How to Use Gemini 3.5 Flash: Complete Guide to Google's Fastest AI Model (2026)
Gemini 3.5 Flash launched at Google I/O 2026. Complete guide to its benchmarks, 4x output speed, agentic coding, Antigravity integration, availability, and what it changes for AI slide generation.

The interesting thing about Gemini 3.5 Flash is not that it is fast. Google's Flash models have always been fast. The interesting thing is what Google is now willing to put behind the "Flash" label. On May 19, 2026, at Google I/O, the company released a model in its cheap, high-throughput tier that beats its own previous flagship — Gemini 3.1 Pro — on coding, agentic, and tool-use benchmarks. A Flash model outscoring last quarter's Pro is a shift in what "the fast, cheap option" means.
This is the first model in the Gemini 3.5 series, and Google was deliberate about the framing: "frontier intelligence with action." Not the smartest model on every reasoning benchmark, but the one built to do things — drive agents, write and verify code, run long-horizon workflows — at a speed and cost that make those things economical at scale. This guide walks through what Gemini 3.5 Flash actually is, where it leads and where it does not, how it fits into Google's broader I/O 2026 story, and what it means if your end goal is turning documents and data into finished presentations.

What Gemini 3.5 Flash Is
Gemini 3.5 Flash is the entry point to Google's Gemini 3.5 generation, announced at Google I/O 2026 and generally available the same day. It sits in the Flash tier — Google's high-throughput, lower-cost model class — but the positioning has changed. Earlier Flash models were "good enough for high-volume tasks." Gemini 3.5 Flash is pitched as a frontier-class agentic and coding model that happens to run at Flash speed.
The byline on the official announcement is worth noting: Koray Kavukcuoglu, Jeff Dean, Oriol Vinyals, and Noam Shazeer. That is a research-leadership signature, not a product-marketing one, and it signals that Google views this as an architecture story rather than an incremental speed bump.
A few things Google did not disclose at launch, and we will not invent them: there is no published per-token price, no stated context-window size, and no announced knowledge cutoff in the launch materials. We will flag where the gaps are rather than fill them with guesses, because for an agentic model the cost and context numbers matter, and "we don't know yet" is the honest answer until Google publishes a model card with those fields.
