How to Use Claude Opus 4.7: Complete Guide to Anthropic's New Agentic Coding Model
A practical review of Claude Opus 4.7 — Anthropic's April 2026 release with 87.6% SWE-bench Verified, 64.3% SWE-bench Pro, improved vision, and the new xhigh effort level.

On April 16, 2026, Anthropic released Claude Opus 4.7 as the new default model for Claude Code, the Claude API, Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry. Pricing held steady at $5 per million input tokens and $25 per million output tokens — the same rate as Opus 4.6 — while benchmark numbers moved noticeably. SWE-bench Verified climbed from 80.8% to 87.6%, SWE-bench Pro jumped from 53.4% to 64.3%, and Terminal-Bench 2.0 rose from 65.4% to 69.4%.

The release is framed by Anthropic as an "interim step" on the way toward a larger model family (internally referenced as Mythos Preview), but the gains are concrete enough that teams running Opus 4.6 in production should take a careful look. This guide breaks down what actually changed, how the new capabilities translate into day-to-day work, and what it means if your workflow depends on Claude for coding, research, or document-heavy tasks. If you already use Claude Code, you can pair it with Tosea.ai to turn the technical output — release notes, architecture docs, benchmark reports — into decks you can hand to non-engineering stakeholders in a few minutes.
What Is Claude Opus 4.7?
Claude Opus 4.7 is Anthropic's latest frontier model in the Claude 4 family, positioned as a direct replacement for Opus 4.6 across every surface where Anthropic ships models. Developers access it via the model identifier claude-opus-4-7 in the Claude API. It is already the default in Claude Code, which has accumulated a large installed base among engineering teams — our Claude Code complete guide covers the surrounding tooling in depth.
Three things distinguish Opus 4.7 from its predecessor:
- Stronger agentic behavior on long, hard tasks. Anthropic claims users can now hand off coding work that previously required close supervision, with the model verifying its own outputs before reporting back.
- Higher-resolution vision. The model accepts images up to 2,576 pixels on the long edge, roughly 3.75 megapixels — more than three times Opus 4.6's capacity.
- A new
xhigheffort level. This sits betweenhighandmax, giving developers finer control over the reasoning-versus-latency tradeoff.
The model ships alongside several platform updates: public-beta task budgets, improved file-system memory, a new /ultrareview slash command in Claude Code, and extended Auto mode for Max-tier users. For broader context on Anthropic's expanding product surface, see our analysis of Claude plugins and professional document transformation.
How Opus 4.7 Performs on Coding Benchmarks
Benchmark results are the headline story. Opus 4.7 sets new numbers across every coding and agentic evaluation Anthropic reports.
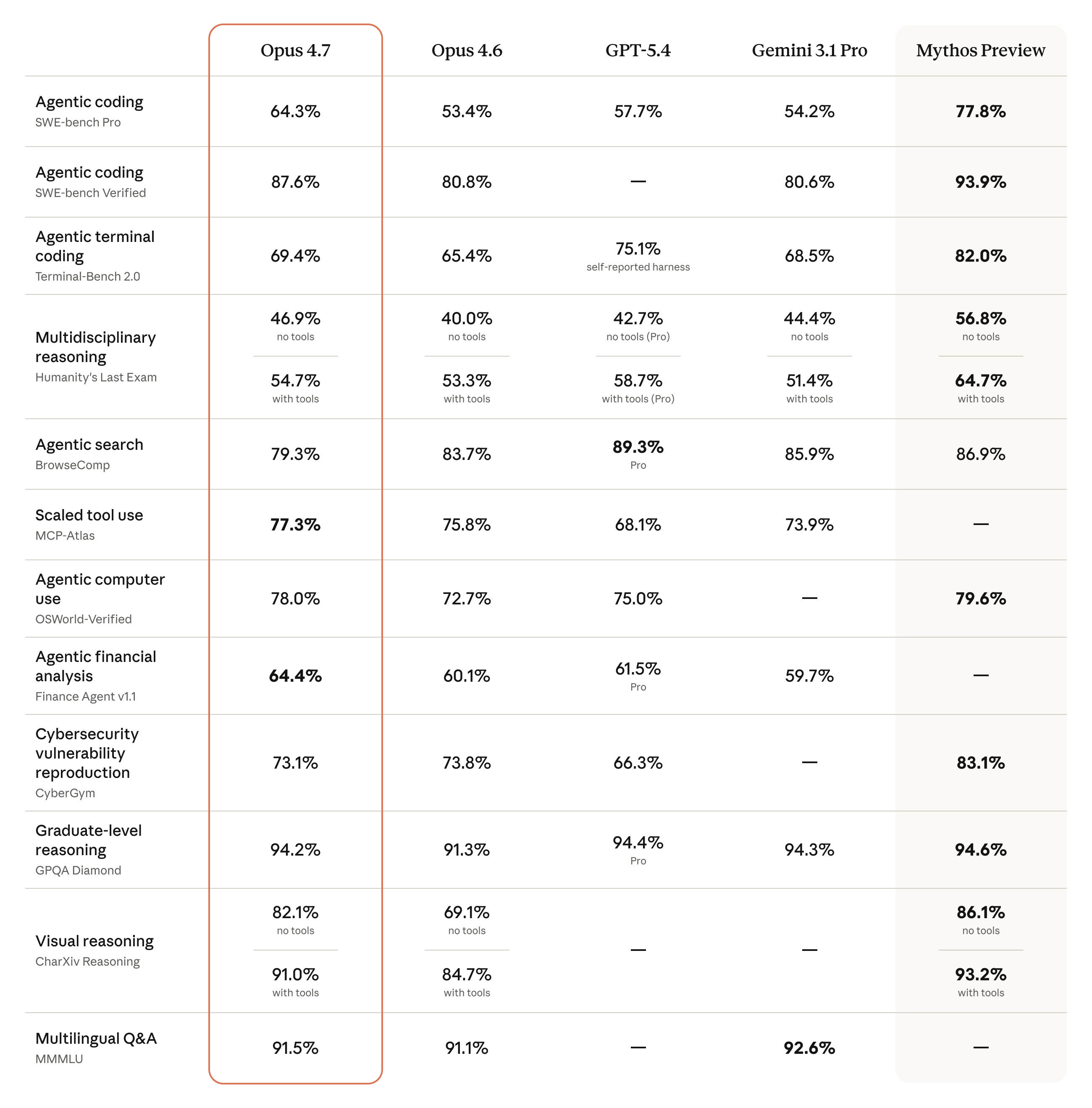
The numbers that matter for engineering teams
| Benchmark | Opus 4.7 | Opus 4.6 | Delta |
|---|---|---|---|
| SWE-bench Pro (agentic coding) | 64.3% | 53.4% | +10.9 pts |
| SWE-bench Verified | 87.6% | 80.8% | +6.8 pts |
| Terminal-Bench 2.0 | 69.4% | 65.4% | +4.0 pts |
| MCP-Atlas (scaled tool use) | 77.3% | 75.8% | +1.5 pts |
| OSWorld-Verified (computer use) | 78.0% | 72.7% | +5.3 pts |
| Finance Agent v1.1 | 64.4% | 60.1% | +4.3 pts |
| GPQA Diamond (graduate reasoning) | 94.2% | — | — |
SWE-bench Verified and SWE-bench Pro measure real GitHub issues against test suites. A ~7-point move on Verified and a ~11-point move on Pro is large by recent standards — previous model-family jumps have typically delivered 2-5 points on these evaluations.
