How to Use GLM-5.2: Complete Guide to Zhipu AI's 1M-Context Open-Source Coding Model
A technical guide to GLM-5.2 — Zhipu AI's MIT-licensed 744B MoE model with a 1M-token context window, IndexShare attention, and the official benchmarks against GPT-5.5 and Claude Opus 4.8.

Zhipu AI — the Beijing lab that ships its models under the Z.ai brand — has now officially open-sourced GLM-5.2, putting the full weights of its 744-billion-parameter Mixture-of-Experts model on Hugging Face under a permissive MIT license. The model first reached GLM Coding Plan subscribers on June 13, 2026; with the open weights, a standalone API, and the official benchmark suite now public, GLM-5.2 has gone from a coding-plan preview to a model anyone can download, fine-tune, and self-host. The headline capability is a usable 1-million-token context window built specifically for long-horizon, agentic engineering.
The marketing line that circulated on launch day — "beats GPT-5.5 at a sixth of the cost" — is half the story, and the less interesting half. Now that Zhipu has published the numbers, the accurate picture is more nuanced and, for anyone making a real model decision, more useful: GLM-5.2 is the strongest open-weight coding model by a clear margin, it matches Claude Opus 4.8 on agentic tool use and edges GPT-5.5 on resolved-PR work, and it still trails the closed frontier on the hardest from-scratch coding tasks. This guide walks through the architecture, the official benchmarks line by line, the arena results, the pricing, and the specific places GLM-5.2 should and should not be your model.
What Is GLM-5.2?
GLM-5.2 is the latest release in Zhipu's General Language Model line and the direct successor to GLM-5.1. It is a sparse Mixture-of-Experts (MoE) model with 744 billion total parameters and roughly 40 billion active per token — the router selects a small subset of experts for each step, which is what keeps a model this large economical to serve. Weights ship in both BF16 and FP8, and the open release is MIT-licensed, which permits commercial use, modification, and redistribution with essentially no restrictions.
Two design decisions define the release. First, the context window: a genuinely usable 1,000,000 input tokens (the model identifier is glm-5.2[1m]), with output up to 131,072 tokens — roughly five times the ~200K ceiling of GLM-5.1. Second, flexible reasoning effort: GLM-5.2 exposes two explicit modes, High for fast routine generation and Max for deep multi-step coding and architecture work, selectable per request rather than per model. A quick refactor and a full feature build hit the same endpoint at different cost-performance points.
The positioning is deliberately narrow. Zhipu did not pitch GLM-5.2 as a general chatbot upgrade; it built and benchmarked it around long-horizon engineering — the multi-step loop where a model writes code, runs it, reads the failure, and revises across an entire project. Understanding why it is good at that, and where it is not, starts with the attention architecture.
Inside the Architecture: DSA, IndexShare, and MTP
The reason GLM-5.2 can offer 1M tokens as a usable window rather than a spec-sheet number comes down to three pieces of engineering, detailed in Zhipu's technical report.

The foundation is DeepSeek Sparse Attention (DSA). Instead of every token attending to every other token — the quadratic cost that makes long context expensive — DSA attends to a sparse, learned subset, cutting both training and inference cost while preserving long-context fidelity. On top of DSA, GLM-5.2 introduces IndexShare: rather than computing a fresh attention index at every layer, it reuses a single lightweight indexer across every four sparse-attention layers, which Zhipu reports cuts per-token FLOPs by 2.9× at 1M-token context. That ratio is the difference between a 1M window that is technically supported and one you can afford to actually fill on every request.
The third piece is an upgraded Multi-Token Prediction (MTP) layer driving speculative decoding. By predicting several tokens ahead and verifying them in parallel, GLM-5.2 raises the accepted token length by up to 20%, a throughput win that compounds on exactly the long, tool-heavy agent runs the model targets. Underneath all of this, GLM-5.2 was pre-trained on 28.5 trillion tokens and post-trained with "slime," an asynchronous reinforcement-learning infrastructure that decouples generation from training and runs novel async agent-RL algorithms to teach the model from long-horizon, multi-tool interactions. The architecture and the training objective point at the same target: sustained, multi-step engineering work rather than single-shot answers.
