How to Use GPT-5.5: Complete Guide to OpenAI's New Agentic Model in 2026
A practical guide to GPT-5.5, OpenAI's April 2026 fully retrained agentic model. Covers benchmarks, agentic coding, 1M context, and how to use it in document and slide workflows.

On April 23, 2026, OpenAI released GPT-5.5 — described in the launch as the company's first fully retrained base model since GPT-4.5. It is a single agentic system designed to take long sequences of actions, use tools, browse the web, write code, and check its own work without handoff. Within twenty-four hours it took the top spot on the Artificial Analysis Intelligence Index, edging past Claude Opus 4.7 and Gemini 3.1 Pro Preview.
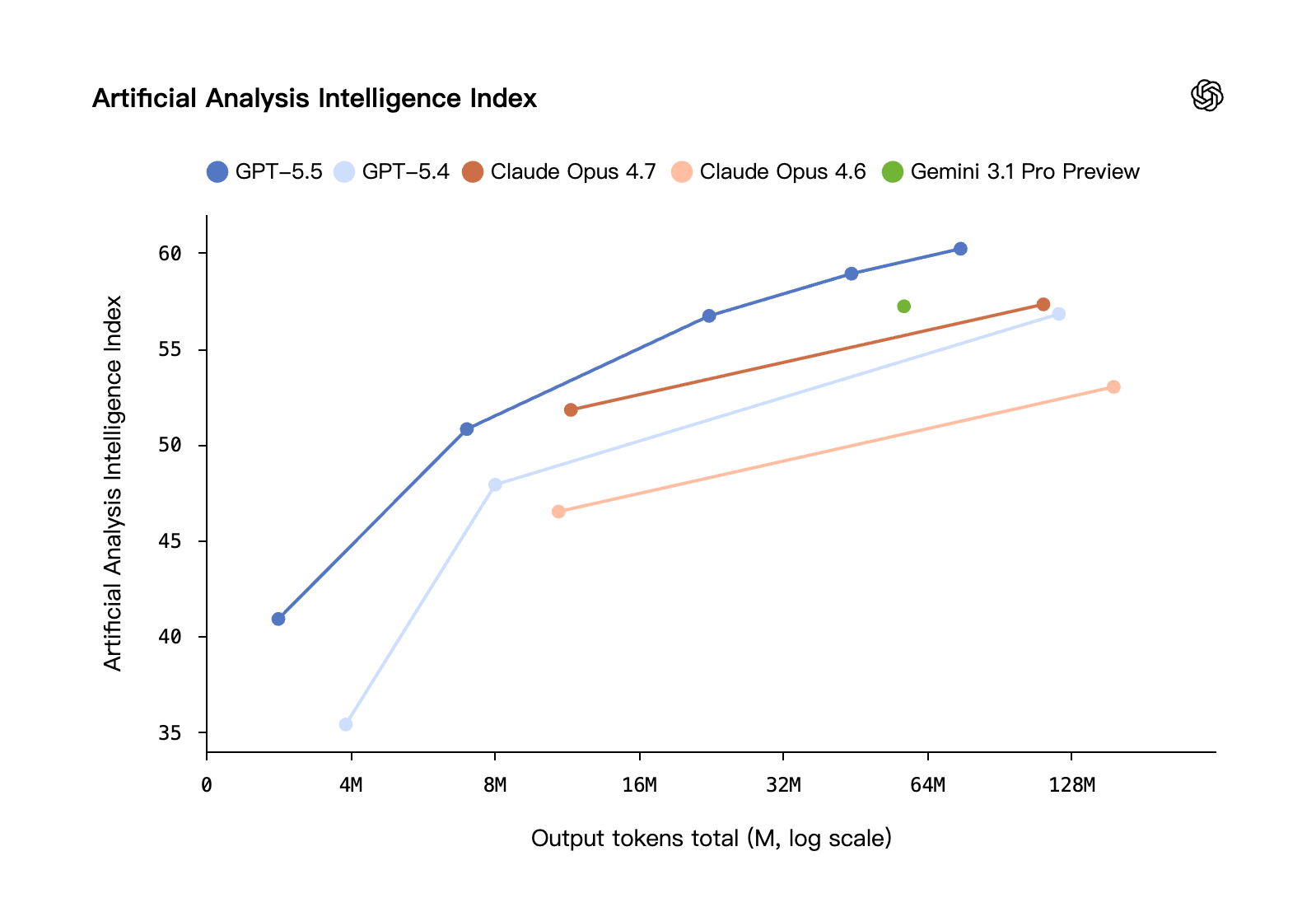
This guide unpacks what GPT-5.5 actually changes — what the benchmarks say, what the pricing looks like, where it is genuinely better than the competition, and where the cracks show. It then walks through the workflows where the new model is most useful, including document analysis and slide generation.
