How to Use MiMo-V2.5-Pro: Complete Guide to Xiaomi's New 1T MoE Model in 2026
A practical guide to MiMo-V2.5-Pro, Xiaomi's April 2026 1T MoE model. Covers SWE-bench scores, frontier-tier pricing, 1M context, and how it fits document-to-slide workflows.

On April 22, 2026, Xiaomi released MiMo-V2.5-Pro — a 1-trillion-parameter Mixture-of-Experts model that matches frontier-tier benchmark scores at roughly an eighth of Claude Opus 4.6's per-token output cost. A day later, the smaller MiMo-V2.5 omnimodal variant followed, completing what Xiaomi is positioning as the first model family with true cost-parity for high-volume agentic coding workloads.
This guide covers what MiMo-V2.5-Pro actually delivers, where it sits on the price-performance curve against Claude Opus 4.7 and GPT-5.5, and how it changes the economics of document-to-slide pipelines.
What Is MiMo-V2.5-Pro?
MiMo-V2.5-Pro is the flagship of Xiaomi's MiMo family, succeeding the MiMo-V2-Pro that earned attention in early 2026 by appearing anonymously on OpenRouter as "Hunter Alpha" and topping the daily usage charts before Xiaomi revealed the source. The V2.5 generation consolidates two previously separate model lines — the V2-Pro reasoning model and the V2-Omni multimodal model — into a single architecture.
Architecture (per public benchmarks and Xiaomi's positioning):
- Type: Mixture-of-Experts
- Total parameters: 1 trillion
- Active parameters per token: 42 billion
- Context window: 1 million tokens
- Modalities (V2.5): Native image, video, audio, and text understanding
