How to Use Qwen3.6-27B: Complete Guide to Alibaba's New Open-Weight Coding Model
A practical guide to Qwen3.6-27B, Alibaba's April 2026 open-weight model. Covers hybrid Gated DeltaNet architecture, 1M context, Apache 2.0 license, agentic coding benchmarks, and deployment.

On April 22, 2026, Alibaba's Qwen team released Qwen3.6-27B, the first dense open-weight model in the Qwen3.6 family. The release matters for two reasons that rarely arrive together. First, the model ships under an Apache 2.0 license — fully downloadable on Hugging Face and ModelScope, with weights you can self-host on a single high-end GPU. Second, on a series of agentic coding benchmarks, this 27-billion-parameter dense model edges past the much larger 397-billion-parameter Qwen3.5 mixture-of-experts (MoE) model from earlier this year, and matches Claude 4.5 Opus on Terminal-Bench 2.0.
For teams who have spent the last twelve months waiting for an open model that actually works inside an IDE — not just on academic leaderboards — Qwen3.6-27B is the most interesting open release since Kimi K2.6 and Claude Opus 4.7 in mid-April. This guide walks through what it is, what makes it different at the architecture level, how it benchmarks against the field, and how to deploy and use it in production.
![]()
What Is Qwen3.6-27B?
Qwen3.6-27B is a 27-billion-parameter dense Causal Language Model with an integrated Vision Encoder. It is the first dense model in the Qwen3.6 generation — Alibaba had previously shipped a sparse Qwen3.6-35B-A3B mixture-of-experts variant — and it is positioned as the team's open flagship for agentic coding, frontend generation, and tool use.
Three things distinguish it from the dense 27B models we've seen before:
- A hybrid attention layout. Instead of stacking 64 identical self-attention blocks, Qwen3.6-27B uses a repeating pattern that mixes Gated DeltaNet linear attention with traditional Gated Attention. Three out of every four sublayers are linear-attention blocks, dramatically reducing the KV-cache cost on long contexts.
- Native ultra-long context. 262,144 tokens out of the box, extensible to 1,010,000 tokens with YaRN scaling. Most 27B-class models sit at 32K–128K.
- Thinking Preservation. A new chat-template option that retains the model's reasoning traces across turns of a conversation, so the model doesn't have to redo earlier deliberations on every multi-step agent loop.
The model is released under an Apache 2.0 license — same as Kimi K2.6 — meaning commercial use, fine-tuning, and redistribution are all permitted without royalty. Two checkpoints are published: the standard Qwen/Qwen3.6-27B in BF16, and Qwen/Qwen3.6-27B-FP8 quantized to block-size-128 fine-grained FP8, which the team reports as near-identical in quality to the BF16 weights.
Benchmarks: How Qwen3.6-27B Compares
Alibaba's official launch chart compares Qwen3.6-27B against five reference points: its dense predecessor (Qwen3.5-27B), Google's Gemma 4-31B, the sparse Qwen3.6-35B-A3B, the much larger Qwen3.5-397B-A17B MoE, and Anthropic's closed-weight Claude 4.5 Opus.