What Is GPT-5.5?
GPT-5.5 is the successor to GPT-5.4 and the headline release of OpenAI's spring 2026 model cycle. The framing in the launch post is unusually clean: this is an agentic model first, a chat model second. OpenAI focused training on four concentration domains — agentic coding, computer use, knowledge work, and early scientific research — and the benchmarks reflect those priorities.
The model is rolling out immediately to Plus, Pro, Business, and Enterprise subscribers in ChatGPT, with API access following shortly after. There are two variants exposed at launch:
- GPT-5.5 — the standard model, with reasoning effort levels
xhigh,high,medium,low, andnon-reasoning - GPT-5.5 Pro — a higher-compute variant that pushes harder on long-horizon tasks (BrowseComp, FrontierMath Tier 4)
Both share the same 1 million token context window and the same multimodal input surface (text plus vision). Computer-use screen reading is exposed through Codex, where roughly four million developers are now active each week.
Benchmark Results: Where GPT-5.5 Actually Leads
The launch benchmarks tell a coherent story. GPT-5.5 wins decisively on agentic and computer-use evaluations, edges ahead on knowledge-work tasks, and trades blows with Claude Opus 4.7 on raw coding metrics.
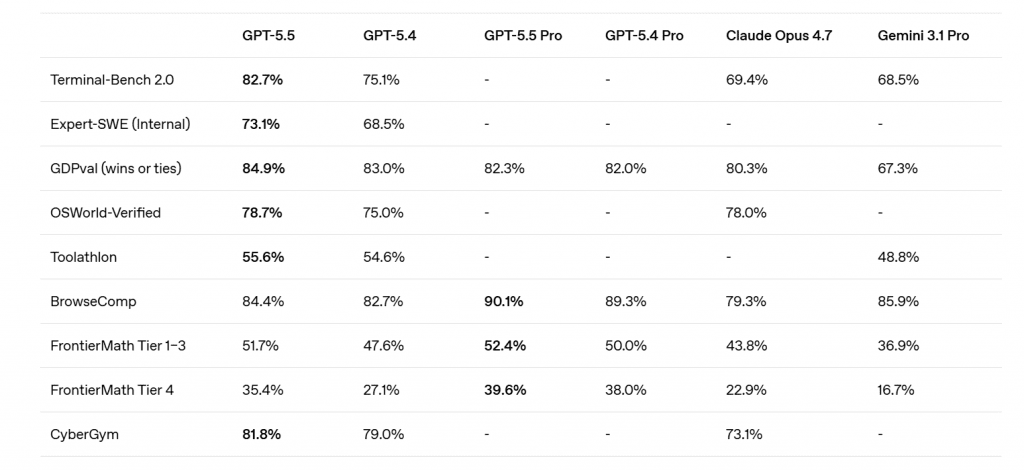
The standout numbers from OpenAI's own benchmark table:
| Benchmark | GPT-5.5 | GPT-5.4 | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|---|
| Terminal-Bench 2.0 | 82.7% | 75.1% | 69.4% | 68.5% |
| Expert-SWE (internal) | 73.1% | 68.5% | — | — |
| GDPval (wins or ties) | 84.9% | 83.0% | 80.3% | 67.3% |
| OSWorld-Verified | 78.7% | 75.0% | 78.0% | — |
| BrowseComp | 84.4% | 82.7% | 79.3% | 85.9% |
| FrontierMath Tier 1–3 | 51.7% | 47.6% | 43.8% | 36.9% |
| CyberGym | 81.8% | 79.0% | 73.1% | — |
Three observations worth flagging:
1. Terminal-Bench 2.0 is the most decisive win. The 82.7% score sits roughly 13 points ahead of Anthropic's Claude Opus 4.7 and Gemini 3.1 Pro, and 7.6 points ahead of GPT-5.4. Terminal-Bench is the closest public proxy for "can this model finish a real software engineering task end-to-end without hand-holding," and a 13-point lead at this end of the curve is unusual.
2. GDPval matters more than it looks. This benchmark tests output quality across 44 occupations against industry professionals. GPT-5.5 wins or ties 84.9% of the time, which is what OpenAI is actually selling — knowledge-work parity with a domain expert. For a $5 / $30 model that's the strongest commercial pitch.
