How to Use DeepSeek V4: Complete Guide to the New 1T MoE Model in 2026
A practical guide to DeepSeek V4, the April 2026 release of the 1T-parameter MoE model with Engram memory, 1M context, and the lowest token pricing of any frontier-tier model.

In late April 2026, DeepSeek replaced its deepseek-chat and deepseek-reasoner endpoints with two new models: deepseek-v4-flash and deepseek-v4-pro. The launch ends six months of speculation about V4 — and confirms most of what the leaks predicted: a Mixture-of-Experts architecture scaling to 1.6 trillion parameters at the Pro tier, a 1-million-token context window backed by the new Engram conditional memory system, and pricing that undercuts every other frontier-tier model by an order of magnitude.
This guide walks through what DeepSeek V4 actually ships with, how the two-tier model split changes deployment decisions, and where it fits in the document-to-slide pipeline against GPT-5.5 and MiMo-V2.5-Pro.
What Is DeepSeek V4?
DeepSeek V4 is the fourth-generation flagship from the Hangzhou-based research lab, succeeding DeepSeek V3 (671B parameters, $5.6M training cost on 14.8T tokens). The two models exposed at launch are positioned for very different cost-quality tradeoffs — and crucially, they are not the same model at different price points. They have different parameter counts, different active-parameter footprints, and different intended workloads:

- deepseek-v4-flash — the volume model at 284B total parameters / 13B active per token, pretrained on 32T tokens. Replaces both
deepseek-chat(the V3.5 generalist) anddeepseek-reasoner(the V3.2-Speciale reasoning variant). Single endpoint, "Instant Mode" inference. - deepseek-v4-pro — the premium tier at 1.6T total parameters / 49B active per token, pretrained on 33T tokens. "Expert Mode" inference with the strongest reasoning ceiling, intended for the hardest agentic and analytical workloads.
Both models share:
- Architecture: Mixture-of-Experts (parameter counts above)
- Context window: 1 million tokens
- Maximum output: 384,000 tokens
- Memory system: Engram conditional memory
- Modalities: Native text, image, and video (multimodal pre-training, not bolt-on)
- Reasoning modes: Both non-thinking and thinking (default), switchable per request
- Tool use: JSON output, function calling, chat prefix completion (beta)
- API surface: OpenAI-compatible at
api.deepseek.comand Anthropic-compatible atapi.deepseek.com/anthropic - Open-source: Both tiers planned for Apache 2.0 release following the API launch
The 5.6× parameter spread between Flash and Pro is wider than any other frontier-tier vendor's tier split — it is closer in spirit to OpenAI's GPT-5.5 vs GPT-5.5 Pro relationship than to a simple "small" / "large" pairing. Flash is a genuinely different model architecture optimized for cost; Pro is the capability-ceiling model.
Pricing: The Most Aggressive Frontier-Tier Pricing Ever
The pricing is the headline. At full price, DeepSeek V4-Flash is roughly 18× cheaper than GPT-5.5 on input and 107× cheaper on output — for a model that, on internal benchmarks, claims comparable performance.
| Model | Input (cache hit) | Input (cache miss) | Output |
|---|---|---|---|
| deepseek-v4-flash | $0.028 / 1M | $0.14 / 1M | $0.28 / 1M |
| deepseek-v4-pro | $0.145 / 1M | $1.74 / 1M | $3.48 / 1M |
| GPT-5.5 | — | $5.00 / 1M | $30.00 / 1M |
| Claude Opus 4.7 | — | $5.00 / 1M | $25.00 / 1M |
| MiMo-V2.5 | — | $1.00 / 1M | $3.00 / 1M |
A workflow that costs $300 on MiMo-V2.5 and $3,000 on Claude Opus 4.7 costs roughly $28 on DeepSeek V4-Flash. With cache hits factored in, the marginal cost of repeated similar queries drops by another 5×.
The cache-hit pricing matters more than it looks. DeepSeek's KV cache reuse across similar prompts — common in agentic loops, RAG pipelines, and document analysis where the same source context appears across many queries — means real-world costs sit much closer to the cache-hit number than the cache-miss number.