What partners report from production workloads
Benchmarks often overstate real-world gains, so the partner statements in Anthropic's release note are worth reading closely. Several are specific enough to triangulate against:
- Cursor: On CursorBench, Opus 4.7 clears 70% versus Opus 4.6 at 58%.
- Rakuten: Opus 4.7 resolves 3× more production tasks than Opus 4.6 on Rakuten-SWE-Bench.
- Warp: Passed Terminal Bench tasks prior Claude models had failed and worked through a tricky concurrency bug.
- CodeRabbit: Over 10% recall improvement on code review workloads, with stable precision.
- Notion: +14% over Opus 4.6 on complex multi-step workflows, at fewer tokens.
- Vercel: Stronger on one-shot coding tasks, more complete outputs.
- Devin: Long-horizon autonomy working coherently for hours without giving up.
- Stripe: Catches its own logical faults during planning.
- Replit: Same quality as Opus 4.6 at lower cost and higher efficiency.
The CodeRabbit and Cursor numbers align most closely with the benchmark data — a 10-12% lift on tasks where the previous generation was already competent. The Rakuten claim (3× production task resolution) is a larger multiplier than any public benchmark would predict, and likely reflects a baseline where Opus 4.6 often failed outright on their specific task distribution.
Knowledge Work and GDPval-AA
Coding isn't the only area with movement. On GDPval-AA — a third-party evaluation of economically valuable knowledge work across finance, legal, and other domains — Opus 4.7 achieves the top Elo score.
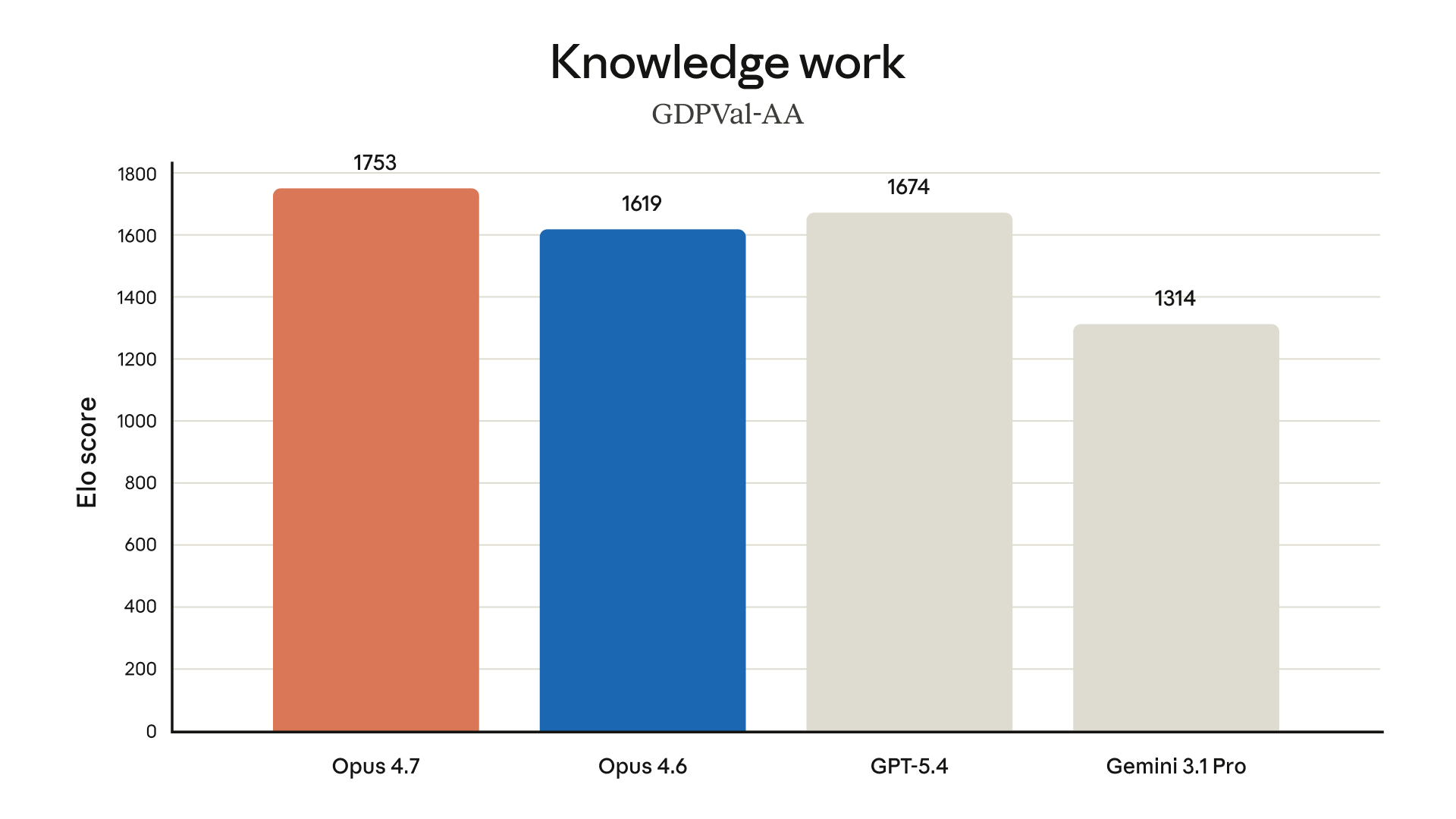
The leaderboard positions:
- Opus 4.7: 1753
- GPT-5.4: 1674
- Opus 4.6: 1619
- Gemini 3.1 Pro: 1314
Harvey, the legal-AI platform, reports that Opus 4.7 scores 90.9% on BigLaw Bench at high effort — a notable result for a generalist model benchmarked against domain-specific tasks. For consulting and strategy audiences, this is the area where Opus 4.7 starts to become usable for first-draft memos, analyst research, and executive-level synthesis. Those outputs then need presentation. Our guide to McKinsey-style deck logic covers the structural principles that still matter once AI is writing the raw content.