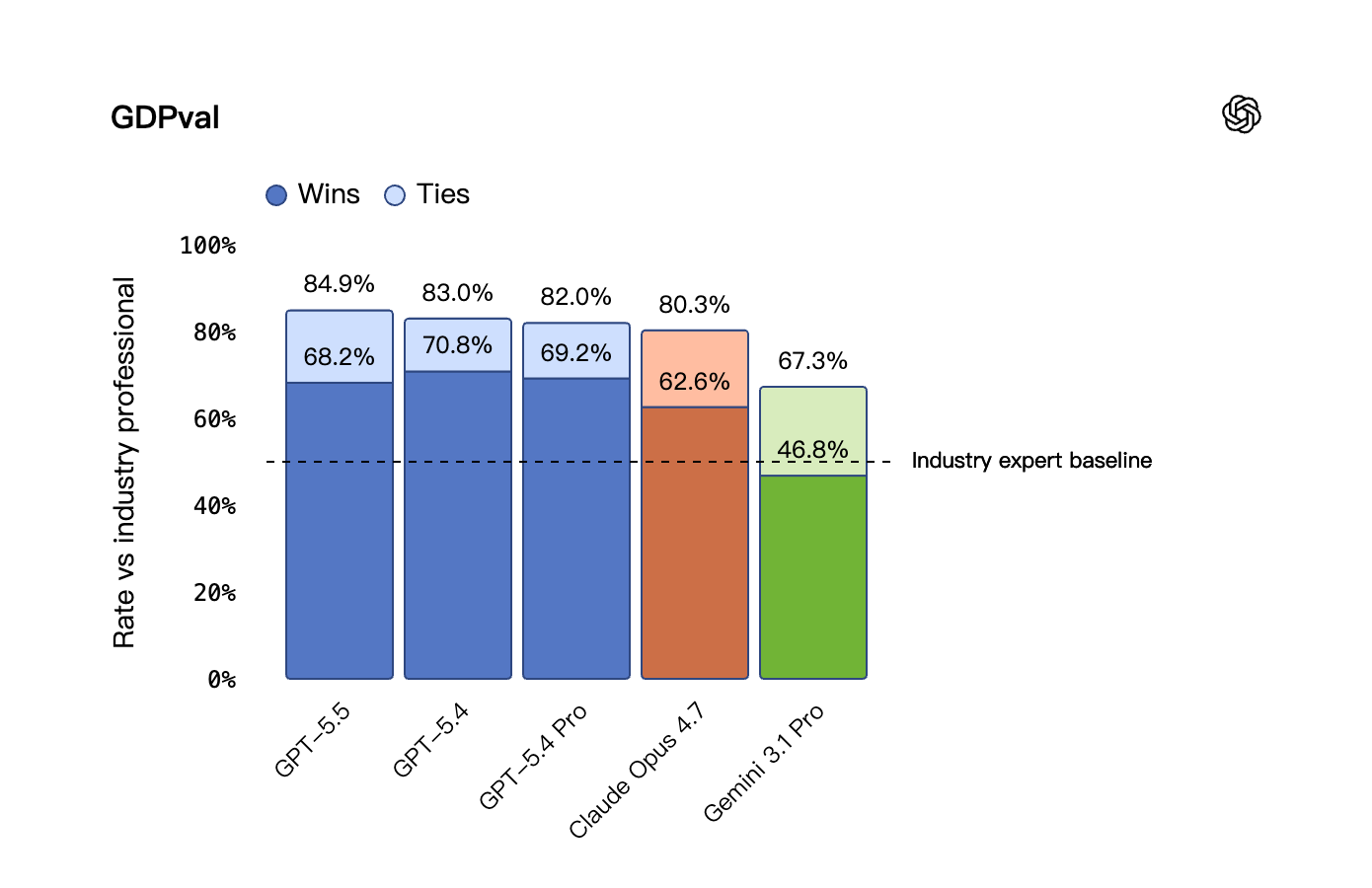
3. SWE-bench Pro is a draw. GPT-5.5 scores 58.6% on SWE-Bench Pro versus Claude Opus 4.7's 64.3%, and there are open questions in the developer community about training-set memorization on this benchmark. Treat the Opus lead here with some skepticism — but also do not assume GPT-5.5 has erased Anthropic's coding edge.