- Modalities (V2.5-Pro): Text-focused agentic reasoning
The two-model family lets users pick the right cost point: V2.5 for omnimodal tasks at 1× token cost, V2.5-Pro for harder reasoning and long-horizon coding at 2× token cost.

Benchmark Performance: Frontier Tier at Bargain Pricing
The headline result is that MiMo-V2.5-Pro lands inside the frontier tier on most agentic and reasoning benchmarks while charging substantially less per token than the closed-source competition. Xiaomi's own benchmark grid spans eight evaluations covering coding, agentic capability, knowledge, and reasoning:
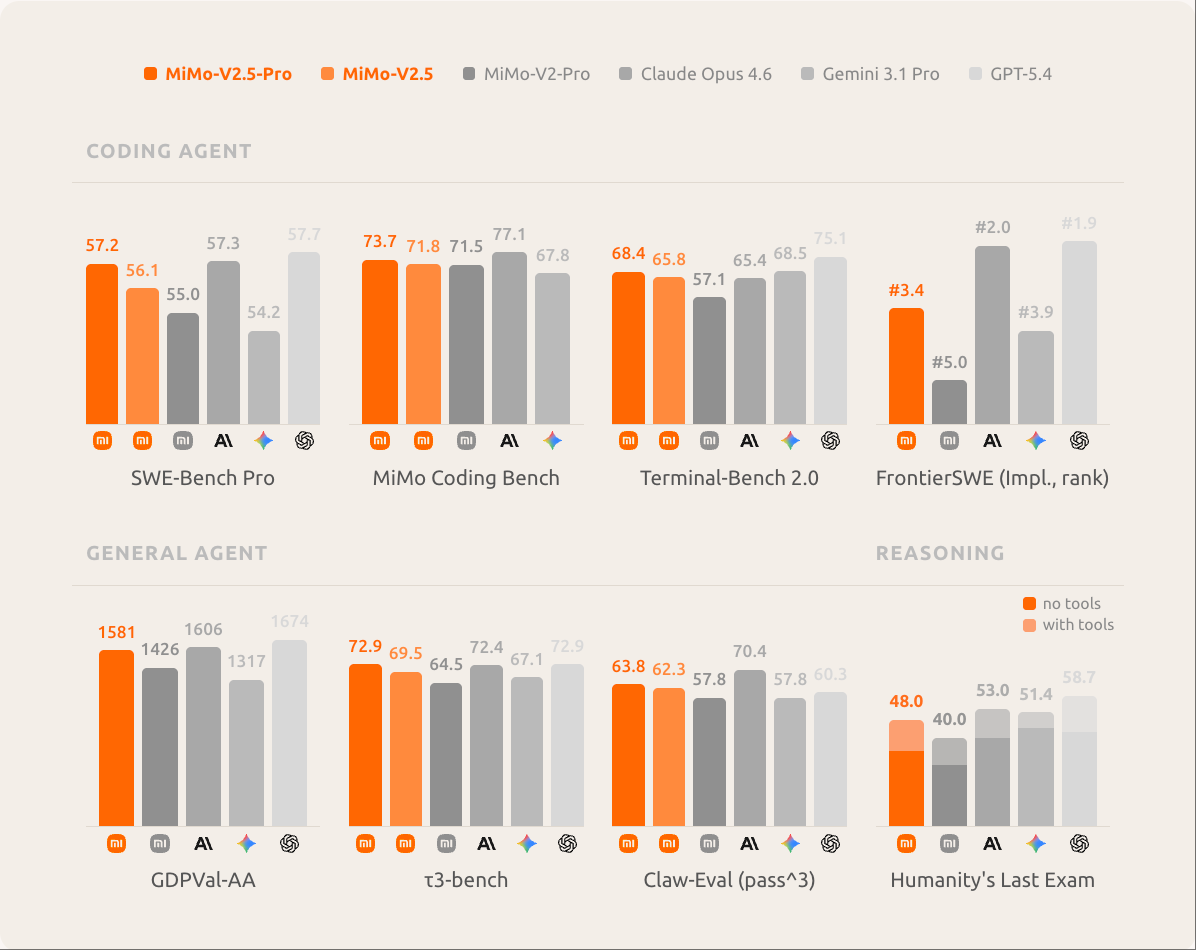
| Benchmark | MiMo-V2.5-Pro | Claude Opus 4.6 | GPT-5.4 |
|---|---|---|---|
| SWE-bench Pro | 57.2% | 53.4% | 57.7% |
| ClawEval Pass³ | 64% (~70K tok/trajectory) | Lower efficiency | Comparable |
| τ³-Bench | 72.9% | — | — |
| τ²-Bench | 94.2% | — | — |
| GPQA Diamond | 86.6% | — | — |
| TerminalBench Hard | 43.2% | — | — |
| IFBench (instruction following) | 79.9% | — | — |
| Humanity's Last Exam | 33.8% | — | — |
| SciCode | 50.2% | — | — |
On the Artificial Analysis Intelligence Index v4.0, MiMo-V2.5-Pro scores 54 — placing it #8 of 144 tracked models, well above the median for its price tier. Output speed is 60.6 tokens per second; time-to-first-token is 2.79 seconds.
The Pareto position is what makes the model genuinely interesting. SWE-bench Pro at 57.2% is competitive with GPT-5.4 (57.7%) and ahead of Claude Opus 4.6 (53.4%) — at one-eighth the per-token output cost.