Architecture: Engram, mHC, and Sparse Attention
DeepSeek V4 introduces three architectural innovations that together explain how the model can ship at this price point with frontier-tier performance.

Engram: Conditional Memory
Engram is a dual-pathway system that separates static knowledge retrieval (factual lookup) from dynamic reasoning (compute over working memory). The published research suggests an optimal allocation of 20–25% of model capacity to memory and 75–80% to reasoning compute. Knowledge patterns are handled via O(1) hash lookups against embedding tables; reasoning flows through the MoE backbone.
The reported gains are substantial. On the 27B research model that introduced Engram:
- MMLU: +3.4 points
- BBH: +5.0 points
- HumanEval: +3.0 points
- Multi-Query Needle-in-a-Haystack at 1M tokens: 84.2 → 97.0
The NIAH improvement is the load-bearing one for long-context applications. Standard transformer attention degrades sharply past 200K tokens; Engram's separation of retrieval from reasoning pushes reliable recall to nearly the full 1M-token window.
Manifold-Constrained Hyper-Connections (mHC)
mHC is the trick that makes 1T-parameter training stable at DeepSeek's compute budget. Standard hyper-connections amplify signal magnitude by ~3,000× across deep networks, which is the dominant source of training instability at trillion-scale. mHC constrains amplification to under 2× using Birkhoff Polytope projection, with a 6.7% training overhead.
The benchmark progression on BBH is illustrative: baseline 43.8 → unconstrained HC 48.9 → mHC 51.0. Without mHC, V4-scale training would either diverge or require substantially more compute to stabilize.