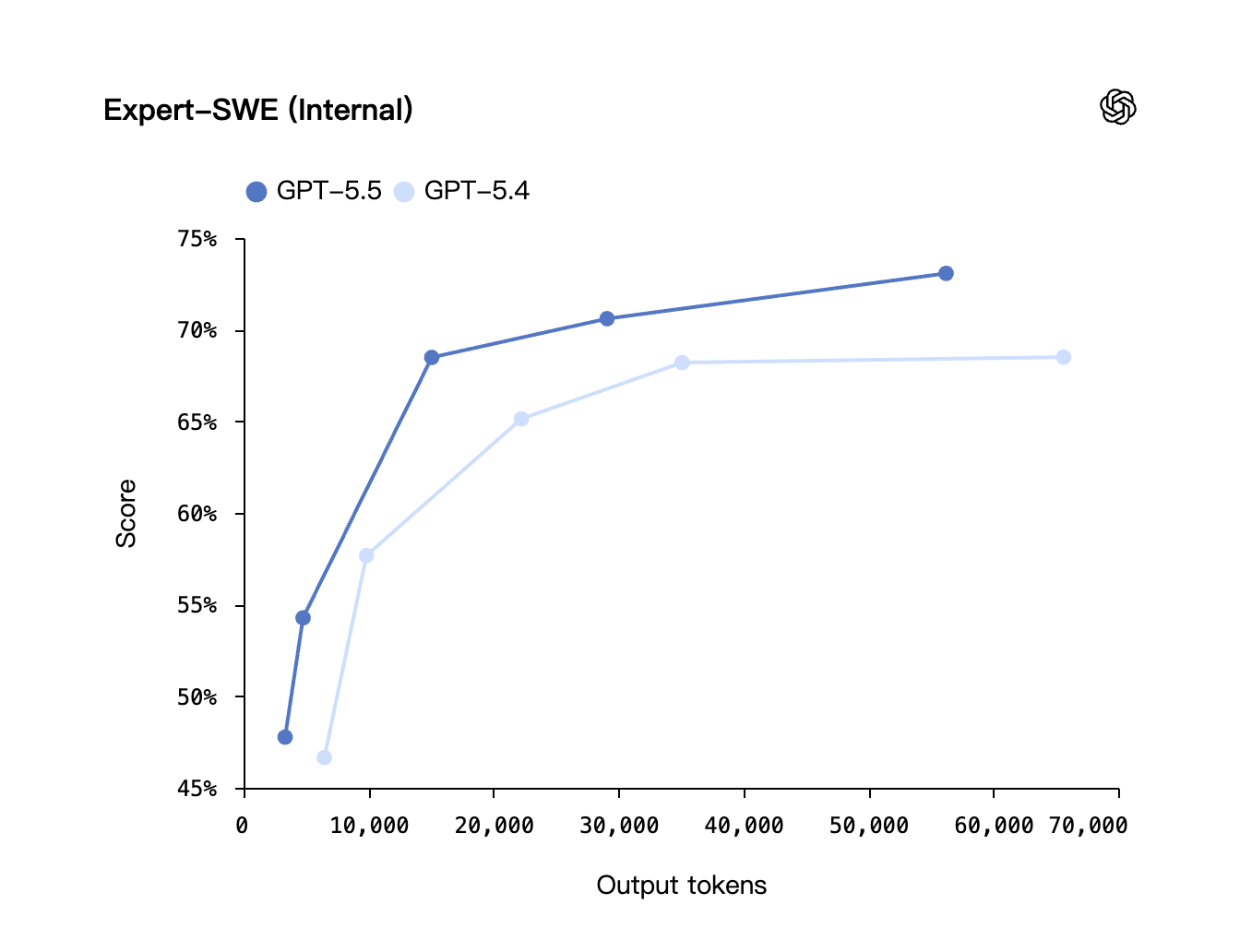
OpenAI's internal Expert-SWE benchmark — which tests against the kind of multi-file, multi-step changes professional engineers handle in production — shows GPT-5.5 reaching 73% versus GPT-5.4's roughly 68%, an honest single-model-generation jump:
For raw category scores on the BenchLM verified leaderboard, GPT-5.5 ranks #2 of 16 models overall, with a 99.2/100 agentic score, perfect 100/100 reasoning, and 79.6/100 coding.
Pricing: Double the Per-Token Cost, Cheaper in Practice
OpenAI raised the headline per-token rates with GPT-5.5:
| Model | Input | Output |
|---|---|---|
| GPT-5.5 (Standard) | $5 / 1M tokens | $30 / 1M tokens |
| GPT-5.5 Pro | $30 / 1M tokens | $180 / 1M tokens |
| GPT-5.4 (previous) | $2.50 / 1M tokens | $15 / 1M tokens |
The naive read is "2× more expensive than GPT-5.4." The honest read is more nuanced. GPT-5.5 is meaningfully more token-efficient — on Codex tasks it reportedly uses ~40% fewer output tokens to produce equivalent work, which means the effective per-task cost rise is closer to 20% than 100%. For agentic workflows, the math actually favors GPT-5.5 once the lower retry rate and shorter responses are factored in.
That said, GPT-5.5 Pro at $30 / $180 is positioned for one specific use case: the long-horizon, high-stakes task where a 5–10 point benchmark gain is worth a 6× cost premium. That's a small slice of real-world traffic.
What's Genuinely New: Computer Use, Tool Chains, Self-Checking
The architectural detail that matters most is not visible in any benchmark table: GPT-5.5 was trained end-to-end as an agent, with native expectations around multi-step tool use, screen reading, and verification.