The Official Benchmarks: Where GLM-5.2 Wins and Where It Trails
Zhipu's official evaluation spans eight benchmarks — SWE-bench Pro, Terminal-Bench 2.1, NL2Repo, DeepSWE, ProgramBench, MCP-Atlas, Tool-Decathlon, and Humanity's Last Exam — with every model run under its maximum thinking effort. That last detail matters: these are best-case numbers for everyone in the table, GLM-5.2 included, so read them as a capability ceiling rather than a default-settings result.
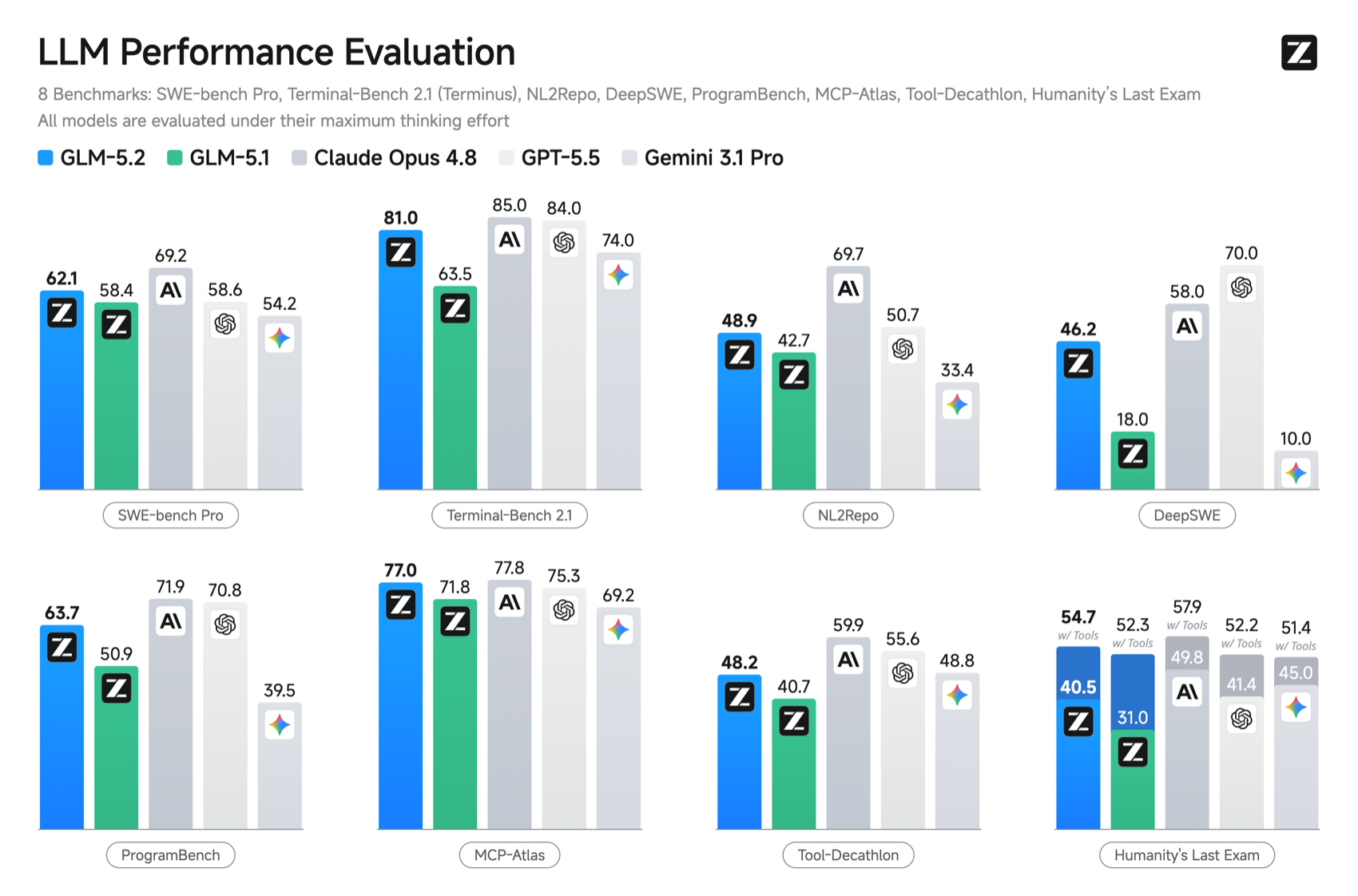
| Benchmark (max effort) | GLM-5.2 | GLM-5.1 | Claude Opus 4.8 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|---|
| SWE-bench Pro | 62.1 | 58.4 | 69.2 | 58.6 | 54.2 |
| Terminal-Bench 2.1 | 81.0 | 63.5 | 85.0 | 84.0 | 74.0 |
| NL2Repo | 48.9 | 42.7 | 69.7 | 50.7 | 33.4 |
| DeepSWE | 46.2 | 18.0 | 58.0 | 70.0 | 10.0 |
| ProgramBench | 63.7 | 50.9 | 71.9 | 70.8 | 39.5 |
| MCP-Atlas | 77.0 | 71.8 | 77.8 | 75.3 | 69.2 |
| Tool-Decathlon | 48.2 | 40.7 | 59.9 | 55.6 | 48.8 |
| HLE (with tools) | 54.7 | 52.3 | 57.9 | 52.2 | 51.4 |
Read carefully, the table tells a precise story. GLM-5.2's clearest strength is agentic tool orchestration: on MCP-Atlas, which measures multi-tool agent workflows, it scores 77.0 — statistically level with Claude Opus 4.8's 77.8 and ahead of GPT-5.5's 75.3. On SWE-bench Pro, the resolved-real-PR benchmark, its 