The Benchmarks: Where Gemini 3.5 Flash Leads and Where It Doesn't
Google published a full evaluation table comparing Gemini 3.5 Flash against Gemini 3 Flash, Gemini 3.1 Pro, Claude Sonnet 4.6, Claude Opus 4.7, and GPT-5.5. The honest reading is that this is a model with a clear shape: dominant on agentic and tool-use work, competitive on multimodal, and middle-of-the-pack on the hardest abstract reasoning and ultra-long-context tasks.
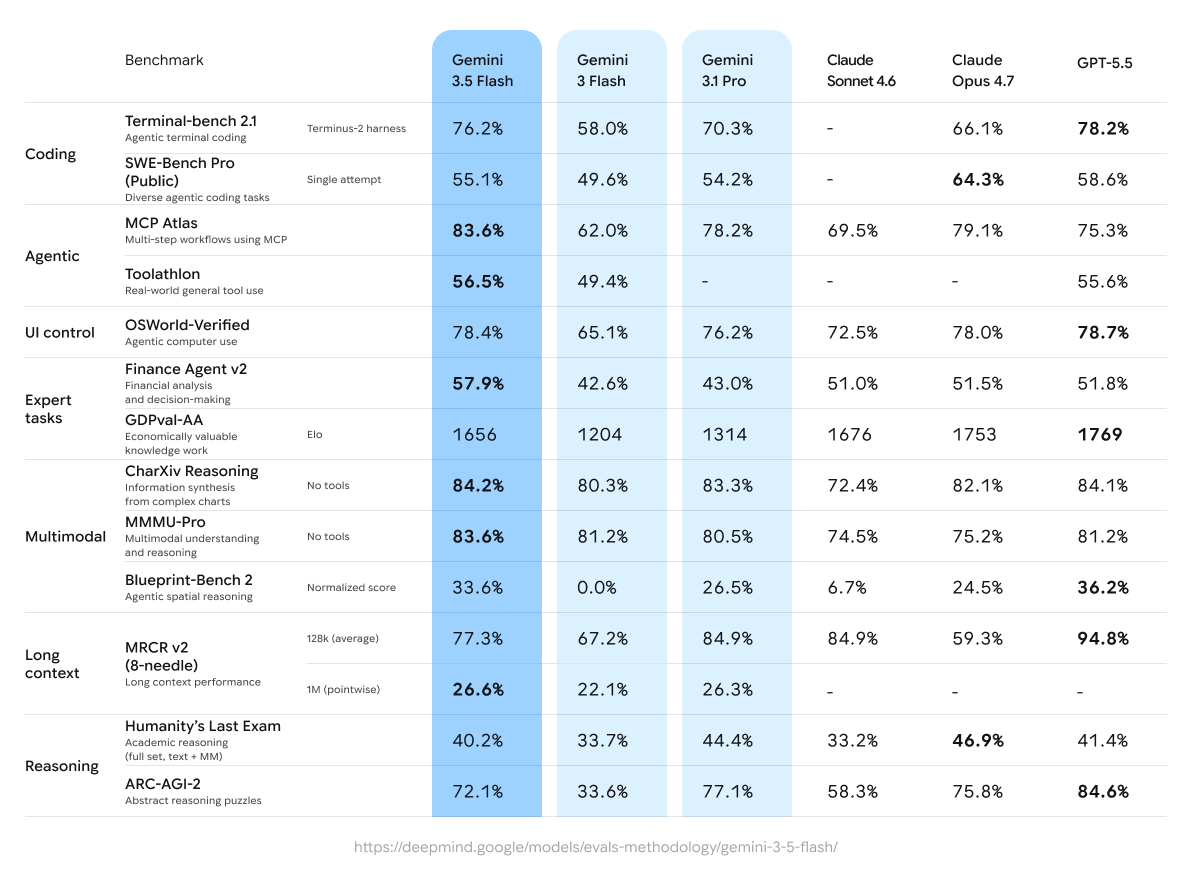
Where Gemini 3.5 Flash clearly leads its peer set:
- MCP Atlas (multi-step workflows using MCP): 83.6% — the best score in the table, ahead of Claude Opus 4.7 (79.1%), Gemini 3.1 Pro (78.2%), and GPT-5.5 (75.3%).
- Toolathlon (real-world general tool use): 56.5% — top of the group.
- Finance Agent v2 (financial analysis and decision-making): 57.9% — ahead of Claude Opus 4.7 (51.5%) and GPT-5.5 (51.8%).
- MMMU-Pro (multimodal understanding): 83.6% and CharXiv Reasoning: 84.2% — both best-in-class for chart and document reasoning.
Where it is strong but not the leader:
- Terminal-bench 2.1 (agentic terminal coding): 76.2% — beats Gemini 3.1 Pro (70.3%) and Claude Opus 4.7 (66.1%), but trails GPT-5.5 (78.2%).
- OSWorld-Verified (agentic computer use): 78.4% — essentially tied with the top tier (GPT-5.5 at 78.7%, Opus at 78.0%).
Where it is honestly mid-pack:
- SWE-Bench Pro (Public): 55.1% — behind Claude Opus 4.7 (64.3%).
- GDPval-AA: 1656 Elo — a large jump over Gemini 3.1 Pro (1314) but still below Claude Opus 4.7 (1753) and GPT-5.5 (1769) on this economically-valuable-work measure.
- Humanity's Last Exam: 40.2% and ARC-AGI-2: 72.1% — solid, but Claude Opus 4.7 and GPT-5.5 lead the hardest reasoning rows.
- Long context is the relative soft spot: MRCR v2 at 128k scores 77.3% versus GPT-5.5's 94.8%. At the 1M-token pointwise test it leads its measured peers at 26.6%, but the absolute number shows ultra-long retrieval is still hard for everyone.
The pattern is consistent: this is a model tuned for acting — orchestrating tools, running multi-step workflows, operating a computer — more than for winning the academic-reasoning leaderboard. For a lot of real production work, that is the more useful trade.
