How to Use Kimi K2.6: Complete Guide to Moonshot AI's New 1T-Parameter Open-Source Coding Model
A practical walkthrough of Kimi K2.6 — Moonshot AI's April 2026 open-source MoE release with 1T parameters, 256K context, 300-agent swarms, and benchmark wins over Claude Opus 4.6.

On April 20, 2026, Moonshot AI released Kimi K2.6 — a 1-trillion-parameter open-source Mixture-of-Experts model positioned directly at the agentic-coding segment that Claude Opus 4.7 and GPT-5.4 have dominated through early 2026. The numbers on paper are striking: SWE-Bench Pro at 58.6% (ahead of both Opus 4.6 and GPT-5.4), Humanity's Last Exam with tools at 54.0% (ahead of both), and a 185% throughput lift over K2.5 in a real 13-hour optimization run against the exchange-core benchmark. For a weights-available Chinese model to lead US frontier labs on commercially relevant agentic benchmarks — not just academic ones — is a meaningful shift in the category.

This guide walks through what actually ships in K2.6, how the benchmark gaps hold up when you read them carefully, where the model genuinely leads and where it doesn't, and how it fits into a modern content-and-coding workflow alongside existing tools like Tosea.ai for document-to-presentation work. If you're considering routing production traffic to K2.6, the last two sections are the ones to read closely.
What Is Kimi K2.6?
Kimi K2.6 is Moonshot AI's latest flagship in the K2 open-source family, graduating the earlier K2.6 Code Preview branch to general availability. It ships simultaneously on Kimi.com, the Kimi App, the Kimi API at platform.kimi.ai, and Kimi Code. The model is weights-available — a critical distinction from closed frontier models — which means teams can self-host, fine-tune, and deploy it inside their own infrastructure without vendor lock-in.
The headline specs:
- 1 trillion total parameters in a MoE architecture with 384 experts
- 8 experts activated per token (roughly ~32B active parameters at inference time)
- 400M-parameter vision encoder for multimodal input
- 262,144 tokens (256K) context window across all variants
- Multi-head Latent Attention (MLA) and SwiGLU activations for hardware efficiency
- 300-sub-agent swarms across 4,000 coordinated steps — triple K2.5's 100/1,500 ceiling
- Native video input, up from K2.5's image-only multimodal
The combination of MoE efficiency and MLA attention is what makes the economics work. Serving an 8-of-384 expert mix at inference is closer to running a 32B dense model than a full 1T one, which is how Moonshot can price K2.6 well below comparably capable closed models while still offering weights under a permissive license.
Benchmark Results: Where Kimi K2.6 Actually Leads
The benchmark story is more nuanced than the headlines. K2.6 wins on a specific class of evaluations — agentic tool use, coding, and long-horizon tasks — and trails on pure reasoning. That pattern matters because it tells you when to route traffic to K2.6 versus when to stay on a closed frontier model.
Coding benchmarks

On Moonshot's internal Kimi Code Bench, K2.6 jumps from K2.5's 57.4% to 68.2% — an almost 11-point lift. External coding numbers:
| Benchmark | K2.6 | Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-Bench Verified | 80.2% | 80.8% | ~79% | 80.6% |
| SWE-Bench Pro | 58.6% | 53.4% | 57.7% | — |
| SWE-Bench Multilingual | 76.7% | — | — | 76.9% |
| Terminal-Bench 2.0 | 66.7% | 65.4% | — | — |
| LiveCodeBench v6 | 89.6% | — | — | — |
The SWE-Bench Pro win is the one to note: +5.2 points over Opus 4.6 and +0.9 over GPT-5.4. That's the benchmark most aligned with real agentic production work (not just "can the model patch a small bug"), and K2.6 is the first open-weights model to lead it. For additional coding context, our Claude Code complete guide covers how this family of evaluations maps to day-to-day engineering workflows.
Reasoning and knowledge benchmarks
On Humanity's Last Exam with tools, K2.6 reaches 54.0% — ahead of Claude (53.0%) and GPT-5.4 (52.1%). On Toolathlon it hits 50.0, ahead of Claude (47.2) and Gemini 3.1 Pro (48.8). On AIME 2026, K2.6 reaches 96.4%; on GPQA Diamond, it's in the same band as GPT-5.4.