Three behaviors worth knowing about:
Multi-step tool calls without supervision. OpenAI ran demonstrations of GPT-5.5 completing 1,000+ sequential tool calls without intervention. This is where Terminal-Bench 2.0 and OSWorld-Verified actually come from — the model can drive a terminal or operate software for long stretches. The τ²-bench Telecom evaluation, which measures multi-turn tool-use accuracy in a customer-service simulation, is illustrative — GPT-5.5 reaches 98% accuracy, well above prior generations:
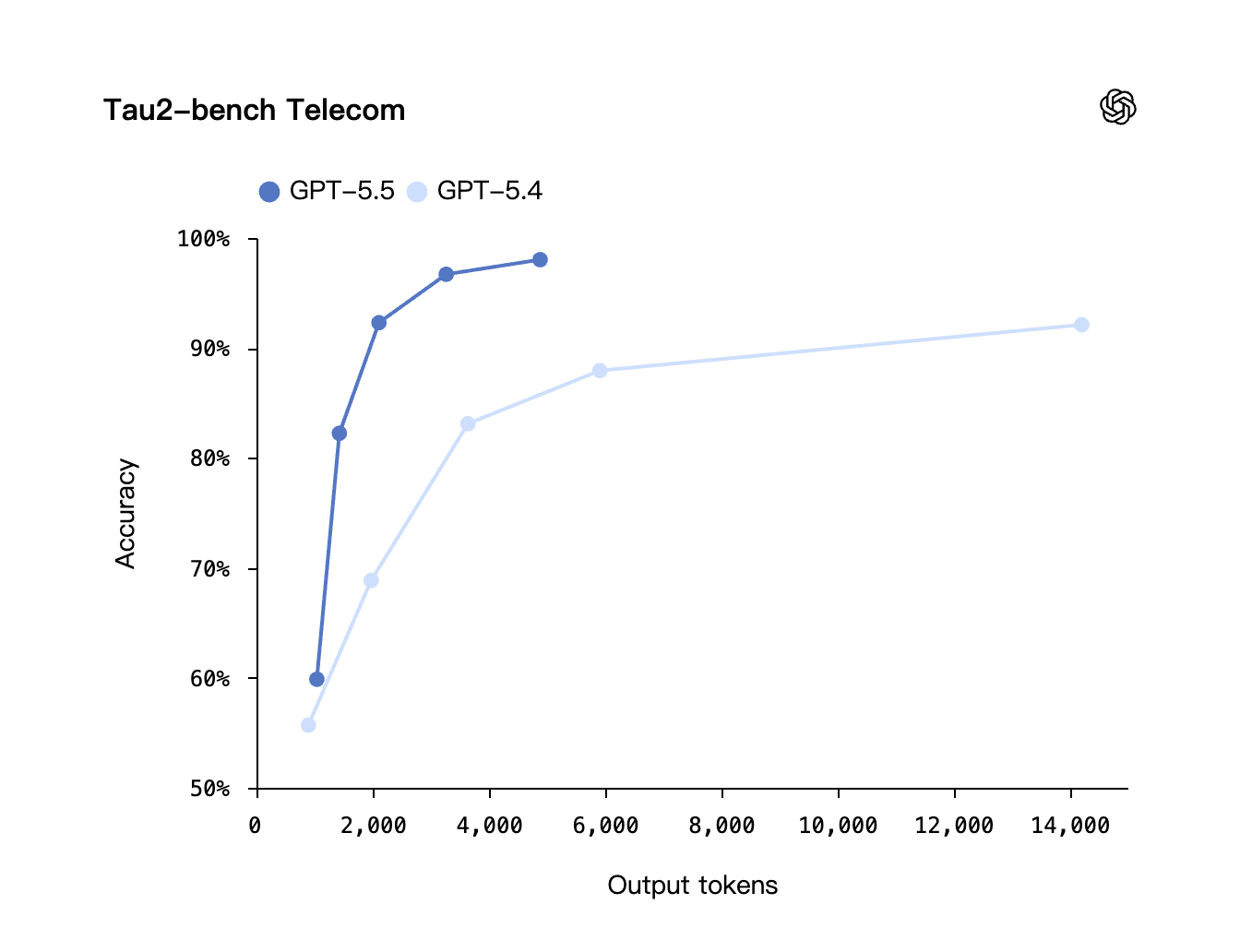
Self-checking before submission. The model now routinely verifies its own output before returning it. Independent reviewers like CodeRabbit report that GPT-5.5 produces "shorter responses, more selective review behavior, and a stronger bias toward small workable changes." Expected issue detection in code review jumped from 58.3% to 79.2% in their benchmark.