How to read these numbers
A practical caution: every number above is from Google's own published evaluation table, run with Google's chosen harnesses (for example, Terminal-bench 2.1 uses the Terminus-2 harness; SWE-Bench Pro is single-attempt). First-party benchmarks are useful for understanding a model's shape — what it is good and bad at relative to its siblings — but they are not a substitute for independent replication, and harness choices materially move scores. The cross-vendor rows (Claude, GPT-5.5) are Google's measurements of competitors, not those vendors' own reported figures, so read the gaps as directional rather than definitive. The safe conclusion to draw is the qualitative one: Gemini 3.5 Flash is exceptionally strong on tool orchestration and multimodal document reasoning, and average on the hardest abstract reasoning — a profile that independent testing over the following weeks will sharpen, not invert.
The Headline Comparison: A Flash Model That Beats Last Quarter's Pro
The single most quoted chart from the launch is the head-to-head against Gemini 3.1 Pro, because it inverts the usual tier hierarchy.
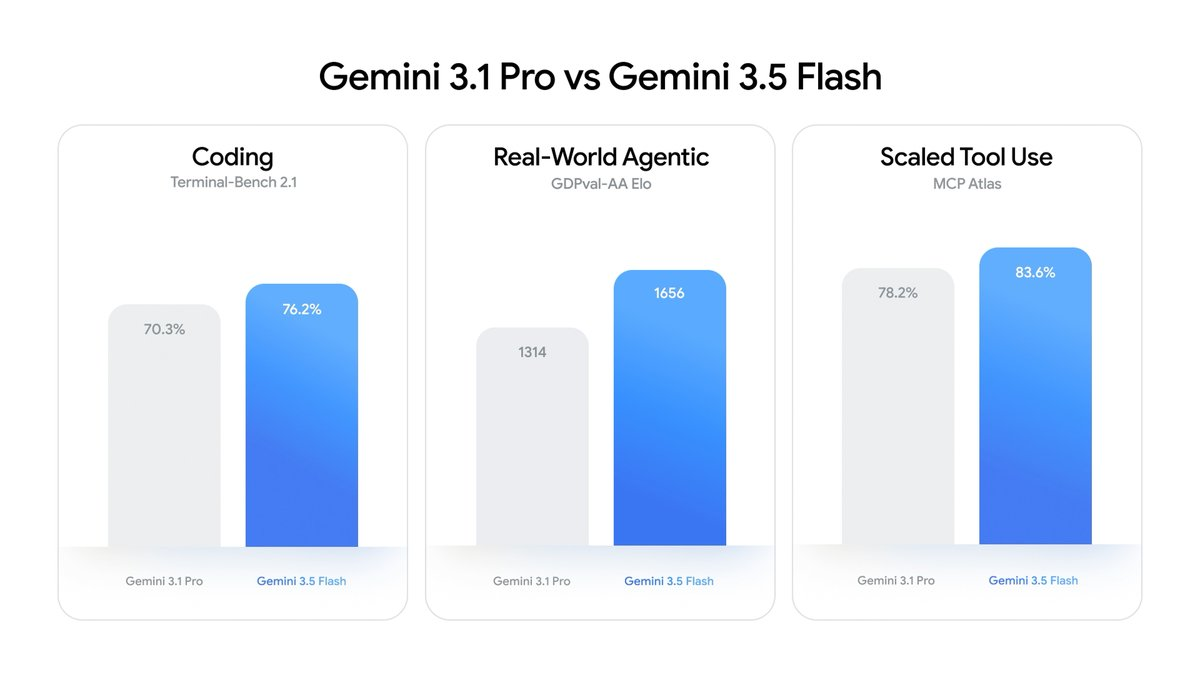
- Coding (Terminal-Bench 2.1): 70.3% → 76.2%
- Real-World Agentic (GDPval-AA Elo): 1314 → 1656
- Scaled Tool Use (MCP Atlas): 78.2% → 83.6%
In every one of those categories the new Flash model outperforms the previous-generation Pro model. Google's own framing is that tasks "that used to take developers days or auditors weeks" can now run "in a fraction of the time," at a cost it describes as "less than half" of competing frontier models. The strategic message is blunt: the cheap tier is now good enough for work that previously demanded the expensive tier.