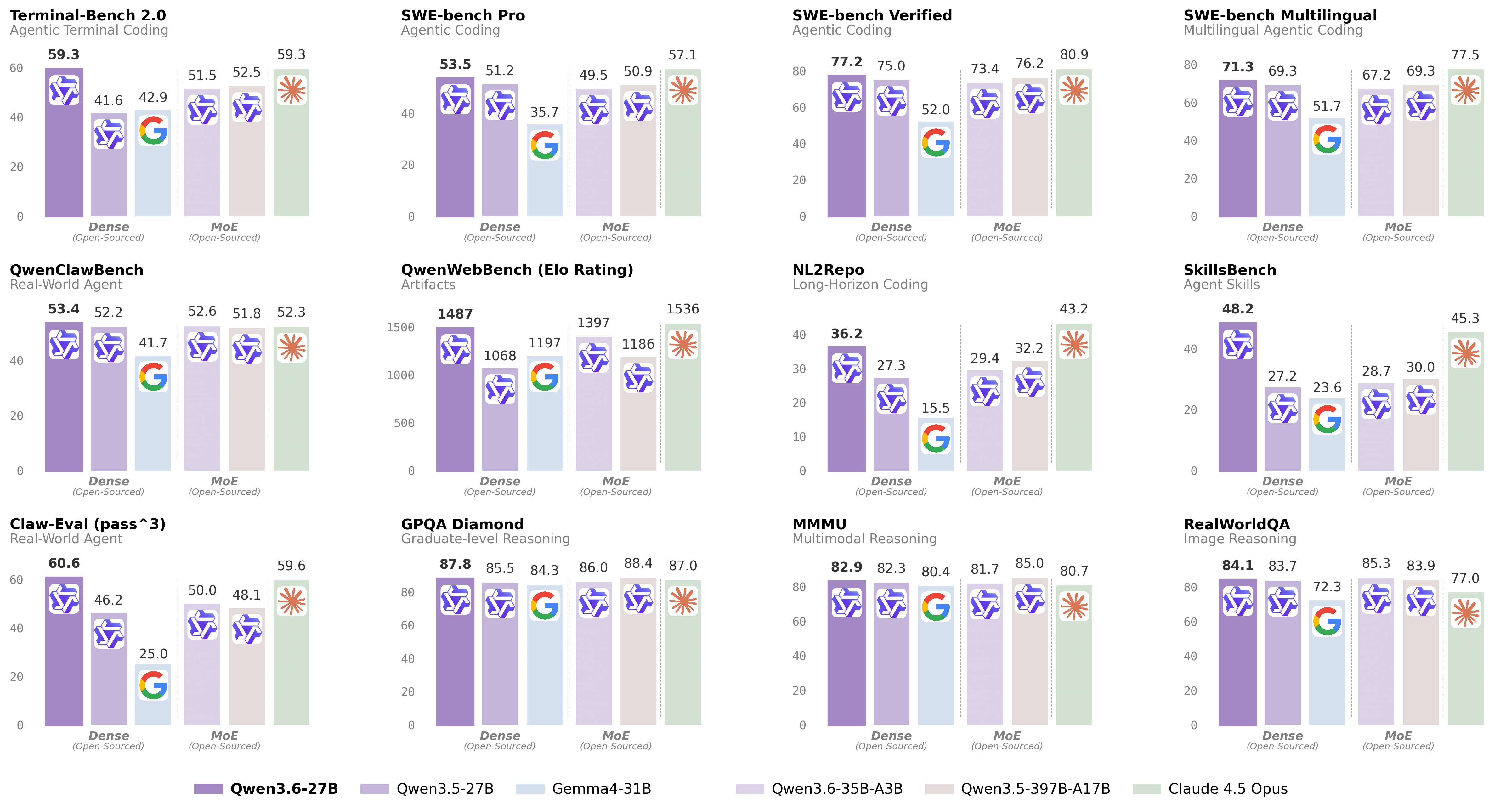
The headline numbers, drawn from the official Qwen blog, tell a consistent story: a 27B dense model that is roughly fifteen times smaller than the 397B MoE outperforms it on every coding benchmark in the chart, and reaches frontier-tier numbers on the reasoning benchmarks too.