62.1 beats GPT-5.5 (58.6) and Gemini 3.1 Pro (54.2), trailing only Opus. And on Humanity's Last Exam with tools, 54.7 edges out both GPT-5.5 (52.2) and Gemini (51.4). Those three are the basis for the "beats GPT-5.5" headline — and they are real, but they are specific.
The other side is just as important. On DeepSWE (hard from-scratch algorithmic coding) GLM-5.2's 46.2 trails GPT-5.5's 70.0 badly; on NL2Repo (end-to-end repository synthesis) its 48.9 is far behind Opus's 69.7; and on ProgramBench, Terminal-Bench 2.1, and Tool-Decathlon it sits a clear notch below both closed leaders. The honest summary is that GLM-5.2 matches or beats GPT-5.5 on resolved-PR and tool-use work, ties Opus on agentic orchestration, and trails the closed frontier on the hardest synthesis-from-scratch tasks.
Where GLM-5.2 is unambiguous is the generational jump over GLM-5.1: DeepSWE leaps from 18.0 to 46.2, Terminal-Bench from 63.5 to 81.0, and ProgramBench from 50.9 to 63.7. Against the open field it is not close — Zhipu's reasoning numbers on the model card add AIME 2026 at 99.2 (the top score in the comparison set, ahead of GPT-5.5's 98.3) and GPQA-Diamond at 91.2 (within a few points of the closed leaders). This is the best open-weight coding model available, and the gap to the closed frontier is now measured in specific benchmarks, not in generations.