Speed: The 4x Number
Google's headline performance claim is that Gemini 3.5 Flash is roughly 4x faster in output tokens per second than other frontier models. The supporting data comes from Artificial Analysis (as of May 13, 2026):
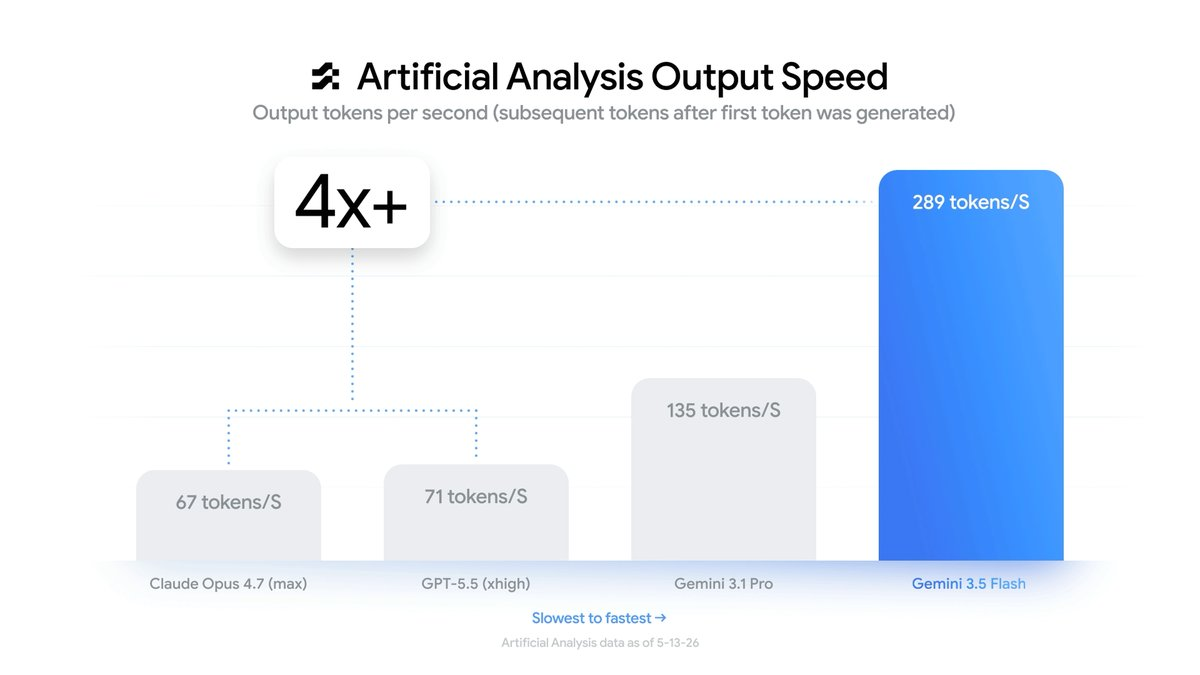
- Gemini 3.5 Flash: 289 tokens/sec
- Gemini 3.1 Pro: 135 tokens/sec
- GPT-5.5 (xhigh): 71 tokens/sec
- Claude Opus 4.7 (max): 67 tokens/sec
For interactive chat the difference between 67 and 289 tokens per second is "noticeable." For agentic workloads it is structural. An agent that plans, calls tools, reads results, and re-plans across dozens of steps spends most of its wall-clock time generating tokens. Quadrupling generation throughput compresses a multi-minute agent run into something closer to real time — and it changes the economics of running many agents in parallel, which is exactly the workload Google is targeting.
Agentic by Design: The Antigravity Connection
Gemini 3.5 Flash was not built in isolation from a product. According to Google, the model was co-developed using Google Antigravity, the company's agent-first development platform — and the Antigravity 2.0 release at I/O 2026 is now powered by Gemini 3.5 Flash.
The relevant capability is dynamic subagents: Antigravity can spin up custom subagent workflows that run in parallel, each instance backed by a fast, cheap, tool-fluent model. This is the use case the speed and cost numbers exist to serve. A single slow expensive model is fine for one hard question. Fleets of coordinated agents — one reading the codebase, one writing tests, one running the terminal, one verifying output — only become practical when each agent is fast and cheap. Gemini 3.5 Flash's top MCP Atlas and Toolathlon scores are the same story from the benchmark side: it is built to be the workhorse inside an orchestration layer, not the soloist.