Improved Vision and Document Reasoning
The higher-resolution vision input changes what you can realistically ask Opus 4.7 to look at. Previous Claude models compressed large screenshots to the point where small text, dense tables, or pixel-precise reference tasks degraded badly. At 2,576 pixels on the long edge, most retina-resolution screenshots pass through without meaningful downscaling.
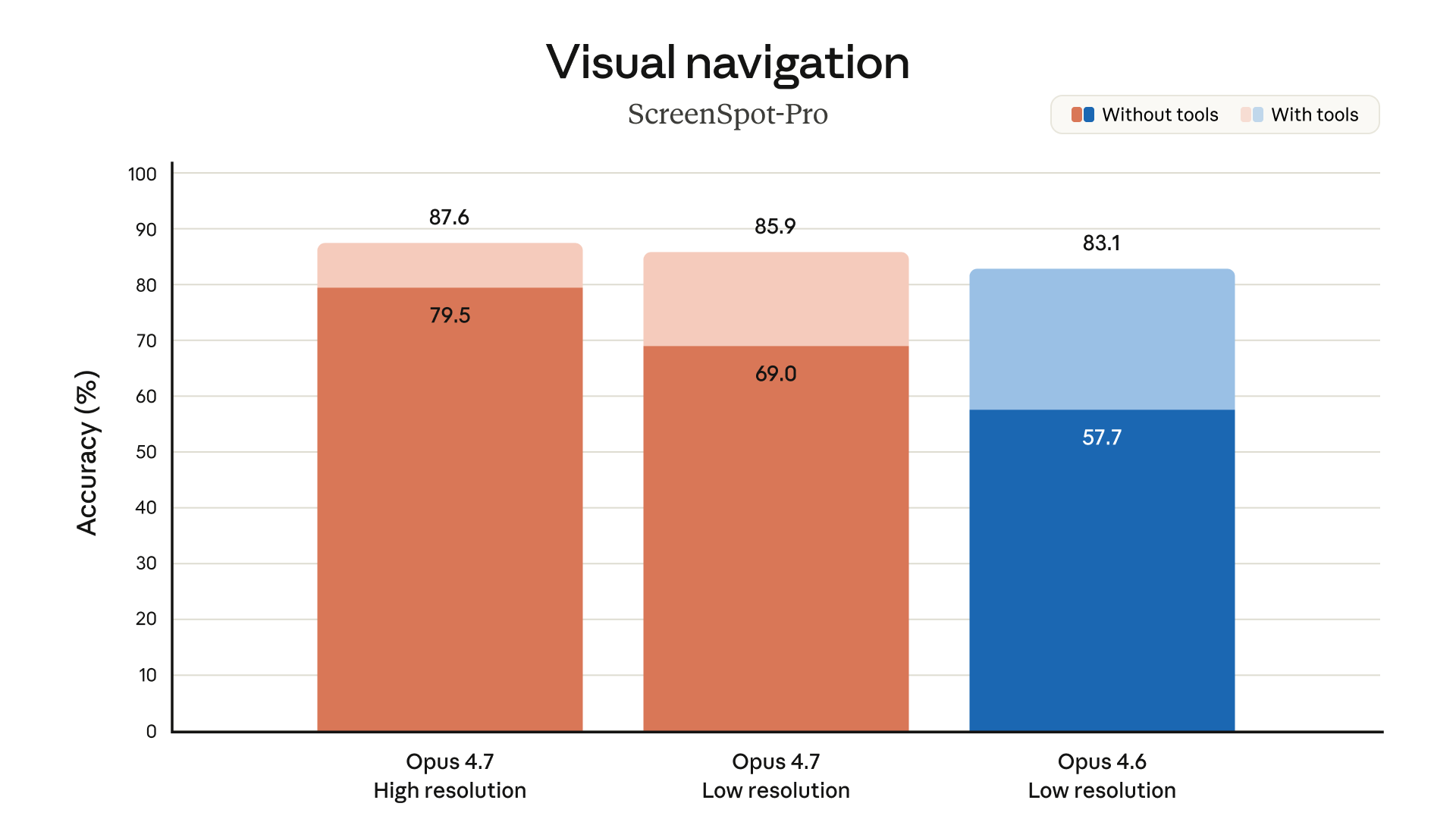
On ScreenSpot-Pro visual navigation, Opus 4.7 reaches 87.6% at high resolution and 85.9% at low resolution, versus Opus 4.6's 83.1%. XBOW reports 98.5% on their internal visual-acuity benchmark — a step change from previous Claude models for computer-use work.