DeepSeek Sparse Attention
The "Lightning Indexer" reduces long-context compute by approximately 50% by routing attention through a learned sparse pattern rather than full quadratic attention. This is what makes the 1M context window economically viable at the published price point — full quadratic attention over 1M tokens would consume orders of magnitude more compute per query.
Benchmark Performance
The leaked and now-confirmed benchmark numbers position V4 inside the frontier tier, with the strongest gains on coding and long-context tasks. The published comparison sets V4-Pro and V4-Flash against the other April 2026 frontier releases:
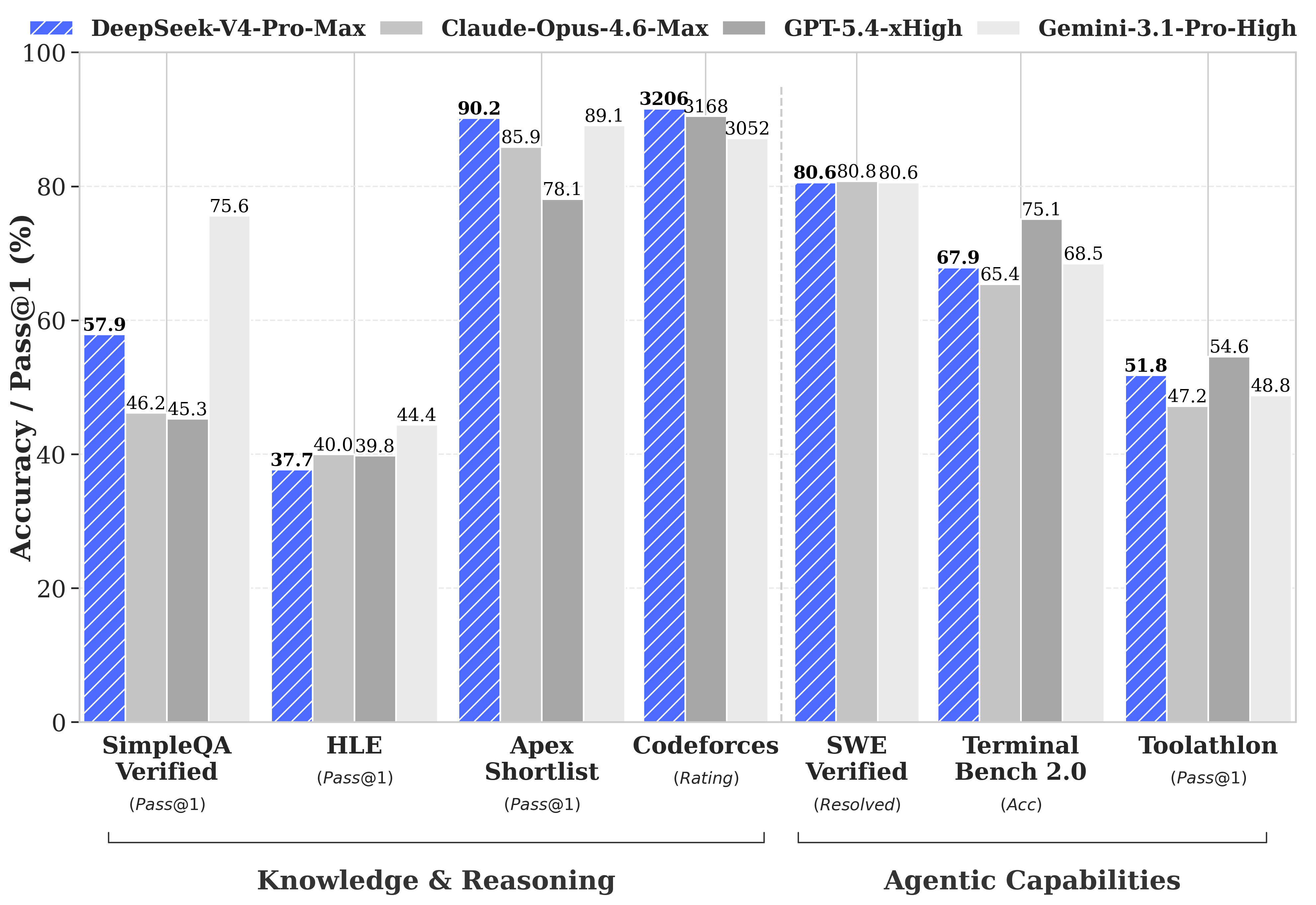
The full benchmark table — including the smaller V4-Flash tier and the open-source comparison set — gives a more complete view of where V4 lands across the model landscape:
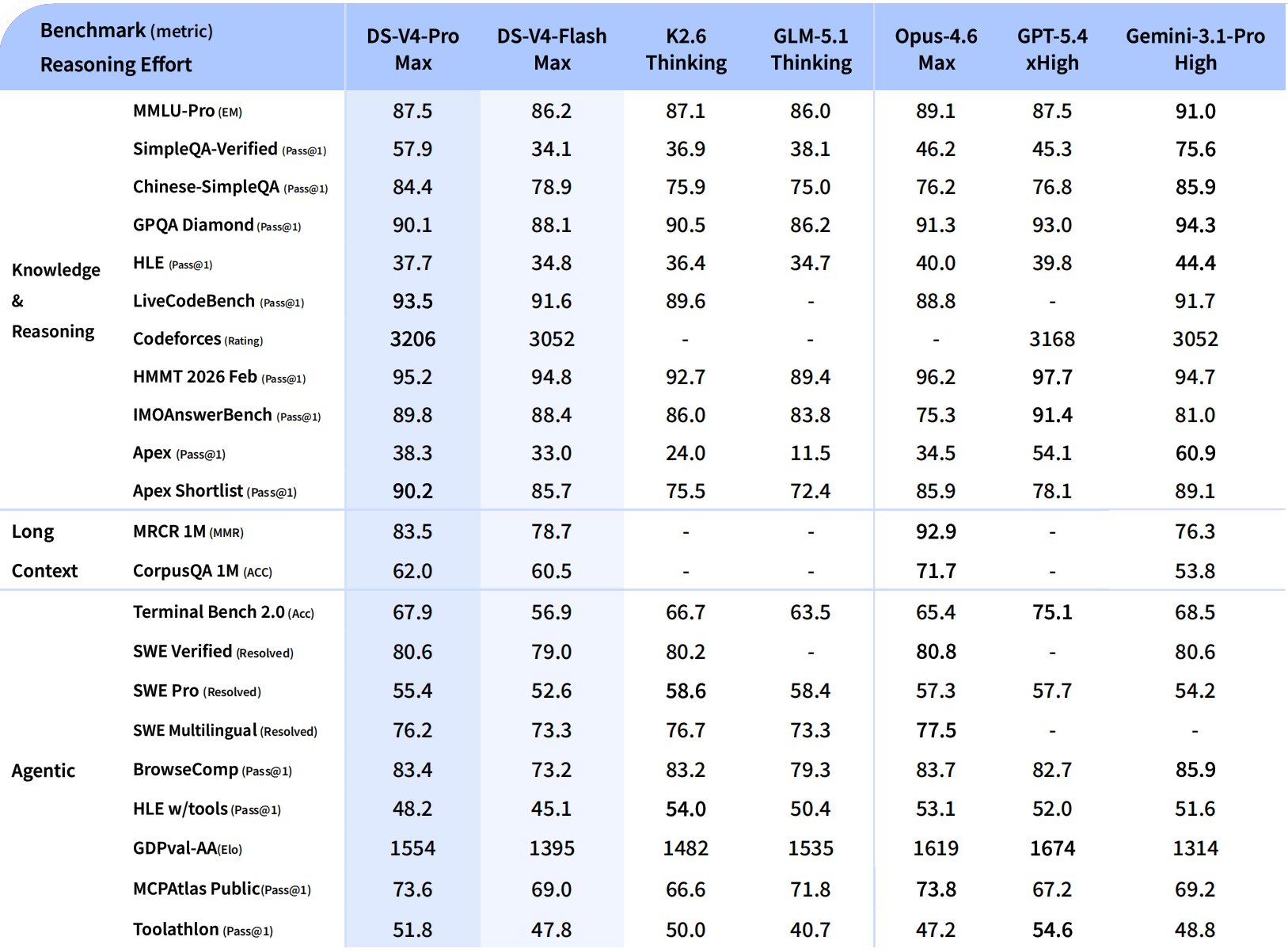
| Benchmark | DeepSeek V4 (claimed) | Comparison |
|---|---|---|
| HumanEval | ~90% | Matches Claude Opus 4.6 |
| SWE-bench Verified | ~81% | Above DeepSeek V3.2-Speciale (67.8%) |
| Multi-Query NIAH at 1M tokens | 97.0 | Standard attention: 84.2 |
| Context window | 1M tokens | V3: 128K |
| Active parameters (Pro) | 49B / 1.6T total | V3: 37B / 671B total |
| Active parameters (Flash) | 13B / 284B total | New tier — no V3 equivalent |