Computer-use in Codex. Codex now exposes screen-reading capabilities through GPT-5.5, letting the model see and interact with arbitrary desktop applications. This is the same primitive Anthropic shipped in late 2025 with Claude Computer Use, now with a stronger model behind it.
For a head-to-head on the agentic coding side specifically, see our Claude Opus 4.7 guide — the trade-off between Opus's coding precision and GPT-5.5's tool-use breadth is the most interesting decision in the space right now.
Scientific Research: BixBench and GeneBench
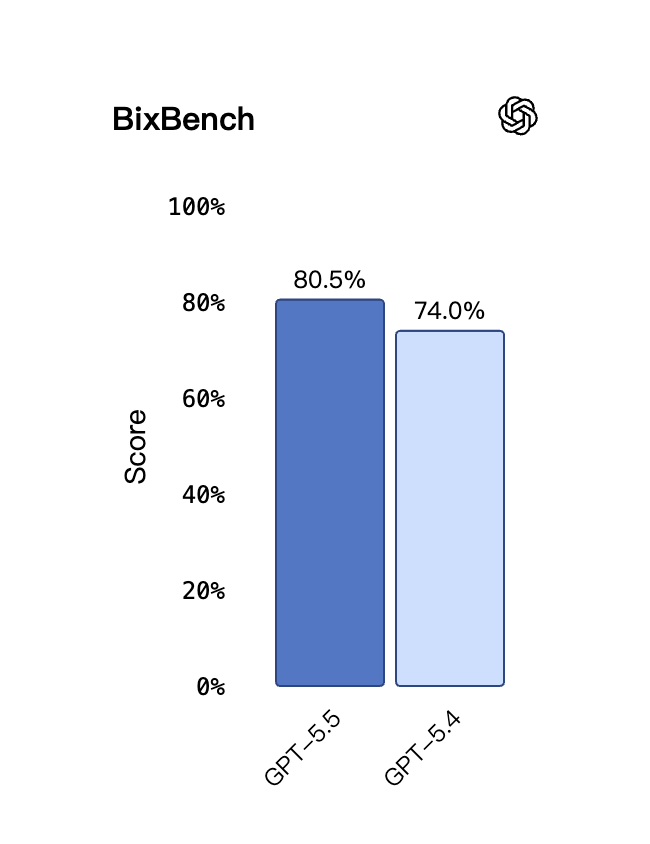
The fourth of OpenAI's training concentration domains — early scientific research — produced two benchmark results worth highlighting separately. BixBench evaluates open-ended bioinformatics tasks where the model must answer questions that require running analyses against real biological data:
GeneBench is the harder companion benchmark, scoring how well the model can synthesize gene-expression analysis from raw inputs across varying token budgets:
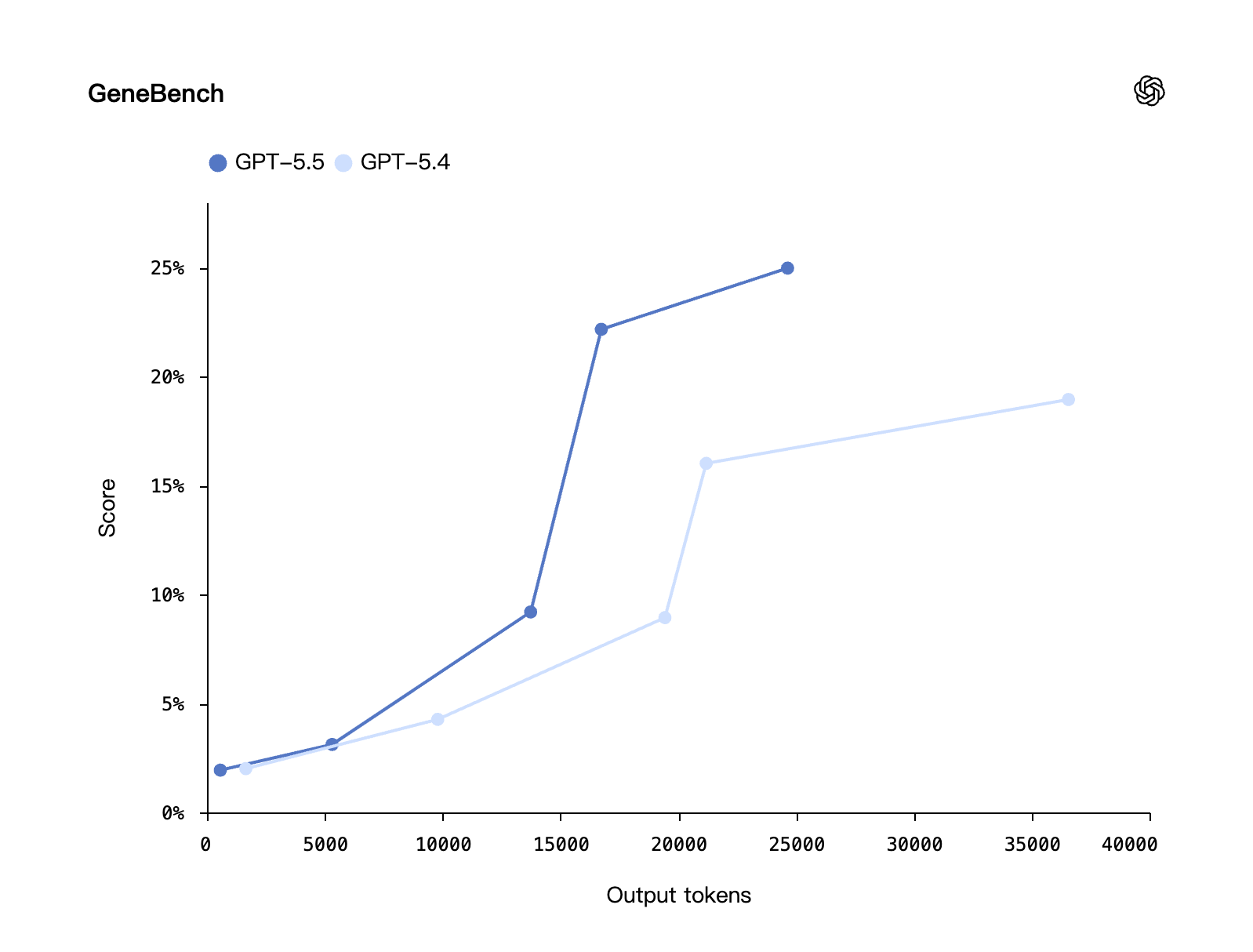
These results matter for a specific class of users — research scientists, biotech analysts, and consultants whose work involves reasoning over scientific literature plus structured data — but they also signal a broader pattern: GPT-5.5's gains are concentrated on tasks where the model needs to act on knowledge (run an analysis, verify a citation, synthesize across documents) rather than recall it cleanly. That is the through-line of the entire release.
The Hallucination Problem No One Wants to Discuss
The sharpest critique in the launch coverage came from the AA-Omniscience benchmark. GPT-5.5 posts the highest accuracy of any model tested at 57% — but with an 86% hallucination rate on the questions it gets wrong. By comparison, Claude Opus 4.7 hallucinates at 36%, and Gemini 3.1 Pro Preview at 50%.
What this means in practice: when GPT-5.5 is wrong, it is confidently wrong. It does not flag uncertainty. For agentic workflows where the model is taking real actions on real systems, this is a non-trivial failure mode.