If you want the wider context on Antigravity 2.0, the new desktop app, the Antigravity CLI, and how Google is consolidating its developer tooling around it, we cover that in the Google I/O 2026 announcements recap.
Where You Can Use It Today
As of launch, Gemini 3.5 Flash is available across Google's surfaces on day one:
| Surface | What it's for |
|---|---|
| Gemini app | Consumer chat, default fast model |
| AI Mode in Google Search | Powers generative UI and conversational search |
| Google Antigravity | Agent-first development, parallel subagents |
| Gemini API via Google AI Studio | Developer API access and prototyping |
| Gemini API via Android Studio | On-device-adjacent and mobile app development |
| Gemini Enterprise Agent Platform | Building and governing enterprise agents |
| Gemini Enterprise | Packaged enterprise deployment |
For developers, the practical entry point is the Gemini API through Google AI Studio. For teams already inside Google Workspace or Gemini Enterprise, the model arrives in the tools you already use, with no migration.
Gemini 3.5 Pro Is Still Coming
Gemini 3.5 Flash is the first model in the 3.5 series, not the only one. Google confirmed that Gemini 3.5 Pro exists, is being used internally, and is planned for a rollout the following month — June 2026. Pro is expected to lead Flash on deep reasoning and the hardest high-context tasks, which lines up with where Flash is currently mid-pack (Humanity's Last Exam, ARC-AGI-2, long-context retrieval). There was no Gemini 3.5 "Deep Think" variant announced at I/O 2026; if you see that claim, treat it as speculation until Google says otherwise.
The takeaway: Flash is the volume and agent model; Pro will be the heavy-reasoning model. For most production automation, Flash is the one you will reach for, and you will escalate to Pro for the genuinely hard analytical step.
Safety and Responsibility
Google states that Gemini 3.5 Flash was developed under its Frontier Safety Framework, with strengthened cyber and CBRN safeguards and advanced interpretability tooling for monitoring model reasoning. As with all such disclosures, the right posture is neither dismissal nor blind trust — these are the controls Google says it applied, and independent evaluation over the coming weeks will fill in the picture. For an agentic model that can operate a terminal and a browser, the safety surface is broader than for a chat model, which makes the interpretability work the more interesting line in the announcement.
How Gemini 3.5 Flash Compares to the Field
If you are choosing a model for an agentic or automation workload in mid-2026, the rough map looks like this:
- Raw reasoning ceiling: Claude Opus 4.7 and GPT-5.5 still lead the hardest reasoning and SWE-Bench-style rows. If your bottleneck is a single very hard analytical step, those remain strong choices. See our Claude Opus 4.7 guide and GPT-5.5 guide for the detail.
- Tool use and orchestration at scale: Gemini 3.5 Flash leads MCP Atlas and Toolathlon outright, at a fraction of the latency and cost. For multi-agent pipelines this is the new default.
- Open-weight alternative: if you need to self-host, models like Kimi K2.6 and Qwen 3.6 remain the comparison points; Gemini 3.5 Flash is API-only.
No single model wins every row, and the most honest summary is that Gemini 3.5 Flash changes the price-performance frontier for agentic work specifically — not that it is "the best model" in the abstract.
Who Should Pay Attention to Gemini 3.5 Flash
Not every team needs to react to a model launch. This one matters most for four groups.
Developers building agentic systems. If you are orchestrating multi-step pipelines — tool calls, MCP servers, parallel subagents — Gemini 3.5 Flash's top MCP Atlas and Toolathlon scores plus its 4x throughput change your unit economics directly. The model you previously reserved for the "smart" step can now run on every step.
Teams running document or data-heavy automation. Financial analysis, audit, research synthesis, report generation: the Finance Agent v2 lead (57.9%) and best-in-class chart reasoning are aimed squarely at workflows where the input is a dense document, not a clean prompt.