Document reasoning sees one of the largest jumps in the release:
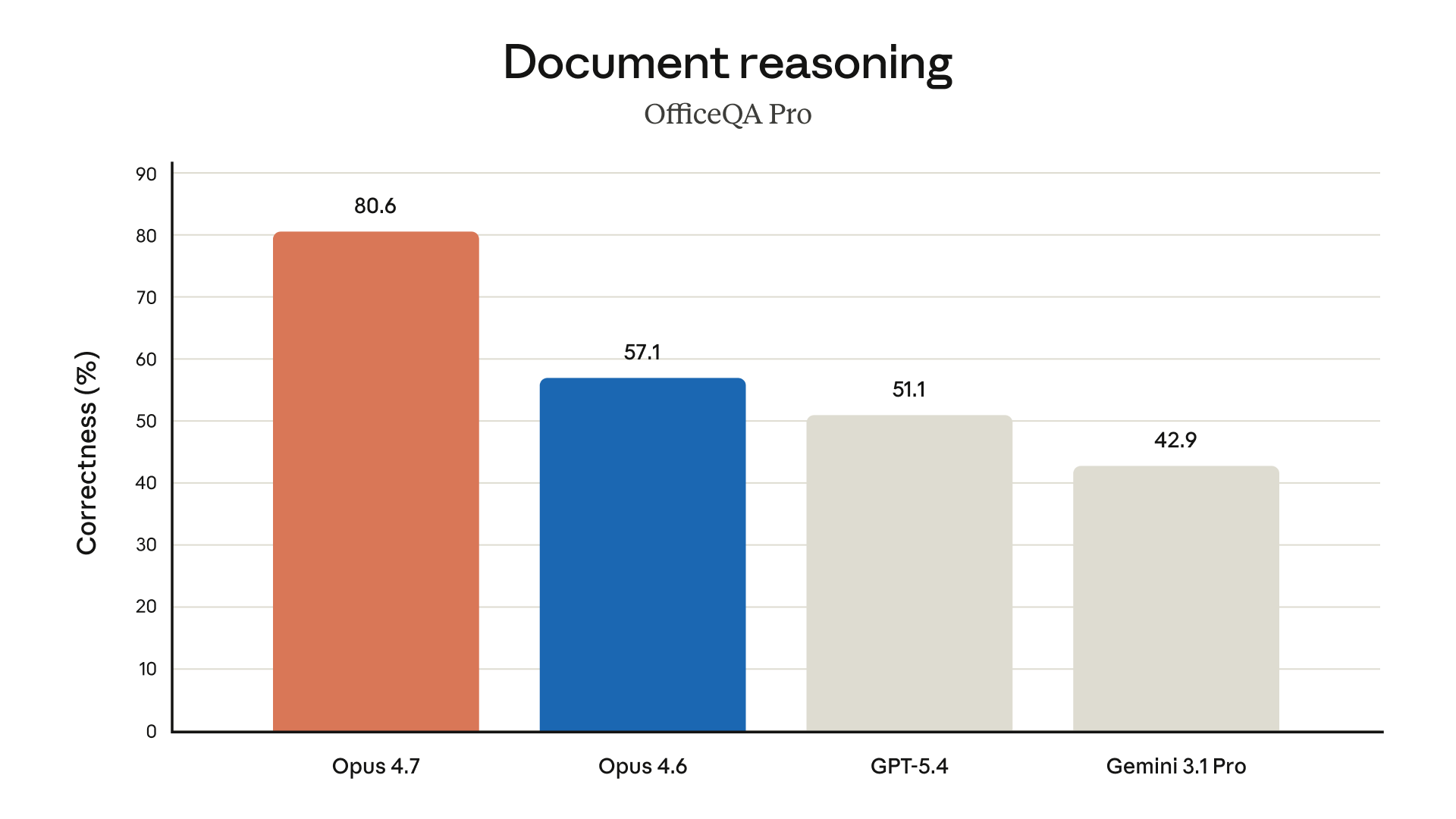
OfficeQA Pro tests comprehension across real office documents — spreadsheets, slide decks, contracts. Opus 4.7 scores 80.6% correctness, versus:
- Opus 4.6: 57.1%
- GPT-5.4: 51.1%
- Gemini 3.1 Pro: 42.9%
That is a 23-point gap over Opus 4.6 on the same evaluation. Databricks confirms the gain in production, reporting 21% fewer errors than Opus 4.6 on document reasoning tasks. This is a practical difference if your workflow involves asking Claude to pull structured information out of PDFs, quarterly reports, or scanned documents. For academic PDFs specifically, we compared several pipelines in our review of AI tools for researcher slides.
Long-Context and Long-Horizon Coherence
Opus 4.7 now better utilizes the 1M-token context window that has been available since Opus 4.5. Two evaluations tell this story.