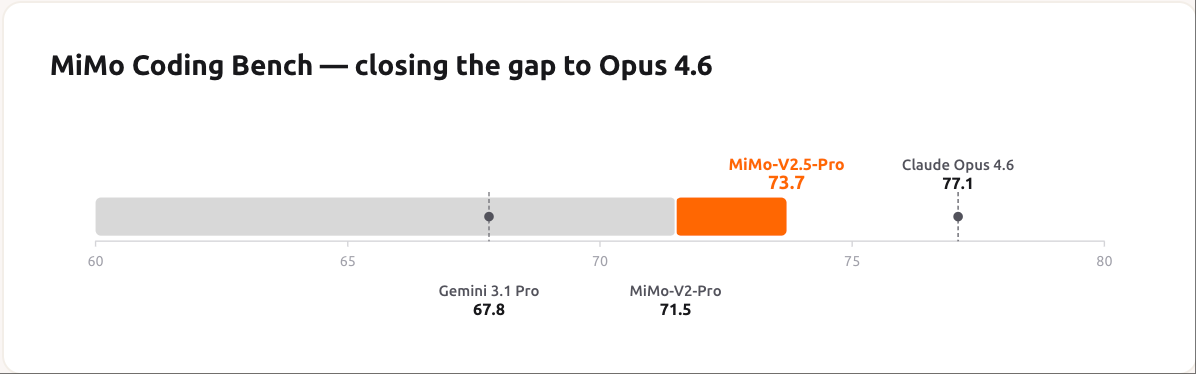
The MiMo Coding Bench result deserves a separate look — it isolates pure coding capability across the same model field and shows MiMo-V2.5-Pro reaching 73.7%, comfortably ahead of the closed-source frontier:
For the omnimodal sibling, MiMo-V2.5 posts:
- Video-MME: 87.7 (vs Gemini 3 Pro's 88.4)
- CharXiv RQ: 81.0
- MMMU-Pro: 77.9
- ClawEval Multimodal: 23.8 (matches Claude Sonnet 4.6)
This is the first time a Chinese open-research lab has shipped a multimodal model with frontier-competitive video understanding.
Pricing: The Real Story
The price differential is large enough to change procurement decisions:
| Model | Input | Output |
|---|---|---|
| MiMo-V2.5 | $1.00 / 1M tokens | $3.00 / 1M tokens |
| MiMo-V2.5-Pro | (2× multiplier on credits) | (2× multiplier on credits) |
| Claude Opus 4.6 | $5.00 / 1M tokens | $25.00 / 1M tokens |
| GPT-5.5 | $5.00 / 1M tokens | $30.00 / 1M tokens |
A 100-million-token monthly output workload costs roughly $300 on MiMo versus $2,500 on Claude Opus 4.6 — an 8× cost advantage at output. For agentic coding pipelines burning tens of millions of output tokens per day, this is the difference between a viable production deployment and a research experiment.