Important caveat: the SWE-bench and HumanEval numbers come from internal benchmarks. Independent third-party evaluations are still rolling in across the first few weeks of the release. Treat the numbers as DeepSeek's own claim until cross-validated by independent reviewers, the same way the early Claude Opus 4.7 SWE-bench result drew memorization questions until reproduced.
For use cases that depend on long-context reliability — multi-document research, codebase-scale analysis, full-PDF summarization — the NIAH improvement is the result that matters most, and is the easiest to reproduce independently.
Hardware: The Huawei Ascend Pivot
DeepSeek V4 is the first DeepSeek flagship trained primarily on Huawei Ascend 950PR chips and Cambricon MLUs, with limited Nvidia involvement. This is partly export-control adaptation (Nvidia H100 and H200 access has been constrained for Chinese labs since late 2024) and partly a strategic bet on the maturing domestic accelerator stack.
For inference, the published quantization options target the V4-Flash tier:
- INT8 quantization: 2× Nvidia RTX 4090 (48GB VRAM total) for V4-Flash
- INT4 quantization: 1× Nvidia RTX 5090 (32GB VRAM) for V4-Flash
These numbers are striking. V4-Flash's 13B active / 284B total profile fits on a single RTX 5090 at INT4 — the most efficient inference profile of any frontier-tier model in 2026. The MoE architecture is what makes this possible: only 13B parameters are active per token at the Flash tier, so the actual compute footprint resembles a 13B dense model even though the weight footprint sits at 284B. V4-Pro at 1.6T total is targeted at multi-GPU server deployments; consumer-hardware quantization recipes for the Pro tier have not yet been published.