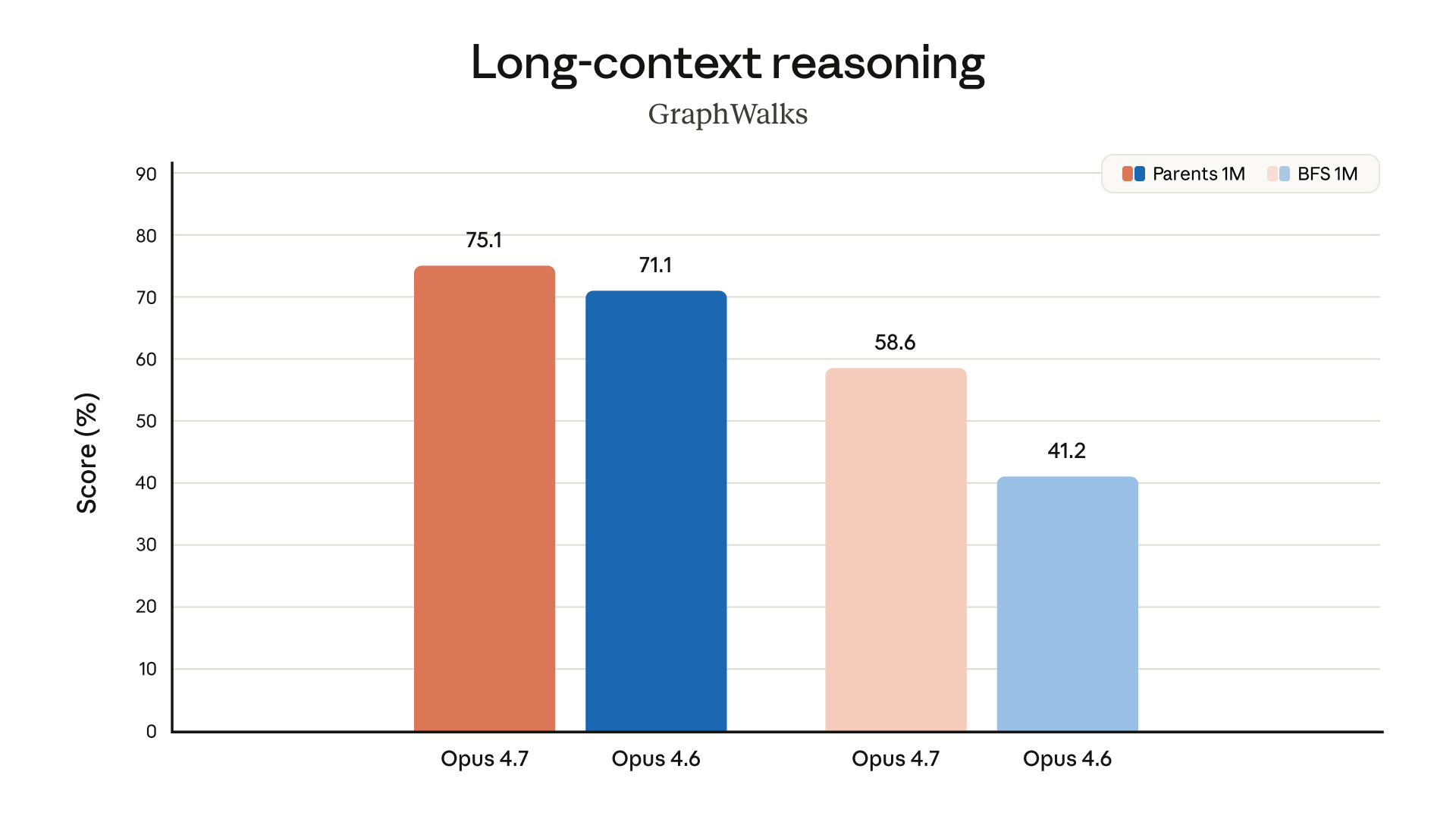
On GraphWalks at 1M tokens, Opus 4.7 scores 75.1% on the Parents task (up from 71.1%) and 58.6% on BFS (up from 41.2%). The BFS number is the interesting one: a 17-point jump on a task specifically designed to test whether the model actually reasons over the full context window rather than attending to surface patterns.
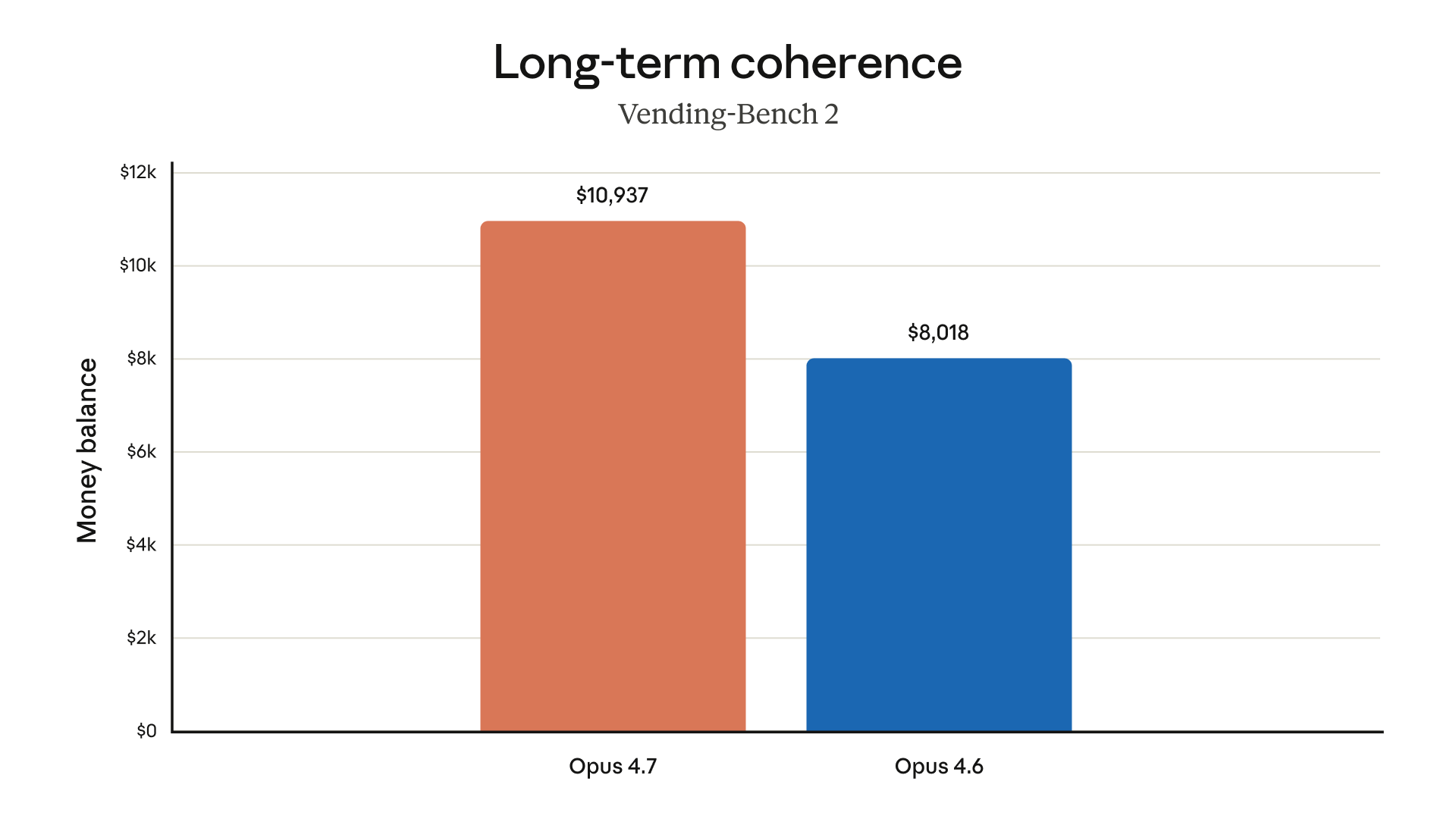
Vending-Bench 2 measures whether a model can maintain coherent decision-making across extended autonomous operation. Opus 4.7 achieves a money balance of $10,937, versus Opus 4.6's $8,018. Hex describes it as the strongest model they have evaluated, with better handling of missing data.