Where K2.6 trails: pure reasoning without tools. Anthropic's Opus 4.7 and OpenAI's GPT-5.4 retain clear leads on BrowseComp standalone, AIME without tools, and the harder Humanity's Last Exam subsets. The pattern matches what you'd expect: K2.6 is trained and instruction-tuned heavily for agentic tool use; the closed US labs still have the edge on "think quietly and produce the answer."
Agent swarm and long-horizon work

The Kimi Claw Bench measures multi-agent collaboration in Moonshot's "Claw Groups" heterogeneous-agent framework. The 5.9-point lift over K2.5 is smaller than the coding gap, but it's on a benchmark where K2.6 is explicitly competing with itself — the 300-agent ceiling is new in this release, and the scoring reflects how well those agents coordinate. For a broader view of the multi-agent landscape, our DeerFlow super agent guide covers the open-source agent-frameworks side of this category, and our OpenClaw Clawdbot overview looks at the related shift toward agentic workflows.
The Real Test: 13 Hours, 1,000+ Tool Calls
The benchmark numbers are easy to dismiss as curated. The more useful datapoint is Moonshot's own long-horizon case study, which shows the model actually doing the kind of work the benchmarks are supposed to proxy for.
On the open-source exchange-core trading-engine benchmark, a single K2.6 session ran for 13 hours, made more than 1,000 tool calls, modified over 4,000 lines of code across multiple files, and lifted throughput from 0.43 MT/s to 1.24 MT/s — a 185% gain. The annotated Pareto plot above is from that run: the model systematically explored a set of optimization strategies (CPU-aware tuning, empty-set short-circuit, group-spin variants), tracked both perf and median metrics, and landed near the theoretical ideal point.
Two things are worth pulling out of this:
- Stability over 13 hours is non-trivial. Most coding agents degrade after 2–3 hours of autonomous work — context-window drift, instruction forgetting, thrashing between approaches. K2.6 holds coherence long enough to run a real optimization loop.
- Tool-call reliability matters more than raw capability. 1,000+ tool calls means 1,000+ chances to fail. CodeBuddy's independent number — 96.60% tool invocation success rate — lines up with this pattern.
A second long-horizon case shows the same pattern on the inference-optimization side: K2.6 rewrote a Qwen3.5-0.8B inference path from ~15 tokens/sec to 193 tokens/sec, beating LM Studio by ~20% on the same hardware.
Partner Reactions: What Teams Using K2.6 Actually Report
Moonshot's launch post lists quotes from 10+ partners. The useful signal is the specificity — vague endorsements are cheap; numbered claims trace back to production runs. The tightest ones:
- Vercel: >50% improvement on the Next.js benchmark versus K2.5. "Compelling option for agentic coding at strong cost-performance."
- CodeBuddy: +12% accuracy, +18% long-context stability, 96.60% tool invocation success on internal evals.
- Factory.ai: +15% lift over K2.5 with better instruction following, thorough exploration, fewer errors.
- Kilo.ai: "SOTA-level performance at a fraction of the cost."
- Ollama: "Raises the bar for open-source models."
- Fireworks.ai: "Significant advancement for high-stakes agentic workflows with superior long-horizon reliability."
- Baseten: "Excels on coding tasks comparable to leading closed-source models."
The Vercel number is the one that matters most for frontend-heavy shops: a >50% lift on Next.js work is the kind of delta that changes which model you route to by default.
Where Kimi K2.6 Fits in the Stack
The release pattern follows what's becoming a recognizable template: model first, then vertical tooling. K2.6 ships alongside five named surfaces worth understanding if you plan to integrate:
- Kimi Code — Moonshot's version of an agentic coding CLI, comparable to Claude Code.
- Claw Groups — heterogeneous-agent framework supporting up to 300 coordinated sub-agents.
- Document-to-Skills — converts PDFs, spreadsheets, and design docs into first-class agent capabilities.
- Agent Swarm primitives — the 4,000-step coordinated-execution substrate.
- Coding-driven Design — Kimi Design Bench, which we'll cover below.
For content teams, #3 is the most immediately relevant. "Document-to-Skills" turns a long-form artifact — a spec, a research paper, a policy doc — into a reusable agent primitive. That's the same workflow step Tosea.ai solves on the presentation side: take a document, produce something your team can act on. The two approaches are complementary — Kimi's version outputs agent skills for automation loops; Tosea's version outputs presentation decks for human audiences.