How to Get Access
The API is live at two endpoints:
- OpenAI-compatible:
https://api.deepseek.com/v1/chat/completionswithmodel: deepseek-v4-flashormodel: deepseek-v4-pro - Anthropic-compatible:
https://api.deepseek.com/anthropicfor users migrating from Claude
The Anthropic-compatible endpoint is a meaningful detail — it lets teams move existing Claude integrations to DeepSeek V4 without rewriting client code. For agentic frameworks built on the Anthropic SDK (Claude Code, Anthropic's tool-use patterns), this is roughly a one-line change.
The web chat at chat.deepseek.com defaults to V4-Flash with thinking mode enabled. Free for personal use, with throughput limits.
The Apache 2.0 weight release timeline has not been published officially, but historical pattern (V2: 2 months after API launch, V3: 6 weeks) suggests open weights by mid-summer 2026.
Where DeepSeek V4 Wins
- Cost-bounded high-volume workloads — anything where token cost dominates the deployment math, V4-Flash is now the default reasonable choice
- Long-context document analysis — the Engram-backed 1M context with 97% NIAH is the strongest long-context profile available
- Multilingual reasoning — DeepSeek V3 was already strong on Chinese and competitive on multilingual benchmarks; V4 widens the lead
- Cache-friendly RAG pipelines — the 5× cache-hit discount makes V4-Flash extremely well-suited to retrieval-heavy workflows
- Self-hosted production deployments — once open weights ship, the inference economics on consumer hardware are unmatched
- Migration from Claude or OpenAI — the dual API compatibility lets teams A/B test without code changes
It is not the right pick for:
- Production English creative writing where Claude's stylistic edge still matters
- Cutting-edge agentic workflows where the model needs to chain hundreds of tool calls — Terminal-Bench-class tasks where GPT-5.5 still leads
- Regulated industries with US-origin requirements — Chinese provenance disqualifies V4 for some compliance frameworks
- Workflows requiring third-party cloud integration — no AWS Bedrock or Azure Foundry presence
Compared to GPT-5.5 and MiMo-V2.5-Pro
April 2026's three frontier launches occupy distinct ground:
| Dimension | GPT-5.5 | MiMo-V2.5-Pro | DeepSeek V4-Flash |
|---|---|---|---|
| Strongest pitch | Agentic ceiling | Open-weight 1T MoE | Lowest cost |
| Output pricing | $30 / 1M | $3 / 1M | $0.28 / 1M |
| Context | 1M | 1M | 1M (Engram-backed) |
| Hallucination | High (86%) | Mid | Low–Mid (Engram helps) |
| Open weights | No | Planned | Planned (Apache 2.0) |
| Self-hostable | No | Eventually | Yes — single GPU at INT4 |
The decision rule has shifted. Through 2025 the practical choice for most teams was "Claude or GPT." Through Q1 2026 the choice was "Claude, GPT, or DeepSeek V3 if you can absorb the latency." With V4-Flash live, the question for a substantial fraction of workloads is now "DeepSeek V4 unless there's a specific reason not to."
What DeepSeek V4 Means for AI Slide Generation
DeepSeek V4 changes the document-to-PPT pipeline economics more than any prior model release. Three properties combine to make this the case:
1. Long-context reliability via Engram. A typical research-paper-to-deck workflow ingests 30–80 pages of source material plus prompts, often pushing past the 200K-token degradation point of standard attention models. The 97% NIAH score at 1M tokens means V4 can reliably recall specific facts from anywhere in a multi-document bundle when generating slide content — directly addressing the "the model cited a number that isn't in the source" failure mode that breaks slide credibility.
2. Cache-hit pricing for repeated source contexts. Document-to-PPT generation repeatedly references the same source — once for the outline, once per slide for content, once per slide for speaker notes. With V4-Flash's $0.028 / 1M cache-hit input pricing, a 50K-token research paper used across 25 slide-generation calls costs roughly $0.04 of input tokens versus several dollars on closed-source frontier models.