What this enables in practice: multi-hour agentic sessions where the model needs to hold multiple intermediate results in memory and make decisions consistent with earlier ones. Devin's statement about "working coherently for hours without giving up" is the product-facing version of the same underlying capability.
The New xhigh Effort Level
Claude's effort parameter controls how much the model reasons before producing output. Before Opus 4.7, the levels were low, medium, high, and max. The new xhigh level sits between high and max, and Claude Code defaults to it across all plans.
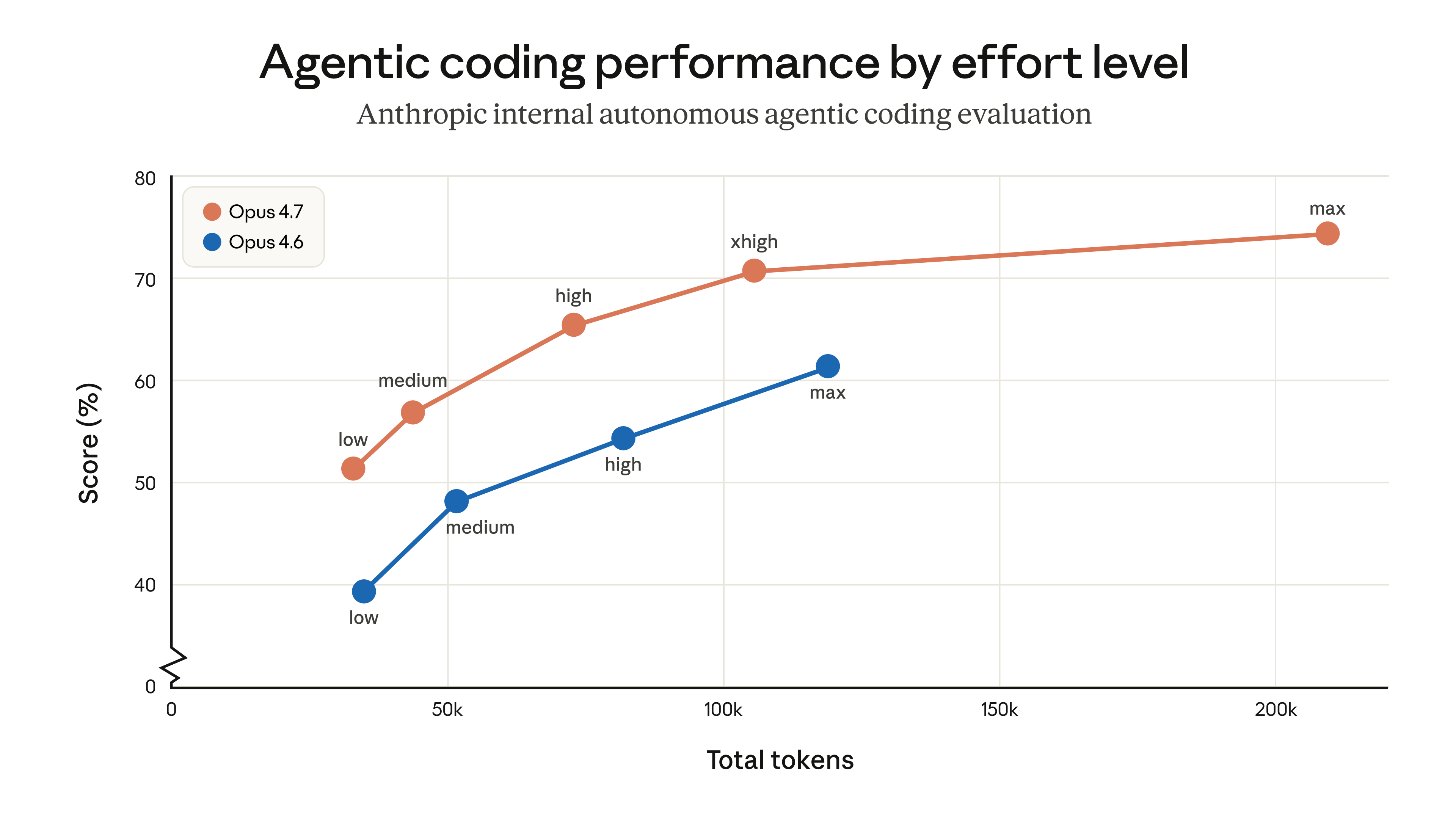
Anthropic's internal coding evaluations show token usage improving at every effort level — meaning Opus 4.7 does more with the same budget. The xhigh tier is specifically useful for agentic workloads that need deeper reasoning than high provides but don't need the full latency cost of max.
Two practical implications:
- Migrate defaults deliberately. If your harness pins a specific effort level, test
xhighagainst your current setting before committing. Some workloads that were previously atmaxcan drop toxhighwith no quality loss. - Budget accordingly. The model thinks more on later turns in agentic settings. Output tokens can grow on long-running tasks. Task budgets, covered below, are Anthropic's proposed mitigation.