Token Plans no longer charge a separate multiplier for the 1M-token context window, which removes the previous penalty for long-document workflows.
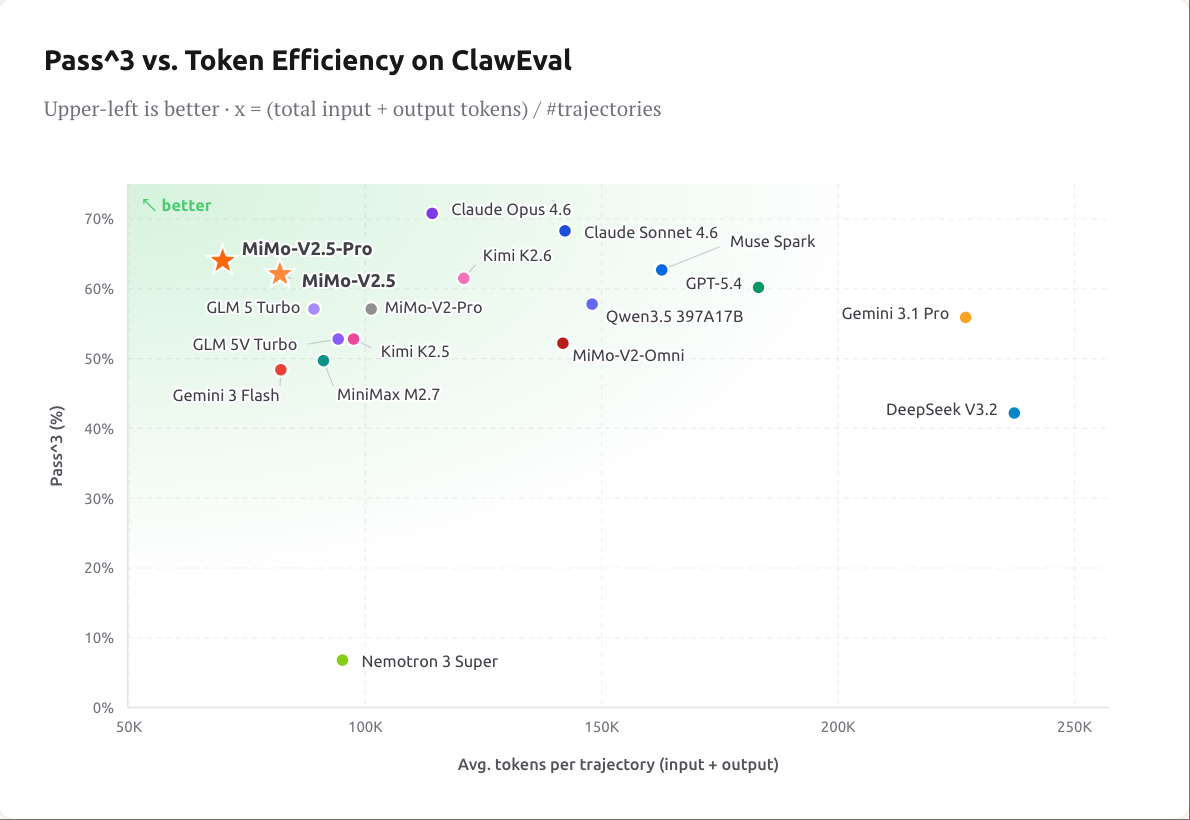
Token Efficiency: The Hidden Multiplier
Beyond the headline pricing, MiMo-V2.5-Pro's reported token efficiency is the multiplier that separates it from naive cost comparisons. Xiaomi claims 40–60% fewer tokens than Claude Opus 4.6, Gemini 3.1 Pro, and GPT-5.4 at comparable capability levels — and 42% fewer tokens than Kimi K2.6 for similar benchmark outcomes.
The mechanism appears to be a combination of harness-aware context management (the model maintains tighter working memory across long tool-use trajectories) and stronger instruction following that reduces the back-and-forth typical of agentic loops. The Pareto plot of pass³ versus token efficiency captures the trade-off cleanly — MiMo sits on the efficiency frontier, achieving comparable accuracy at substantially lower token counts:
Two production demonstrations Xiaomi published illustrate the long-horizon capability:
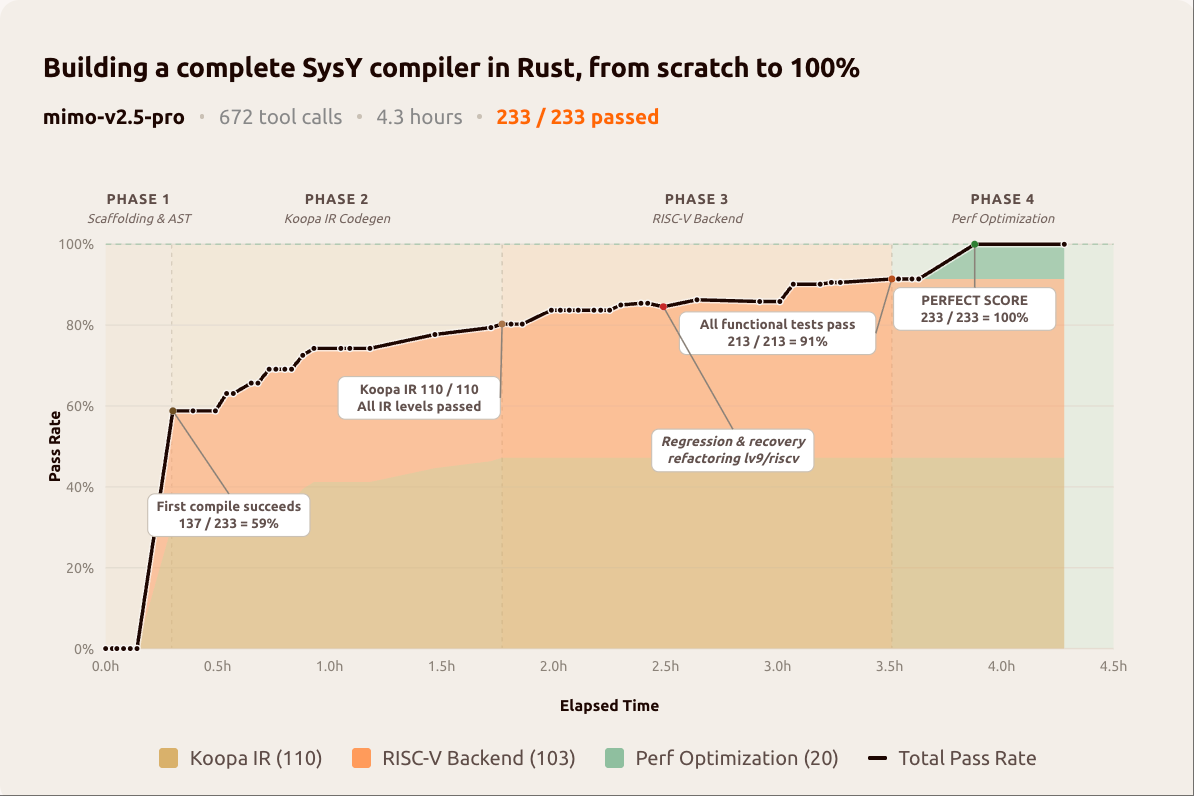
- SysY compiler in Rust: 4.3 hours of autonomous work, 672 tool calls, 233/233 passing on the course's hidden test suite.
- Functional video editor: 8,192 lines of code across 1,868 tool calls and 11.5 hours of autonomous work, producing a multi-track timeline editor with clip trimming, cross-fades, and audio mixing.
The SysY compiler run is striking enough to visualize — the chart below tracks tool-call count and elapsed time as the model worked autonomously through compiler construction:
A second long-horizon demonstration in analog circuit design — FVF-LDO multi-metric optimization — shows the model making 22×, 17×, 9×, and 13× improvements across four engineering metrics over a multi-thousand-tool-call session:
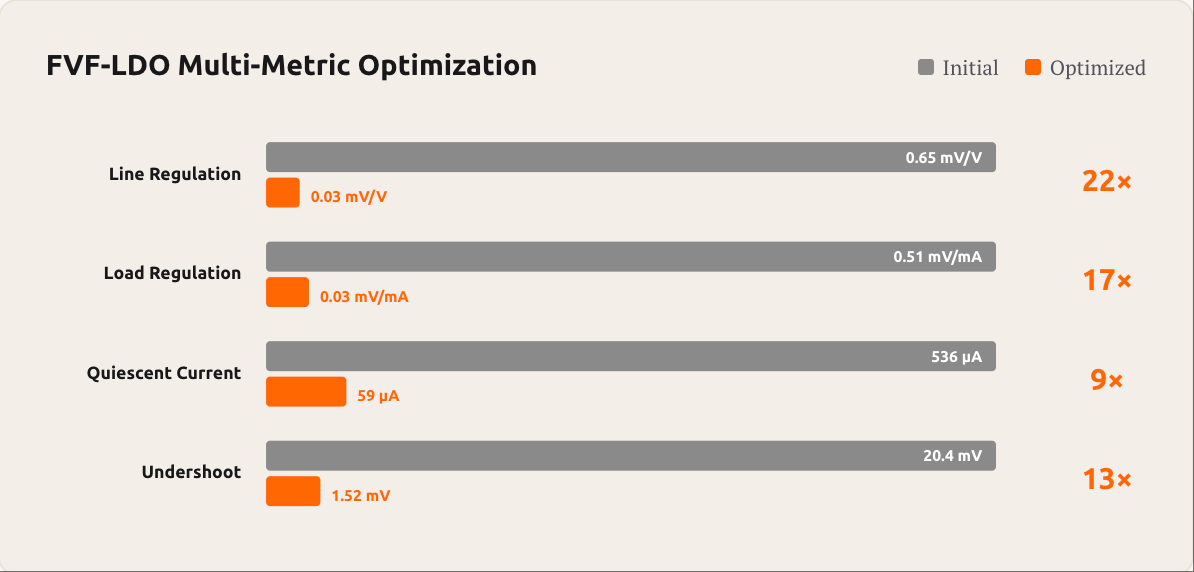
These are not synthetic benchmarks — they are real software and engineering projects completed end-to-end without intervention. The token-efficiency claim becomes concrete when you consider that these multi-thousand-tool-call sessions stayed coherent without ballooning into context exhaustion.
