dozens of slides, and emit clean, renderable markup. Sonnet 5's 1M-token context lets an AI presentation tool hold an entire report, transcript, or research paper in a single pass, while its agentic tuning keeps a multi-slide outline internally consistent instead of drifting halfway through the deck.
The economics are the real unlock. Bulk document-to-PPT generation means many long-context calls per deck, and at scale the per-token cost decides whether a feature is viable. Sonnet 5's introductory pricing and effort dial make it practical to run the higher-effort reasoning that produces a defensible slide structure — logical sections, evidence on the right slides, a clean close — rather than a flat bullet dump. Its high-resolution vision also strengthens the PDF-to-PowerPoint path, where charts and tables in the source have to be read accurately before they can be rebuilt as native slides.
This is exactly the layer Tosea.ai sits on. Tosea is the document-to-deck orchestration layer: it takes a raw PDF or brief, runs the long-context reasoning and structuring, and produces an editable presentation. A stronger, cheaper base model like Sonnet 5 directly improves that presentation workflow — better outlines, fewer hallucinated facts, and lower cost per deck. If you want to see how that plays out in practice, our guides on zero-hallucination AI slides and generating massive slide decks with AI cover the workflow end to end, and our roundup of the best AI slide generators puts the tooling landscape in context.
Frequently Asked Questions
Is Claude Sonnet 5 better than Opus 4.8? On open-ended knowledge work and agentic search it's effectively tied — Sonnet 5 even nudges ahead on the GDPval-AA v2 Elo (1618 vs 1615). On the hardest coding, computer use, and formal math, Opus 4.8 keeps a modest lead. For most workloads Sonnet 5 wins on cost-adjusted value; for the hard tail, Opus is still worth it.
How much does Claude Sonnet 5 cost? $2 per million input tokens and $10 per million output during the introductory window (through August 31, 2026), rising to $3 / $15 afterward. Prompt caching cuts cached-context reads by roughly 90%, and the Batch API halves the rate.
What is the xhigh effort level?
Sonnet 5 is the first Sonnet-tier model to support xhigh, an effort setting between high and max tuned for long-horizon agentic and coding tasks. Use high as your default, xhigh for the hardest agentic work, and step down to medium or low for cheap, latency-sensitive routes.
Does Claude Sonnet 5 support a 1M-token context window? Yes — 1M tokens by default, billed at the standard per-token rate with no long-context surcharge, and up to 128K output tokens (streaming is required for very large outputs).
Can Claude Sonnet 5 use tools and control a computer? Yes. It supports tool use, web search, web fetch, code execution, and computer use, and scores 81.2% on OSWorld-Verified — close to Opus 4.8's 83.4% at a fraction of the cost.
The Bottom Line
Claude Sonnet 5 delivers on its central promise: for coding and agentic work, it lands close enough to Opus 4.8 that, at a third of the cost during the introductory window, it becomes the sensible default and reserves the flagship for the hardest tail. It wins most head-to-heads against the cost-comparable GPT-5.5 and Gemini 3.5 Flash tiers, with honest exceptions — Terminal-Bench against GPT-5.5, AutomationBench against Gemini, and formal math against Opus. The API changes (no budget_tokens, the denser tokenizer, effort-driven depth) mean a migration is more than a string swap, but the payoff is a model that makes long, iterative agent runs — and high-volume document work — economical.
Sources
- Introducing Claude Sonnet 5 — Anthropic, June 30, 2026
- Claude Sonnet 5 System Card — Anthropic
- What's new in Claude Sonnet 5 — Anthropic Docs
- Anthropic launches Claude Sonnet 5 as a cheaper way to run agents — TechCrunch
- Anthropic launches Claude Sonnet 5 at a steep discount to its top model — VentureBeat
- Anthropic's new Claude Sonnet 5 closes the gap to the pricier Opus model series — The Decoder