The mitigation is twofold:
- Use the
xhighreasoning level for any task where output quality matters more than latency. Higher reasoning effort visibly reduces hallucination on the tasks tested. - Pair the model with verification tools — file reads, test runs, search grounding. GPT-5.5's strength is in tool use, so use the tools to ground it.
This is also the gap where Claude Opus 4.7 still wins for production use. If your task is high-stakes and the cost of a confidently wrong answer is large, the lower hallucination rate matters more than 5 points on a benchmark.
Where GPT-5.5 Is Most Useful
Based on the benchmark profile and early hands-on reports, GPT-5.5 is the strongest available model for:
- Long-horizon agentic coding — anything that would have required Claude Code's session-resume tricks now fits inside GPT-5.5's plan-execute-verify loop natively.
- Computer-use tasks in Codex — desktop application automation, GUI testing, end-to-end QA flows.
- Research workflows requiring browsing + synthesis — BrowseComp Pro at 90.1% is a meaningful lead.
- Mathematical reasoning — FrontierMath Tier 1–3 jumps to 52.4% (Tier 4 to 39.6% on Pro), making this the strongest math model OpenAI has shipped.
- Multi-occupation knowledge work — the 84.9% GDPval is a credible signal that GPT-5.5 can produce expert-grade output across diverse white-collar tasks.
It is not the right choice for:
- Tasks where hallucination cost is high and you cannot wrap the call in verification
- Pure coding workloads where Claude Opus 4.7 still has the edge on SWE-bench Pro
- Anything price-sensitive at high volume — DeepSeek V4 and MiMo-V2.5-Pro both undercut GPT-5.5 by 5×–10× per token
What GPT-5.5 Means for AI Slide Generation
The GPT-5.5 release closes an important gap for document-to-slide pipelines: long-context multi-document reasoning is now strong enough that a presentation tool can reliably ingest a 200-page research bundle and produce a coherent slide outline without losing the narrative thread.