How to Get Access
MiMo-V2.5-Pro is available through three primary channels:
- Xiaomi's AI Studio: aistudio.xiaomimimo.com — interactive playground, no setup
- API Platform: platform.xiaomimimo.com — production API with token plans
- OpenRouter:
xiaomi/mimo-v2.5-pro— pay-as-you-go access integrated with most agent frameworks
The model is also natively integrated with OpenCode, OpenClaw, Claude Code, and Cline — meaning you can swap MiMo into existing agentic coding pipelines without changing your tooling. For an overview of the agent landscape, see our OpenClaw skills guide.
The MiMo-V2.5 series is "soon to be officially open-sourced," following the precedent of MiMo-V2-Flash (309B parameters), which was released under MIT license in December 2025. No specific timeline has been published, but the open-weight release would be the largest open-source MoE model to date.
Where MiMo-V2.5-Pro Wins
Based on the benchmark profile and early production reports:
- High-volume agentic coding — SWE-bench-class workloads where 8× cost reduction matters more than the last 5 points of accuracy
- Long-horizon autonomous workflows — 500+ sequential tool calls with stable context management
- Cost-sensitive multimodal projects — V2.5 is the only model in its price tier with native video understanding
- Self-hosted alternatives — once the open-weight release ships, this becomes the strongest base model for fine-tuning and on-prem deployment
- High-output-volume content generation — anything that consumes >10M output tokens per month
It is not the right pick for:
- Cloud-platform deployment — no AWS Bedrock or Azure Foundry presence
- Regulated industries with US-origin requirements — Chinese model provenance disqualifies it for some compliance frameworks
- Low-volume creative reasoning — for one-off complex prompts where Opus's reasoning depth wins, the 8× cost gap is irrelevant
- English-only nuanced writing — Claude Opus and GPT-5.5 still have an edge on idiomatic English copy
Compared to GPT-5.5 and Claude Opus 4.7
The three frontier-tier launches in April 2026 occupy distinct positions:
| Dimension | GPT-5.5 | Claude Opus 4.7 | MiMo-V2.5-Pro |
|---|---|---|---|
| Strongest benchmark | Terminal-Bench 2.0 (82.7%) | SWE-bench Pro (64.3%) | Token efficiency |
| Pricing (in/out per 1M) | $5 / $30 | $5 / $25 | $1 / $3 |
| Context | 1M | 200K | 1M |
| Hallucination posture | High (86% when wrong) | Low (36%) | Mid-tier |
| Open weights | No | No | Planned |
Decision rule of thumb: GPT-5.5 for the most demanding agentic loops where you can wrap the model in verification. Claude Opus 4.7 for high-stakes single-step tasks where being wrong is expensive. MiMo-V2.5-Pro for everything else at scale — anything where the workload is large enough that the cost differential dominates the benchmark differential.
What MiMo-V2.5-Pro Means for AI Slide Generation
The MiMo-V2.5-Pro release changes the unit economics of AI slide generation at scale. Consider what slide generation actually costs at the model layer: a typical research-paper-to-deck workflow produces ~50K input tokens (the source paper plus prompts) and ~15-25K output tokens (the slide outline, per-slide content, speaker notes, and chart specifications). At Claude Opus 4.6 pricing that's roughly $0.85 per deck. At MiMo-V2.5-Pro pricing, the same deck costs closer to $0.10 — and the token-efficiency claim suggests the actual gap is wider in practice because MiMo produces equivalent quality with fewer output tokens.