Cost-sensitive products at volume. Anyone running an AI feature where per-request cost is the constraint — chat assistants, batch processing, high-traffic consumer apps — gets a frontier-adjacent model at well under half the price of the leading frontier tier.
Anyone shipping document-to-deck or document-to-output pipelines. Which leads to the section most relevant to readers of this blog.
What Gemini 3.5 Flash Means for AI Slide Generation
A frontier-class model in the cheap, fast tier is not just a developer story — it directly changes the economics of turning documents into decks. Building a presentation from a source document is a multi-step agentic task: read and segment the source, decide the narrative arc, allocate content per slide, generate clean layout markup, and verify nothing was hallucinated or dropped. That is exactly the MCP-Atlas-and-Toolathlon shaped workload Gemini 3.5 Flash is tuned for.
Three of its specific strengths map onto document-to-PPT workflows. First, strong agentic coding plus 289 tokens/sec means a deck's underlying HTML or slide markup can be generated and revised in close to real time — the difference between waiting for a 60-slide deck and watching it assemble. Second, best-in-class chart and document reasoning (MMMU-Pro 83.6%, CharXiv 84.2%) is the capability that actually matters when your input is a dense research PDF or a financial report full of tables; the model has to read the chart, not just the caption. Third, "less than half the cost" of competing frontier models is what makes bulk slide generation across a large deck economical instead of a budget line.
The relative weakness — ultra-long-context retrieval — is also instructive for slide work. A 300-page report does not fit cleanly into a single context window for any model, which is why a structured document-to-slides pipeline that chunks, outlines, and verifies still outperforms "paste everything and hope." That orchestration layer is exactly what Tosea.ai provides — it sits above the raw model, turning a PDF or report into a structured, source-faithful slide deck rather than a single best-effort generation. A fast, cheap, tool-fluent model does not remove the need for the zero-hallucination, source-grounded workflow on top; it makes that workflow cheaper and quicker to run underneath.
How to use Gemini 3.5 Flash for presentations today
You do not need API access or Antigravity to put Gemini 3.5 Flash to work on a deck. Tosea.ai has already integrated Gemini 3.5 Flash into its document-to-PPT pipeline, so the model's strengths described above — agentic generation speed, chart-and-document reasoning, low per-deck cost — are available directly in a slide workflow:
- Upload the source document — a research paper, financial report, or long PDF. The pipeline segments it rather than dumping it into one prompt, which sidesteps the long-context weakness covered earlier.
- Let the agentic step build the outline. This is the MCP-Atlas-shaped work Gemini 3.5 Flash leads: deciding the narrative arc and allocating content per slide.
- Generate the deck. The model's ~289 tokens/sec output is what makes a 40–60 slide deck assemble in a usable timeframe instead of a long wait, with clean HTML slide markup rather than a flattened image.
- Verify against the source. The fidelity check stays in place — the value of source-grounding does not change just because the model got faster.
The practical takeaway: the same capability shift that makes Gemini 3.5 Flash interesting to developers is already usable for document-to-PowerPoint work, no integration effort required. For the architectural detail underneath modern AI decks, see our breakdown of HTML vs image-based slide generation.
The Bottom Line
Gemini 3.5 Flash is the clearest signal yet that the "fast, cheap" tier and the "frontier" tier are merging for agentic work. It does not top every benchmark — Claude Opus 4.7 and GPT-5.5 still lead the hardest reasoning rows, and long-context retrieval remains a weak spot — but it leads tool use and orchestration outright, at roughly 4x the speed and under half the cost of its frontier peers. For anyone building agents, automation, or document-to-deck pipelines, that combination is more useful than another point of GPQA. Gemini 3.5 Pro arrives next month for the heavy-reasoning jobs; until then, Flash is the model that makes running many agents in parallel actually affordable.
Sources
- Gemini 3.5: frontier intelligence with action — Google, May 19, 2026
- Gemini 3.5 Flash evaluation methodology — Google DeepMind
- Build with Google Antigravity, our new agentic development platform — Google Developers Blog
- Google launches Antigravity 2.0 with an updated desktop app and CLI tool — TechCrunch
- Artificial Analysis — model output speed leaderboard — Artificial Analysis (data as of May 13, 2026)