Coding-Driven Design: Why Moonshot Built a Design Bench
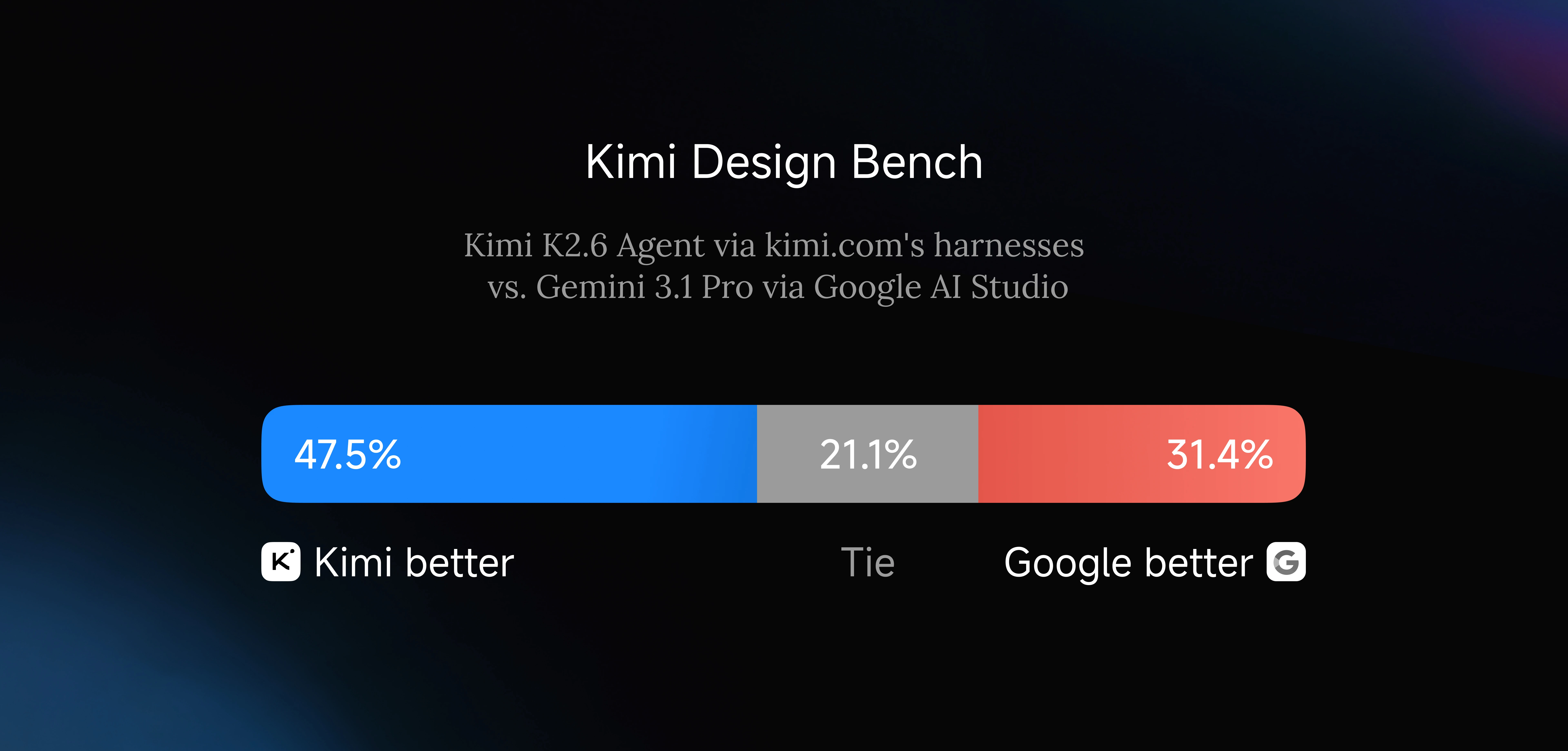
One surprising thing in the K2.6 launch: Moonshot explicitly benchmarks design output, not just code output. Kimi Design Bench evaluates the model's ability to generate full-stack visual prototypes — landing pages, dashboards, product mockups — and compares them head-to-head against Gemini 3.1 Pro via Google AI Studio. The result: Kimi wins 47.5% of pairings, ties 21.1%, loses 31.4%.