Instruction Following: A Breaking Change to Watch
Anthropic explicitly flags this: Opus 4.7 follows instructions more literally than Opus 4.6. Prompts written loosely for earlier models can produce unexpected results. Where Opus 4.6 would interpret "summarize this briefly" as "give me three bullet points," Opus 4.7 may now give a one-sentence summary if "briefly" is read strictly.
If you migrate a production prompt library from 4.6 to 4.7, plan for a re-tuning pass. Add specifics where you previously relied on the model to guess the intended output format. This is especially important for prompts that control agentic loops, where a single misread instruction can compound across turns.
Task Budgets, Memory, and Claude Code Updates
Four platform-level changes ship with Opus 4.7:
- Task budgets (public beta on the Claude Platform) give developers a way to guide token spend so Claude can prioritize work across longer runs.
- File-system memory improvements mean Opus 4.7 is better at remembering notes across multi-session work, reducing required upfront context.
/ultrareviewis a new Claude Code slash command that produces a dedicated review session — reading through changes and flagging bugs and design issues. Pro and Max users get three free reviews.- Auto mode — letting Claude make decisions autonomously — extends to Max tier users.
Task budgets and memory are the two most interesting for teams managing ongoing work. Combined, they let a Claude Code session run longer without the operator having to curate context by hand. If you are building internal tooling on top of Claude, these are the primitives to design around.
Safety, Alignment, and the Cyber Verification Program
Opus 4.7 shows a similar overall safety profile to Opus 4.6, with improvements on honesty and resistance to prompt-injection attacks.
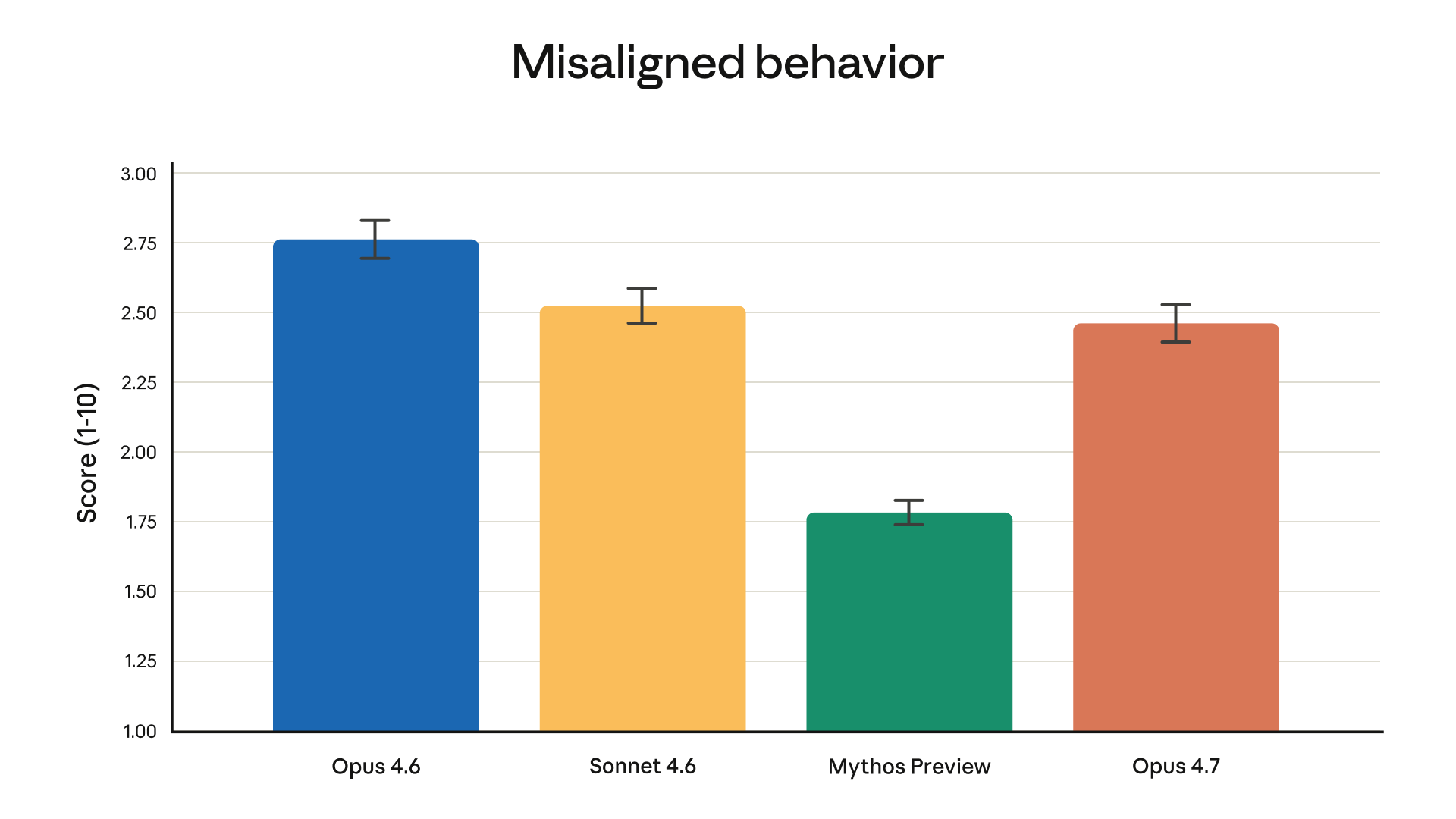
Anthropic is transparent about the tradeoffs: the model shows modestly weaker performance on some harm-reduction advice (for example, questions about controlled substances), and Anthropic describes it as "largely well-aligned and trustworthy, though not fully ideal." Mythos Preview — Anthropic's still-unreleased larger model — is called out as the best-aligned model they have trained.
Following the earlier announcement of Project Glasswing, Opus 4.7 includes automated safeguards that detect and block requests indicating prohibited or high-risk cybersecurity use. Security professionals doing legitimate work — vulnerability research, penetration testing, red-teaming — can register for the new Cyber Verification Program to avoid friction.
Migrating From Opus 4.6: What Developers Should Plan For
Anthropic flags two token-related changes for developers moving from Opus 4.6:
- Updated tokenizer. The new tokenizer improves text processing but maps the same input to roughly 1.0–1.35× more tokens depending on content type. Factor this into your billing estimates.