Agentic Coding
| Benchmark | Qwen3.6-27B | Qwen3.5-27B | Qwen3.5-397B-A17B (MoE) | Claude 4.5 Opus |
|---|---|---|---|---|
| SWE-bench Verified | 77.2 | 75.0 | 76.2 | 80.9 |
| SWE-bench Pro | 53.5 | 51.2 | 50.9 | 57.1 |
| SWE-bench Multilingual | 71.3 | 69.3 | 76.2 | 77.5 |
| Terminal-Bench 2.0 | 59.3 | 41.6 | 51.5 | 59.3 |
| QwenWebBench (Elo) | 1487 | 1068 | 1397 | 1536 |
| NL2Repo | 36.2 | 27.3 | 29.4 | 43.2 |
| SkillsBench Avg5 | 48.2 | 27.2 | 30.0 | 45.3 |
The Terminal-Bench 2.0 result — 59.3, exactly tied with Claude 4.5 Opus — is the line item that has gotten the most attention. Terminal-Bench measures whether a model can complete real shell-based tasks (file edits, package installs, multi-step debugging) inside a sandboxed terminal, and a tied score against a frontier closed model is unusual for an open 27B.
Reasoning and Knowledge
| Benchmark | Qwen3.6-27B | Qwen3.5-27B |
|---|---|---|
| MMLU-Pro | 86.2 | 84.8 |
| C-Eval | 91.4 | 89.7 |
| GPQA Diamond | 87.8 | 85.5 |
| AIME26 | 94.1 | 92.6 |
| LiveCodeBench v6 | 83.9 | 80.7 |
Vision-Language
| Benchmark | Qwen3.6-27B | Qwen3.5-27B |
|---|---|---|
| MMMU | 82.9 | 80.5 |
| MathVista (mini) | 87.4 | 85.5 |
| RefCOCO (avg) | 92.5 | 91.1 |
| VideoMME (with subtitles) | 87.7 | 85.6 |
| AndroidWorld | 70.3 | 64.4 |
Two patterns worth noting. First, the gains over Qwen3.5-27B are most dramatic on benchmarks that exercise long-horizon agency — SkillsBench, NL2Repo, AndroidWorld — which is consistent with the architectural changes the team made. Second, on raw knowledge tasks (MMLU-Pro, C-Eval, GPQA) the improvement is real but modest, suggesting Qwen3.6-27B is better thought of as an agent model with strong reasoning, not a knowledge-recall upgrade.
The Architecture: Why Hybrid Attention Matters
The technical design choice that defines Qwen3.6-27B — and explains how it does this much with 27B dense parameters — is the hybrid Gated DeltaNet plus Gated Attention layout.
A standard 27B transformer (think the original Qwen3.5-27B, or Gemma 3-27B) stacks 64 identical self-attention blocks. Every layer pays the quadratic compute and KV-cache cost of full attention on the full context window. At 256K tokens, the KV cache alone can saturate an 80GB GPU before the model has a chance to think.
Qwen3.6-27B replaces three out of every four self-attention sublayers with Gated DeltaNet, a linear-attention variant that runs in O(n) time and stores a constant-size recurrent state instead of a per-token KV cache. The remaining one-in-four layer is a traditional Gated Attention block — needed for the "global" mixing that linear attention can't do alone. The repeating block looks like this:
16 × [ 3 × (Gated DeltaNet → FFN) → 1 × (Gated Attention → FFN) ]
The intuition: Gated DeltaNet handles the bulk of token-by-token contextualization cheaply, while one full-attention layer per block of four lets information flow globally across the sequence. The team reports this is what makes 262K native context (and YaRN-extended 1M context) practical to serve on a single node — a regime that would be prohibitively expensive on a fully-quadratic 27B model.
Three additional details matter for production:
- Multi-Token Prediction (MTP) is built into the model head, enabling speculative decoding at serve time without a separate draft model. Throughput gains depend on the workload but are typically 1.5–2x on coding tasks.
- The vision encoder is integrated end-to-end, not bolted on as a separate adapter. Image and video inputs go through the same hybrid stack as text, which is why the VideoMME and AndroidWorld scores are competitive with vision-specialized 27B models.
- Two-mode operation from a single checkpoint. The model can run with thinking enabled (chain-of-thought style for reasoning and code) or with thinking disabled for low-latency instruct workloads — toggled per-request via
enable_thinkingin the chat template.