The timing here is not coincidental. Anthropic shipped Claude Design on April 17, three days before K2.6. Moonshot is signaling that coding-driven design is now a first-class capability for frontier models, not a vertical feature. Expect every major lab to have a comparable offering within a release cycle.
For teams evaluating the broader category, our coverage of AI agents redefining slides covers the related shift in presentation-generation tooling — and why prompt-to-design and document-to-design solve different problems.
Pricing, Licensing, and Availability
Three things to know about how K2.6 is packaged:
- Open weights. K2.6 ships with downloadable weights under Moonshot's license, which is permissive enough for commercial deployment at most teams. Read the exact terms before production use, especially for redistribution scenarios.
- Hosted API at
platform.kimi.ai. Pricing is substantially lower than closed frontier models — partner quotes repeatedly frame it as "SOTA performance at a fraction of the cost." Exact per-token pricing is published in the API docs; the pattern you'll see is roughly 5–10× cheaper than Opus-tier pricing for comparable agentic workloads. - Consumer surfaces. Kimi.com and the Kimi App use K2.6 as the default model, which is the fastest way to kick the tires without an API key.
For self-hosting, the practical consideration is serving infrastructure. An 8-of-384 MoE at 1T total parameters needs multi-GPU inference even at fp8 — Fireworks.ai, Baseten, and Ollama are all running managed endpoints for teams that want K2.6 without building their own serving stack.
Migration Checklist: Moving Workloads to K2.6
If you're evaluating K2.6 for production, treat it as a regression test, not a full migration:
- Identify agentic-heavy workloads. K2.6's gains are concentrated in tool-use and long-horizon tasks. Pure QA or short-context summarization may see smaller deltas.
- Sample 20–50 real tasks from your production trace and replay against K2.6 at equivalent effort levels.
- Measure tool-call reliability, not just accuracy. Long agentic runs fail differently from short ones — track task-completion rates and retry counts, not just final correctness.
- Re-tune prompts for K2.6's tokenizer and instruction-following style. Kilo's note about "creative tendencies" is a real signal — K2.6 benefits from more explicit constraints than some closed models.
- Price the cost savings against integration friction. If K2.6 saves you 5× on inference for workloads at rough parity, that math tilts quickly once you include self-hosting or partner-inference spend.
Who Should Care About Kimi K2.6 Today
Four audiences have immediate reason to try the model:
Teams with heavy agentic-coding workloads and cost pressure. If you're running autonomous coding agents at scale and the inference bill is a line item someone asks about in quarterly reviews, K2.6's cost profile changes the calculus.
Shops building open-source or on-prem AI stacks. K2.6 is the first open-weights model that genuinely competes with closed frontier models on agentic benchmarks. For regulated industries or sovereignty-sensitive deployments, this matters.
Teams already on Ollama, Fireworks, Baseten, or similar inference platforms. Integration is near-trivial — the same endpoint pattern you're using for other open models. See our coverage of SaaS-pocalypse and agentic workflows for context on why this modular model layer is becoming standard.
Long-horizon automation builders. Hermes-style self-improving agent loops, multi-hour data-pipeline repair, 24/7 monitoring-and-remediation agents — K2.6's 13-hour coherence story is the unlock. Our Hermes agent guide walks through the agent-harness side of this pattern.
What Claude, GPT-5, and Gemini Users Should Take Away
If you're deeply embedded in Claude or GPT-5 workflows, the question isn't "should I migrate everything." It's "is K2.6 now good enough to route specific workloads to, for cost or flexibility reasons?"
Three honest reads:
- Opus 4.7 is still the best model on raw frontier tasks. K2.6 matches or beats Opus 4.6 on several benchmarks; Opus 4.7 (released April 16) widens the gap again on pure reasoning. Anthropic's lead on hardest-of-hard tasks is real.
- GPT-5.4 still has the edge on multimodal generalization and some reasoning subsets. K2.6 closes the gap; it doesn't eliminate it.
- K2.6 wins on cost-adjusted agentic throughput. If you're billing time-and-materials on agent runs, or serving agentic workflows to customers, the cost-per-resolved-task math favors K2.6 on the exact task classes where agents spend most of their time.