Arena Results: #2 on Code Arena Frontend
Static benchmarks measure resolved tasks; arena leaderboards measure human preference on open-ended work, and GLM-5.2's standing there is striking. On LMArena's Code Arena: Frontend leaderboard, GLM-5.2 (Max) ranks #2 overall — behind only Fable 5 and a full +29 points ahead of Claude Opus 4.7 (Thinking) — according to Arena.ai's published results. It is the top-ranked open model by a wide margin over peers like Kimi K2.6 and Minimax-M3, takes #2 on the React sub-leaderboard and #4 on HTML, and ranks first in several application categories including Brand & Marketing, Data & Analytics, Consumer Product, and Gaming.
The frontend result is worth dwelling on, because it connects directly to how GLM-5.2 behaves on real generation work: producing clean, runnable HTML, React, and visual layouts that humans actually prefer when shown side by side. That is a different signal from a resolved-PR percentage, and it is the signal that matters for anything where the model's output is rendered rather than merely correct — UI code, dashboards, and, as we will come back to, slide markup.
The 1-Million-Token Context Window in Practice
A 1M-token window is easy to advertise and hard to use well, so it is worth being concrete. The practical unlock is project-level context: rather than feeding the model one file at a time, you can load an entire repository, its design doc, its test suite, and the open issue into a single prompt and let the model keep the whole working state in view. For long-running agent tasks — "implement this feature end to end, run the tests, fix what breaks" — a model that forgets the architecture after 200K tokens will quietly reintroduce a bug it fixed an hour earlier; one that holds the whole task keeps its corrections. This is where DSA and IndexShare pay off, because they make filling that window economically realistic instead of a luxury reserved for the highest tier.
The caveat is the same one that applies to every long-context model: a 1M ceiling is not free real estate. Every token still costs money and adds latency, and indiscriminately stuffing the window degrades retrieval quality. The skill is loading what the task genuinely needs — the same discipline that separates a working document-to-deck pipeline from one that drifts off-source, a point we will return to.
Pricing and the Cost Curve
GLM-5.2's API is priced at $1.40 per million input tokens and $4.40 per million output tokens — roughly one-sixth of what comparable closed frontier coding access costs on a per-token basis. For teams who prefer a subscription, the GLM Coding Plan maps onto the same logic:
| Plan | Price | Roughly |
|---|---|---|
| Lite | ~$30 / quarter | ~$10 / month |
| Pro | ~$90 / quarter | ~$30 / month |
| Max | ~$240 / quarter | ~$80 / month |

The strategic point, framed by the South China Morning Post as access "at a tenth of Anthropic's premium Claude Code and Claude Max tiers," is not a rounding detail. When an open-weights model lands within a few benchmark points of the closed frontier at one-sixth to one-tenth of the price — and can additionally be self-hosted for zero marginal token cost — the binding constraint for many teams stops being "which model is three points better on DeepSWE" and becomes "which model can I afford to run on every task, all day." That is the pressure GLM-5.2 puts on the rest of the market, and it is why the closed labs' pricing is the part of this release most likely to move.
How GLM-5.2 Compares to GPT-5.5 and Claude Opus 4.8
Pulling the threads together: on the work that dominates day-to-day engineering — resolving real pull requests, orchestrating tools, generating front-end code — GLM-5.2 is genuinely competitive with the closed frontier, beating GPT-5.5 on several of those axes and tying Opus on agentic tool use. On the hardest from-scratch synthesis and the most abstract reasoning, the closed leaders still hold a real edge, and Humanity's Last Exam without tools (where GLM-5.2's 40.5 trails Opus's 49.8) shows where that gap lives.
| GLM-5.2 | GPT-5.5 | Claude Opus 4.8 | |
|---|---|---|---|
| Weights | Open (MIT) | Closed | Closed |
| Context | 1M tokens | Large | Large |
| Agentic tool use (MCP-Atlas) | 77.0 | 75.3 | 77.8 |
| Resolved PRs (SWE-bench Pro) | 62.1 | 58.6 | 69.2 |
| Hard from-scratch (DeepSWE) | 46.2 | 70.0 | 58.0 |
| Relative cost | 1× (baseline) | ~6× | ~10× |
The decision rule that falls out of this is clean. If your workload is feedback-rich engineering — refactors, bug fixes, tool-driven agents, front-end generation — GLM-5.2 is the value pick and often the outright better one against GPT-5.5. If your workload is feedback-poor reasoning or hard algorithmic synthesis with no test to check against, the closed leaders justify their premium. For most teams the answer is not one model but a router that sends each task to the cheapest model that clears its quality bar — which is exactly how mature document and slide pipelines already treat the model layer.