Thinking Preservation: The Quietly Important Feature
The new feature that's easiest to miss in a benchmark table — but that matters most for how this model behaves inside an agent loop — is Thinking Preservation.
In the standard chat template, when a model thinks (produces a <think>...</think> block) and then answers, the next turn typically discards the thinking trace from history. Each new user turn forces the model to reconstruct its reasoning from scratch. For multi-turn agent workflows that's a lot of redundant tokens and wasted KV cache.
Qwen3.6-27B introduces a preserve_thinking flag:
extra_body={
"chat_template_kwargs": {"preserve_thinking": True},
}
With this enabled, the model's reasoning traces persist across turns. In a coding agent that takes ten back-and-forth steps to land a fix, the model can build on its earlier deliberation rather than re-derive it. Alibaba reports significantly reduced redundant token generation and improved KV-cache efficiency in long agent sessions — gains that are real but rarely show up in single-turn benchmarks.
For developers building tools like Claude Code, Hermes Agent, or other multi-step coding assistants, this is the difference between a model that "reasons fresh every turn" and one that "remembers what it was working on." It's a subtle distinction with large practical consequences.
Deployment: Running Qwen3.6-27B
Qwen3.6-27B is supported by all four major open-source serving stacks: SGLang, vLLM, KTransformers, and Hugging Face Transformers. The team recommends SGLang ≥0.5.10 or vLLM ≥0.19.0 for production.
Quick Start with SGLang
python -m sglang.launch_server \
--model-path Qwen/Qwen3.6-27B \
--port 8000 \
--tp-size 8 \
--mem-fraction-static 0.8 \
--context-length 262144 \
--reasoning-parser qwen3
vLLM with Tool Calling Enabled
vllm serve Qwen/Qwen3.6-27B \
--port 8000 \
--tensor-parallel-size 8 \
--max-model-len 262144 \
--reasoning-parser qwen3 \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder
Hardware Footprint
The BF16 checkpoint weighs roughly 54 GB. In practice that means:
- 8x A100 80GB or 8x H100: comfortable serving with full 262K context
- 4x A100 80GB: feasible with reduced context (128K) or FP8 quantization
- 1x H200 141GB: single-GPU serving of the FP8 variant with 32K–64K context
The FP8 variant (Qwen/Qwen3.6-27B-FP8) is the lever most teams reach for first — it cuts the weight footprint roughly in half with minimal quality loss, and is the path Alibaba's own deployment guides recommend for cost-sensitive production.
API Usage Patterns
Standard Chat (Thinking Mode)
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="Qwen/Qwen3.6-27B",
messages=[
{"role": "user", "content": "Write a Python function that finds prime numbers using the Sieve of Eratosthenes."}
],
max_tokens=81920,
temperature=1.0,
top_p=0.95,
presence_penalty=0.0,
extra_body={"top_k": 20},
)
Image Input
The vision encoder accepts standard OpenAI-style image_url payloads:
messages = [{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": "https://example.com/diagram.png"}},
{"type": "text", "text": "Explain what this architecture diagram represents."}
]
}]
Instruct Mode (Thinking Disabled)
For low-latency tasks where you don't want the chain-of-thought overhead:
extra_body={
"top_k": 20,
"chat_template_kwargs": {"enable_thinking": False},
}
Alibaba publishes specific sampling recommendations for each mode. Thinking-mode general tasks: temperature 1.0, top_p 0.95. Thinking-mode precise coding (web dev, refactoring): temperature 0.6. Instruct mode: temperature 0.7, top_p 0.80, presence_penalty 1.5. These are sensible defaults — start with them and tune from there.
Use Cases: Where Qwen3.6-27B Actually Wins
The benchmarks tell us where the model is competitive. Translating that into where it makes sense to actually deploy it is a different question.