The production pattern that's emerging: route hardest-of-hard to Opus 4.7 or GPT-5.4, route long-horizon agentic bulk to K2.6, and use smaller models for retrieval and routing. Serious teams rarely bet on a single model family.
Where Kimi K2.6 Does Not Fit
The honest limitations:
- If your workload depends on the model knowing a specific Chinese regulatory or cultural context intimately, K2.6 is strong. If it depends on tight western-enterprise context — specific US legal forms, American cultural references at a fine-grained level — Claude and GPT tend to do better.
- Not all benchmark wins generalize. Moonshot publishes the wins; the losses are harder to find. Run your own evals.
- Weights-available ≠ fully open. Read the license carefully if you plan to fine-tune and redistribute.
- Self-hosting 1T-parameter MoE is nontrivial. Most teams will use managed endpoints.
What Happens Next
Two trajectories are worth watching:
- The open-weights frontier is now within one generation of the closed frontier on agentic benchmarks. That's a qualitative shift — not because K2.6 is "better," but because the gap between "the best model you can deploy in your own VPC" and "the best model period" has collapsed to a small single-digit margin on the tasks most teams actually run.
- Coding-driven design is becoming a required capability. Claude Design shipped three days before K2.6; expect Gemini and GPT equivalents within a quarter. For content teams, this means the prompt-to-prototype category is no longer a vertical product — it's a model-level feature.
If your stack produces visuals, documents, and code from long-form inputs, the tooling layer that sits above the model — routing, orchestration, document ingestion, presentation generation — is where most of the product work happens. K2.6 raises the capability floor at the model layer. Tosea.ai sits at the orchestration layer for document-to-presentation workflows, turning PDFs, research papers, and long-form reports into decks your team can share with stakeholders — a workflow that stays the same whether the underlying agent model is K2.6, Opus 4.7, or GPT-5.4.
For teams actively routing between frontier models today: treat K2.6 as a first-class option for agentic-coding and long-horizon bulk, keep Opus 4.7 or GPT-5.4 for the hardest-of-hard, and re-run your evals every time a new release ships. The model layer is moving fast enough that decisions more than a quarter old are usually stale.
Kimi K2.6 in the AI Presentation Stack
Open-weight models with K2.6's combination of long context and aggressive token pricing change the economics of one specific workflow: bulk slide generation from large document corpora. A research lab generating a poster for every paper in a literature review, a consulting team producing weekly client decks from a rolling set of internal reports, an investment desk turning daily filings into briefing slides — all of these are workloads where the per-token cost of a frontier closed model adds up faster than it appears, and where a self-hosted or competitively-priced API like Moonshot's becomes the path that actually scales.
The catch — and it is the same catch we explored in our zero-hallucination AI slides guide — is that raw capability at the model layer doesn't automatically produce good slides. K2.6 will happily write coherent HTML, but the difference between "coherent HTML" and "an executive-ready deck with traceable citations and consistent visual style" is the orchestration layer above the model. A document-to-PPT workflow has to handle source ingestion, chunking strategy, table and formula preservation, citation back-tracking, and per-slide style consistency — none of which the underlying language model handles on its own.
This is the layer where Tosea.ai fits in. The PDF-to-PowerPoint pipeline can route the per-slide generation step through K2.6 (when cost-per-token is the binding constraint) or through Opus 4.7 / GPT-5.4 (when the source is unusually difficult), without changing anything else in the workflow. For academic teams running on tight budgets, our free trial guide for academics and convert PDF to PowerPoint guide walk through the practical setup. K2.6 raised the ceiling on what's affordable; the orchestration layer is what determines what actually lands in the final deck.
Sources
- Kimi K2.6 official launch blog — Moonshot AI, April 20, 2026
- Moonshot AI releases Kimi-K2.6 model with 1T parameters, attention optimizations — SiliconANGLE
- Moonshot AI Releases Kimi K2.6, Beats Top US Models On Some Benchmarks — OfficeChai
- Kimi K2.6 Has Arrived: An Open-Weight Powerhouse for Agentic Work — Kilo.ai
- Kimi Code K2.6 Preview: What Developers Need to Know — buildfastwithai
- Kimi K2.6 Developer Guide: Benchmarks, API & Agent Swarm — Lushbinary
- Kimi 2.6 Released: 256K Context, Native Video, Beats Claude Opus 4.6 — ofox.ai