3. Multimodal native ingestion. Native image and video understanding means V4 can read figure captions, table images, and diagram alt text directly from a source PDF without a separate OCR or vision pre-processing step. This is the same capability gap that GPT Image 2 addresses on the generation side, but applied to consumption.
For the AI presentation tool category broadly, this lowers the floor on what "frontier-quality slide generation" costs to deliver. At Tosea.ai, the document-to-deck orchestration treats each model as a swappable component — V4-Flash for high-volume PDF-to-PowerPoint conversion, GPT-5.5 for the most demanding multi-step reasoning tasks, Claude Opus for stylistic polish. The slide structure stays the same; the model assignment shifts based on the cost-quality tradeoff each step demands. For more on the orchestration patterns, see our zero-hallucination AI slide generation guide, the convert PDF to PowerPoint guide, and the massive slide deck guide.
The strategic implication for any team building presentation workflows: the model layer is now commoditized. Differentiation lives in the orchestration — how source documents are chunked and grounded, how slide structure is enforced, how each generated claim is traced back to its source paragraph. The model is no longer the bottleneck; the document-to-PPT pipeline architecture is.
FAQ
Has DeepSeek V4 actually launched?
Yes. As of late April 2026 the API docs at api-docs.deepseek.com/quick_start/pricing list deepseek-v4-flash and deepseek-v4-pro as the current models, with deepseek-chat and deepseek-reasoner deprecated to point at V4-Flash.
How does the cache-hit discount work? DeepSeek's KV cache stores the prefix of recent prompts. When a new request shares a prefix with a cached one, the cached portion is billed at the cache-hit rate (~5× cheaper). This makes V4-Flash extremely cost-effective for agentic loops where the same system prompt and tool definitions repeat.
Can I run DeepSeek V4 locally? Open weights have not yet been released, but the Apache 2.0 plan is published. Once weights ship, INT4 quantization is targeted to fit on a single RTX 5090.
What about thinking mode? Both V4-Flash and V4-Pro support thinking and non-thinking modes, switchable per request. Default is thinking (the V3.2-Speciale behavior). Non-thinking mode is roughly 4× faster but loses the chain-of-thought benefit on reasoning tasks.
How does V4 compare to V3 for coding? The claimed SWE-bench Verified jump from V3.2-Speciale's 67.8% to V4's ~81% is the most significant single capability gain in the release. For coding-heavy workloads, V4-Pro is a meaningful upgrade.
Does V4 work with Claude Code?
Yes — the Anthropic-compatible endpoint at api.deepseek.com/anthropic lets Claude Code use V4 with a single base-URL change. See our Claude Code complete guide for setup details.
Closing Thought
DeepSeek V4's arrival completes April 2026's three-way frontier reset. GPT-5.5 raises the agentic ceiling, MiMo-V2.5-Pro changes the price-performance frontier for high-volume workloads, and DeepSeek V4 collapses the cost floor by another order of magnitude while shipping the strongest long-context profile of any model in production. The next twelve months will be defined by what teams build now that frontier-tier model access costs cents per million tokens rather than dollars.
For document-heavy workloads — research synthesis, slide generation, technical writing, codebase analysis — the constraint is no longer the model. It is the orchestration on top.
Sources
- DeepSeek API Pricing — Models & Pricing Page — DeepSeek, April 2026
- DeepSeek V4 (2026): 1T Parameters, 81% SWE-bench, $0.30/MTok — Full Specs — NxCode
- DeepSeek V4 Guide: Engram Memory, Training Data Strategy & Release Status — Kili Technology
- DeepSeek V4: Release Date, Specs, and the Huawei Chip Bombshell — FindSkill
- DeepSeek V4 Targets Late April Launch With Trillion-Parameter MoE — China Biz Insider
- Leaked DeepSeek V4 Benchmarks Reveal a Massive 1-Million Token Context Window — Geeky Gadgets
- DeepSeek V4 Is Coming: 1 Trillion Parameters, Open Source, and Running on Huawei Chips — Remio