1. Self-Hosted Coding Assistant
The strongest case. Qwen3.6-27B with FP8 quantization runs on a single H200 or two A100s, costs nothing per token at inference time after the GPU is paid for, and ships SWE-bench Verified scores within 4 points of Claude 4.5 Opus. For teams with strict data-residency requirements (finance, healthcare, EU public sector) who want a coding agent without sending source code to a US-based API, this is the most practical open option as of April 2026.
2. Agentic Workflows on Long Context
The 262K native context plus Thinking Preservation makes the model unusually well-suited to agents that operate over large codebases. Tasks like "read this 200-file repository and propose a refactor that touches 15 of them" stay inside a single context window without resorting to retrieval tricks.
3. Multimodal Document and UI Understanding
The integrated vision encoder, with strong AndroidWorld (70.3) and MMMU (82.9) scores, makes Qwen3.6-27B competitive for screenshot-driven UI agents and document-understanding pipelines. Combined with the multilingual training data (Chinese and English at parity), it's a reasonable choice for processing scanned forms, technical diagrams, or product documentation in either language.
4. Research and Evaluation Baselines
For research labs and benchmark builders, Qwen3.6-27B is now the most capable Apache-2.0-licensed dense model in its size class. It's the natural new baseline to compare new architectures, fine-tuning recipes, and inference techniques against — replacing both Qwen3.5-27B and the larger MoE variants for compute-equivalent comparisons.
Where It's Less Compelling
For teams already on a Claude or GPT-4-class API contract, the marginal gain from switching to self-hosted Qwen3.6-27B is small unless self-hosting is itself the goal. Closed-frontier models still lead on the hardest benchmarks, and the ops overhead of running 27B with 262K context isn't free.
Qwen3.6-27B vs the April 2026 Field
April 2026 has been the most concentrated month of frontier model releases in recent memory. Putting Qwen3.6-27B in context:
- vs Claude Opus 4.7: Claude wins on raw frontier benchmarks (SWE-bench Verified by ~4 points, SWE-bench Pro by ~4 points) and is dramatically easier to run (no ops). Qwen3.6-27B wins on cost (free weights, self-hostable) and openness (Apache 2.0, full weights).
- vs Kimi K2.6: Kimi K2.6 is a much larger 1T-parameter MoE model with stronger raw scores on some benchmarks but a far heavier deployment footprint. Qwen3.6-27B is the better fit if you're trying to actually run an open model on hardware you own.
- vs Qwen3.6-Max-Preview: Released two days earlier (April 20) by the same team, Qwen3.6-Max-Preview is the closed-weight flagship that took the top spot on six coding/agent benchmarks. The 27B dense model is the open mirror — most of the architecture, none of the API costs.
- vs GPT Image 2: Different category. GPT Image 2 is an image-generation model; Qwen3.6-27B is a coding/reasoning model with vision understanding. They're complements, not competitors.
The clearest mental model: Qwen3.6-27B is to open-source agentic coding what Llama 3 was to open-source chat — a genuinely competitive checkpoint that resets the floor of what teams expect from an open model.
Limitations Worth Knowing
A balanced view of the model means acknowledging where it falls short or carries real-world friction:
- Closed frontier still ahead on hardest tasks. Claude 4.5 Opus and the closed Qwen3.6-Max-Preview both edge out the 27B dense on the most difficult agentic and multilingual coding benchmarks. The gap is small but consistent.
- Operational complexity is real. A 27B model with 262K context isn't something you spin up on a laptop. SGLang or vLLM deployment, GPU monitoring, and autoscaling all need attention.
- Hybrid attention is novel. The Gated DeltaNet + Gated Attention layout is well-documented in research, but Qwen3.6-27B is the first widely-used open production model to use it. Tooling support (profilers, custom kernels, fine-tuning recipes) is still catching up.
- Vision is good, not best-in-class. For pure document or video understanding, dedicated vision-language models in the 70B-class still lead on certain benchmarks. The vision side of Qwen3.6-27B is competitive but not the model's headline strength.