- More thinking at higher effort levels. The model reasons more on later turns in agentic settings, which improves reliability but increases output tokens.
Anthropic claims net token usage across all effort levels is improved on their internal coding evaluation, meaning the additional output is offset by fewer retries and more correct first attempts. Whether that holds for your workload is empirical — run a benchmark on your actual tasks before migrating production defaults.
A sensible migration checklist:
- Sample 20-50 real tasks from your production trace and replay them on Opus 4.7 at matched effort levels.
- Compare end-to-end cost (input + output tokens, weighted by per-million price) and end-to-end quality (resolved vs unresolved).
- Re-tune prompts that rely on loose instruction following.
- Test
xhighas a replacement for workloads that currently usemax. - Review task-budget settings if you run long agentic sessions.
Who Should Care About Opus 4.7 Right Now
Four audiences have the most immediate reason to pay attention:
Engineering teams running Opus 4.6 in production. The SWE-bench gains are large enough that a migration pilot is probably worth the week of engineering time. Partner statements from Cursor, Notion, and Vercel suggest the improvements are real on production workloads, not just benchmark-specific.
Computer-use and agentic automation builders. The higher-resolution vision (2,576 px) and OSWorld-Verified gain (+5.3 pts) materially change what can be automated reliably. If you paused a browser-agent or computer-control project because Opus 4.6 failed on dense UIs, it's worth rerunning your evaluations.
Document-heavy workflows. The 23-point OfficeQA Pro jump and Databricks's 21% error reduction are the largest single-release gains in document reasoning from any frontier model this year. Teams building over financial filings, contracts, or academic literature should re-evaluate their pipeline.
Teams that produce communication artifacts from technical work. Once Claude handles the engineering or research phase, the output still needs to be communicated. That is the handoff gap Tosea.ai is built to close — converting docs, specs, and long-form reports into presentation-ready decks. For teams evaluating the broader AI-presentation category, our 2026 buyer's guide covers the major options.
How Opus 4.7 Fits Into the Broader Agentic Stack
Model releases don't exist in isolation. Opus 4.7 ships into an ecosystem where coordinated agents are increasingly the default pattern — a shift we explored in our DeerFlow super agent guide. Three architectural points are worth keeping in mind:
- Tool use and orchestration matter more than raw capability. A 10-point SWE-bench gain is meaningful, but the MCP-Atlas improvement (+1.5 pts) and the long-running Vending-Bench gain are arguably more important for real agentic deployments.
- Supervised autonomy remains the practical mode. Plan Mode, task budgets, and
/ultrareviewall reflect a philosophy of giving operators the tools to intervene — not a push toward full autonomy. For why this matters in production, see our analysis of why professional workflows demand more than code that runs. - Model routing becomes a design decision. With Opus 4.7, Opus 4.6, Sonnet, and Haiku in the lineup (plus GPT-5.4 and Gemini 3.1 Pro externally), most serious deployments will route tasks across multiple models. The right question is rarely "which is the best model" but "which model, at which effort level, for which task class."
What's Next
Anthropic describes Opus 4.7 as an interim step toward Mythos Preview, the larger model they have teased internally. The pattern is familiar: the X.Y release ships real improvements and serves as a deployment vehicle for safeguards that will carry into the X+1 release. Expect at least one more point release in the Claude 4 family before Mythos ships generally.
For teams making decisions today: Opus 4.7 is a drop-in upgrade for most Opus 4.6 workloads, with two caveats — re-tune your prompts for literal instruction following, and run a token-cost regression before committing production traffic. The coding and document-reasoning gains are substantial enough that the migration pays for itself on most realistic workloads.
If Claude Opus 4.7 now handles the hard engineering and research work, the next bottleneck is turning those outputs into artifacts your team can share. That is where tools like Tosea.ai come in — take the documentation, benchmark reports, or research notes Claude generates and produce a presentation-ready deck in minutes. The pairing is increasingly how modern teams close the gap between what gets built and what gets communicated.
What Opus 4.7 Means for AI Slide Generation
The improvements that matter most for engineering teams — better long-context reasoning, more reliable tool use, fewer hallucinations on multi-step tasks — translate almost directly into a measurably better experience for anyone using AI to turn long documents into presentation decks. The bottleneck in document-to-slide workflows has rarely been "can the model write a sentence?" It has been "can the model read a 60-page PDF, identify the three most important arguments, and produce a slide structure that preserves the source's reasoning without fabricating numbers?" Opus 4.7's gains on agentic and document-grounded benchmarks suggest the answer is increasingly yes.
For teams running an AI presentation tool against research papers, market analyses, or product specifications, the practical effect shows up in three places: cleaner outline generation across multi-document inputs, fewer hallucinated chart labels and citation numbers (the kind of failure mode we explored in our zero-hallucination AI slides guide), and better preservation of source structure when the input is genuinely complex — a 100-slide deck can now be generated from a single research paper with consistent style and traceable citations, a workflow we documented in how to build a massive slide deck in minutes.
At Tosea.ai, where the document-to-PPT pipeline routes between several frontier models depending on the task, Opus 4.7 has become a default for the structure-extraction step on dense academic and consulting inputs. If you're already using a PDF-to-PowerPoint workflow that struggles on long-form sources, an Opus 4.7 backend is one of the simplest single upgrades to try. For a worked example of the full workflow, see our research-paper-to-slides guide.
Sources
- Introducing Claude Opus 4.7 — Anthropic, April 16, 2026
- What's new in Claude Opus 4.7 — Claude API Docs
- Introducing Anthropic's Claude Opus 4.7 model in Amazon Bedrock — AWS
- Anthropic Releases Claude Opus 4.7, Beats GPT-5.4 and Gemini 3.1 Pro — OfficeChai
- Anthropic launches Claude Opus 4.7 with enhanced coding capabilities — Yahoo Finance
- Claude Opus 4.7 vs GPT-5: 2026 Coding War — iWeaver