This is a different problem from "make a pretty slide." Slide generation from source documents has three failure modes that benchmarks rarely capture: (1) the model loses the through-line across sections, (2) the model invents numbers or citations the source did not contain, (3) the model produces slides whose visual hierarchy does not match the rhetorical hierarchy of the source. GPT-5.5's combination of 1M context, higher GDPval scores, and stronger self-checking directly addresses problem (1) and partially addresses problem (3). Problem (2) — hallucination — is exactly where the 86% confidence-when-wrong rate hurts, and where verification at the document boundary still matters.
At Tosea.ai, the document-to-PPT pipeline runs source-grounded outline generation followed by per-slide rendering, with every claim traceable back to its source paragraph. That architecture matters more for GPT-5.5 than for prior models — the higher capability ceiling means richer, more confident output, but the same architecture also surfaces hallucinations as auditable diffs against the source. For more on this, see our guides on zero-hallucination AI slide generation and converting PDF documents into PowerPoint slides.
The practical takeaway: GPT-5.5 raises the ceiling on what an AI presentation tool can produce from a source document, but the floor — grounded, traceable, factually honest slides — is set by the surrounding document-to-PPT orchestration, not by the model alone. For teams building research-paper-to-slides workflows, the research-paper-to-slides workflow guide walks through the full pipeline.
How to Get Access
- ChatGPT Plus / Pro / Business / Enterprise: Available now. Pro subscribers get GPT-5.5 Pro access included.
- API: Rolling out via the standard
chat/completionsendpoint withmodel: gpt-5.5andmodel: gpt-5.5-pro. Reasoning effort is set via thereasoning_effortparameter. - Codex: Default model is now GPT-5.5 with computer-use enabled.
- Free / lower-tier ChatGPT users: GPT-5.4 remains the default. GPT-5.5 access requires a paid tier.
FAQ
Is GPT-5.5 worth the 2× price increase over GPT-5.4? For agentic and knowledge-work tasks, yes — the per-task cost is roughly 20% higher because of token efficiency gains, and the quality jump is real. For simple chat or low-stakes generation, GPT-5.4 is still the better value.
How does GPT-5.5 compare to Claude Opus 4.7 for coding? Claude Opus 4.7 still leads on SWE-bench Pro by ~6 points, with significantly lower hallucination. GPT-5.5 leads on Terminal-Bench, agentic tool use, and long-horizon tasks. For pure code review and refactoring, Opus is the safer pick. For agentic coding loops with tools, GPT-5.5 wins.
Can GPT-5.5 handle 1M tokens reliably? Yes for retrieval — the context window is genuinely usable across the full 1M. For complex reasoning over the full window, expect quality degradation past 200K, similar to other 1M-context models. Use Engram-style chunking or RAG for high-stakes long-context work.
Why does GPT-5.5 hallucinate more than Opus 4.7?
The likeliest explanation is that OpenAI optimized for agentic confidence — the model was trained to take action rather than defer. That tradeoff is rational for tool-use-heavy workflows but costly for pure Q&A. The mitigation is xhigh reasoning plus tool-grounded verification.
Does GPT-5.5 support image generation? GPT-5.5 itself is text + vision input only. For image generation in OpenAI's stack, see our GPT Image 2 guide — the two models are designed to be used together.
Closing Thought
GPT-5.5 is an interesting release because the headline metric (Intelligence Index leadership) is the least important thing about it. The real story is that OpenAI has shipped a model trained from the ground up as an agent, and the benchmarks where it dominates are the ones that map to multi-step, tool-using, real-world task completion. That is a different center of gravity from Claude Opus 4.7, which remains the precision instrument for high-stakes single-step work.
For the average ChatGPT user the upgrade is welcome but not transformative. For developers building agentic systems, GPT-5.5 is the most capable foundation model available right now — provided you wrap it with the verification scaffolding that its hallucination profile demands.
Sources
- Introducing GPT-5.5 — OpenAI, April 23, 2026
- OpenAI Releases GPT-5.5, a Fully Retrained Agentic Model That Scores 82.7% on Terminal-Bench 2.0 and 84.9% on GDPval — MarkTechPost
- OpenAI Releases GPT-5.5, Faster, Smarter — And Pricier — Decrypt
- OpenAI's GPT-5.5 is here, and it's no potato: narrowly beats Anthropic's Claude Mythos Preview on Terminal-Bench 2.0 — VentureBeat
- OpenAI Releases GPT 5.5, Tops Most AI Benchmarks — OfficeChai
- GPT-5.5 Benchmarks 2026: Scores, Rankings & Performance — BenchLM.ai
- OpenAI GPT-5.5 Benchmark Results — CodeRabbit