Why the Open-Weights, MIT License Matters
The MIT license is doing more work here than a footnote suggests. It permits unrestricted commercial use, modification, and self-hosting with essentially no strings, which means an enterprise can run GLM-5.2 on its own hardware, behind its own firewall, with no per-token bill and no data leaving the building. For regulated industries and cost-sensitive teams, that combination of near-frontier capability and a genuinely permissive license is rare — and it is the same lever that made Kimi K2.6 and the open Qwen line attractive.
The timing was not incidental. GLM-5.2's launch landed shortly after Anthropic abruptly suspended access to its flagship models for some users under export-control directives — a reminder that closed-model access can be revoked by forces unrelated to your usage. Markets read the moment clearly: Zhipu AI, listed in Hong Kong as Knowledge Atlas Technology after a blockbuster January IPO, saw its stock jump as much as 48% intraday and close up 32.8% at HK$1,457 on the open-source news, leaving it up roughly 820% since listing. The broader pattern is Chinese labs moving to capture users who want an alternative to Western frontier models amid high prices and geopolitical uncertainty — and an open, self-hostable model is the most durable form of that alternative, because no one can switch it off.
How to Start Using GLM-5.2 Today
There are three practical paths to GLM-5.2, depending on how much control you need.
- GLM Coding Plan (fastest). GLM-5.2 is live for every Coding Plan tier. The detail that matters for adoption is that Zhipu ships an Anthropic-compatible API endpoint, so tools like Claude Code, Cline, OpenCode, OpenClaw, and Cursor — more than 20 coding environments — can use GLM-5.2 as a drop-in by changing the base URL and key, with no SDK rewrite.
- Metered API. For variable workloads, call the API directly at $1.40 / $4.40 per million input/output tokens, and choose High effort for routine generation or Max for multi-step builds.
- Self-host the open weights. The MIT-licensed BF16 and FP8 weights are published under
zai-org/GLM-5.2on Hugging Face and run under inference stacks like vLLM, so teams with the GPUs can serve it entirely in-house with zero marginal token cost.
Whichever path you pick, the one operational habit worth forming early is context discipline: load the files and docs the task actually needs rather than dumping the whole monorepo into the window just because 1M tokens fit.
Where GLM-5.2 Does Not Fit
The official numbers make GLM-5.2's gaps specific rather than vague. The clearest is hard from-scratch synthesis and abstract reasoning: DeepSWE (46.2 vs GPT-5.5's 70.0), NL2Repo (48.9 vs Opus's 69.7), and Humanity's Last Exam without tools (40.5 vs Opus's 49.8) all show the closed frontier ahead on tasks that demand long, feedback-poor reasoning chains. If your work lives there — novel algorithms, intricate planning with no test to check against — GLM-5.2 is not the model to bet a deadline on.
The second gap is modality. GLM-5.2 is a text-and-code model; robust vision or audio support was not part of the open release, so any workflow that needs to read screenshots, parse charts from images, or process speech belongs to a multimodal model like Gemini 3.5 Flash, not this one. And the third is a methodological caution worth repeating: the published numbers are maximum-effort results, so your default-settings experience will land below the headline figures. Validate GLM-5.2 on your own tasks at the effort level you will actually run before committing a production pipeline to it.