For high-throughput document-to-PPT pipelines — institutional research teams generating dozens of decks per week, consulting firms producing client-ready presentations from analyst reports, or edtech products converting course materials into lecture slides — that 8× output-cost reduction is the difference between an experimental feature and a sustainable product. It also opens room for richer per-slide reasoning: at 12% of the cost, a pipeline can afford to run two or three reasoning passes per slide for self-checking, exactly the verification scaffolding that improves slide quality.
At Tosea.ai, the document-to-PPT orchestration layer treats the model as a swappable component — a slide outline generated by GPT-5.5, refined by Claude for stylistic consistency, and rendered at scale by MiMo for high-volume runs is a realistic production pattern. The presentation workflow stays the same; the model assignment shifts based on the cost-quality tradeoff each step actually demands. For practitioners building this kind of pipeline, the research-paper-to-slides workflow and massive slide deck guide cover the orchestration patterns in detail.
The harder strategic point: an open-weight 1T MoE released under a permissive license would let teams self-host the entire slide generation pipeline. For institutions with compliance constraints or sensitive source documents, that flips the build-vs-buy calculation in a way no closed-source frontier model can match. The PPT slide deck generation stack of 2027 likely runs on whatever Xiaomi's open-weight release becomes, plus orchestration on top.
FAQ
Is MiMo-V2.5-Pro open source? Not yet, but Xiaomi has committed to an open-weight release. The previous MiMo-V2-Flash (309B params) was released under MIT license in December 2025, suggesting V2.5 will follow the same path.
How does the MoE architecture affect inference? 1T total parameters / 42B active means inference compute and memory are closer to a 42B dense model, while the parameter capacity is 24× larger. This is why the price can be so low — most parameters sit idle on any given token.
Can I use MiMo-V2.5-Pro from outside China? Yes — both the official platform and OpenRouter are accessible internationally. Latency may be higher than US-hosted alternatives depending on your region.
What's the difference between MiMo-V2.5 and MiMo-V2.5-Pro? V2.5 is the omnimodal model (image, audio, video, text) at 1× token cost. V2.5-Pro is text-focused with stronger reasoning and long-horizon agentic capability at 2× cost. For pure coding and reasoning, use Pro. For anything involving video or audio inputs, use V2.5.
Is MiMo-V2.5-Pro suitable for production? Xiaomi has shipped real production demos (SysY compiler, video editor) and OpenRouter usage data shows ~21% of OpenRouter traffic flowing to MiMo models in early April. For high-volume production pipelines, yes — with the same caveat that applies to all model deployments: wrap with verification.
Closing Thought
MiMo-V2.5-Pro is the most important AI model release of April 2026 — not because it has the highest benchmark on any single chart, but because it changes the cost surface that every other model is competing on. When a model with frontier-comparable scores ships at one-eighth the output cost, the entire price-performance frontier shifts. The strategic question for the next twelve months is not "which model is best?" but "which workloads can MiMo's economics absorb that were previously gated by closed-source pricing?"
For agentic coding at scale, document-to-PPT pipelines, and any workflow where output volume is the dominant cost, the answer increasingly looks like "all of them."
Sources
- MiMo-V2.5-Pro Official Page — Xiaomi, April 22, 2026
- Xiaomi Releases MiMo-V2.5-Pro and MiMo-V2.5: Matching Frontier Model Benchmarks at Significantly Lower Token Cost — MarkTechPost
- Xiaomi stuns with new MiMo-V2-Pro LLM nearing GPT-5.2, Opus 4.6 performance at a fraction of the cost — VentureBeat
- Xiaomi MiMo-V2.5-Pro: Full Review & Benchmarks — BuildFastWithAI
- MiMo-V2.5-Pro — Intelligence, Performance & Price Analysis — Artificial Analysis
- Xiaomi MiMo V2.5 Pro: 1M-Token Multimodal AI Model — GNCrypto
- Xiaomi: MiMo-V2.5-Pro Review — Pricing, Benchmarks & Capabilities — Design For Online