- Safety alignment is lighter than closed models. As is typical for open-weight releases, refusal patterns and harmful-output guardrails are less aggressive than in Claude or GPT. Production deployments should layer in their own moderation.
What Qwen3.6-27B Means for Document-to-Slide Pipelines
The 262K native context (1M extended) is the line item that matters most for AI slide generation. Multi-paper literature reviews, full quarterly reports, complete consulting briefs, dense product documentation — all of them run to 100K+ tokens, and most current AI presentation tools chunk these inputs into smaller windows because the underlying model can't hold them at once. Chunking destroys exactly the property a good slide deck needs: cross-document structure. The argument on slide 12 is supposed to build on the data introduced on slide 4; if the model never saw slides 4 and 12 in the same context, it can't make that connection.
At Tosea.ai, where we convert PDFs and academic documents into HTML presentations, the bottleneck has always been document understanding at long context. Qwen3.6-27B's 262K native context lets us hold an entire literature review in one window without retrieval scaffolding — and the model's agentic-coding strength translates into cleaner HTML slide markup with fewer hallucinated chart labels and citation numbers. We're testing it as the default backend for our long-context outline step, where the model reads across many papers and produces a slide structure that traces concept evolution. For the broader workflow, see our zero-hallucination AI slides guide, PDF to PowerPoint guide, and how to build a massive slide deck in minutes. For executive-deck-specific patterns, our mastering document transformation guide covers the structural decisions that matter most.
Frequently Asked Questions
Is Qwen3.6-27B free to use commercially? Yes. Apache 2.0 license permits commercial use, modification, fine-tuning, and redistribution. There is no royalty obligation and no usage cap.
What hardware do I need to run it? For BF16 with full 262K context, plan on 8x A100 80GB or 8x H100. The FP8 variant runs on smaller setups — a single H200 141GB with reduced context is the minimum sensible production target.
How does Thinking Preservation differ from regular chat history?
Regular chat history retains user and assistant messages but discards the model's internal <think> reasoning blocks. Thinking Preservation keeps the reasoning blocks, so the model doesn't redo earlier deliberation on each new turn.
Can I fine-tune Qwen3.6-27B? Yes. Apache 2.0 covers fine-tuning. Standard tools (PEFT, LoRA, full fine-tune via Hugging Face Transformers) all work. The hybrid attention layout means kernel-level optimizations may need updates if you're using custom training stacks.
Does it support tool calling natively?
Yes. vLLM's --tool-call-parser qwen3_coder enables OpenAI-compatible function calling out of the box. The Qwen-Agent library provides a higher-level integration with MCP servers and custom tools.
Closing Thought
The story of April 2026 in language models has been the convergence of closed and open frontiers. Claude Opus 4.7 and GPT Image 2 push the closed-weight ceiling higher; Kimi K2.6 and Qwen3.6-27B raise the open-weight floor. For most teams, the practical question isn't "open or closed?" but "which combination?" — closed for the highest-stakes single-call work, open for self-hosted agent loops, long-context document workflows, and anything where data-residency or cost dominates the decision.
Qwen3.6-27B's role in that mix is clear. It's the dense open model that finally makes "self-hosted agentic coding" not a downgrade from frontier closed models, but a credible alternative for the workloads where openness is itself a feature.
Sources
- Qwen3.6-27B: Flagship-Level Coding in a 27B Dense Model — Qwen Team, April 22, 2026
- Qwen/Qwen3.6-27B model card — Hugging Face
- Alibaba Qwen Team Releases Qwen3.6-27B: A Dense Open-Weight Model Outperforming 397B MoE on Agentic Coding Benchmarks — MarkTechPost
- Qwen3.6-27B is a 27B dense model that outperforms a 397B on coding benchmarks — Efficienist
- QwenLM/Qwen3.6 GitHub repository — Qwen Team