Who Should Care About GLM-5.2
A few audiences should look closely now. Engineering teams running agentic coding at scale — anyone whose token bill is dominated by automated refactors, tool-driven agents, and resolved-PR work — get the most direct benefit, because that is precisely where GLM-5.2 matches or beats GPT-5.5 at a fraction of the cost. Front-end and product teams have a specific reason to care given the Code Arena Frontend result. Cost-sensitive startups and individual developers priced out of GPT-5.5 or Claude Opus now have a credible near-frontier option inside a $10–$30 monthly plan. And regulated enterprises gain a self-hostable, MIT-licensed model they fully control. The audience that should not switch wholesale is anyone whose core workload is hard algorithmic synthesis, feedback-poor reasoning, or anything multimodal — for them GLM-5.2 is a complement, not a replacement.
What Happens Next
The immediate watch items are the independent reproductions. Now that the weights and the official benchmark methodology are public, third-party labs will rerun SWE-bench Pro, DeepSWE, and the agentic suites at standard effort levels, and those results — not the launch-day numbers — will settle GLM-5.2's real standing against GPT-5.5 and Claude Opus 4.8. The bigger trend is harder to reverse: each cycle, the open frontier closes more of the gap to the closed one, and it does so at a price that forces the whole market to justify its premium. GLM-5.2 is the current sharp edge of that pressure, and the architecture it introduces — DSA plus IndexShare for cheap 1M-token context — is the kind of efficiency work the next open releases will build on.
GLM-5.2 in the AI Presentation Stack
Two of GLM-5.2's strengths line up unusually well with slide generation. The first is the Code Arena Frontend result: a model that humans prefer for producing clean, runnable HTML and React is, almost by definition, good at the markup an HTML-based deck is built from. The second is the cheap 1M-token window, which changes the economics of turning large document sets into slides at volume — a consulting team generating weekly client decks from a rolling pile of internal reports, a research group producing a slide summary for every paper in a review, a finance desk converting daily filings into briefing slides. A full source document, a style guide, and prior decks can all sit in one prompt, which is what keeps a generated deck consistent with everything that came before it.
But raw model capability does not produce a good deck on its own, and that gap is the entire point. GLM-5.2 will happily emit coherent HTML; the distance between "coherent HTML" and an executive-ready slide deck with traceable citations and consistent visual style lives in the orchestration layer above the model — source ingestion, chunking, table and formula preservation, citation back-tracking, and per-slide style control. We dug into exactly that failure mode in our zero-hallucination AI slides guide, and it is why a strong model is necessary but not sufficient for reliable AI slide generation.
This is the layer where Tosea.ai sits as the document-to-deck orchestration layer. Its PDF-to-PowerPoint pipeline can route the per-slide generation step through a low-cost model like GLM-5.2 when token economics are the binding constraint, or through a closed leader when a source is unusually difficult, without changing the rest of the presentation workflow. For teams producing decks at scale, our massive slide deck guide and convert PDF to PowerPoint guide walk through the practical setup. GLM-5.2 lowered the floor on what bulk slide generation costs and raised the bar on front-end output quality; the orchestration layer is what decides what actually lands in the final deck.
Sources
- zai-org/GLM-5.2 — official model weights and card — Hugging Face, Zhipu AI
- zai-org/GLM-5 — official GitHub repository and benchmark charts — Zhipu AI
- GLM-5 Technical Report — arXiv
- Z.ai's open-weights GLM-5.2 beats GPT-5.5 on multiple long-horizon coding benchmarks for 1/6th the cost — VentureBeat
- Zhipu AI's stock rockets after Chinese firm makes GLM-5.2 open source — South China Morning Post
- Code Arena: Frontend leaderboard result for GLM-5.2 (Max) — Arena.ai / LMArena
- What is GLM-5.2? Everything You Need to Know — CometAPI
- GLM-5.2 Review (2026): Specs, Benchmarks, Pricing & How It Compares to Claude and GPT-5 — AI for Anything


